분산 추적
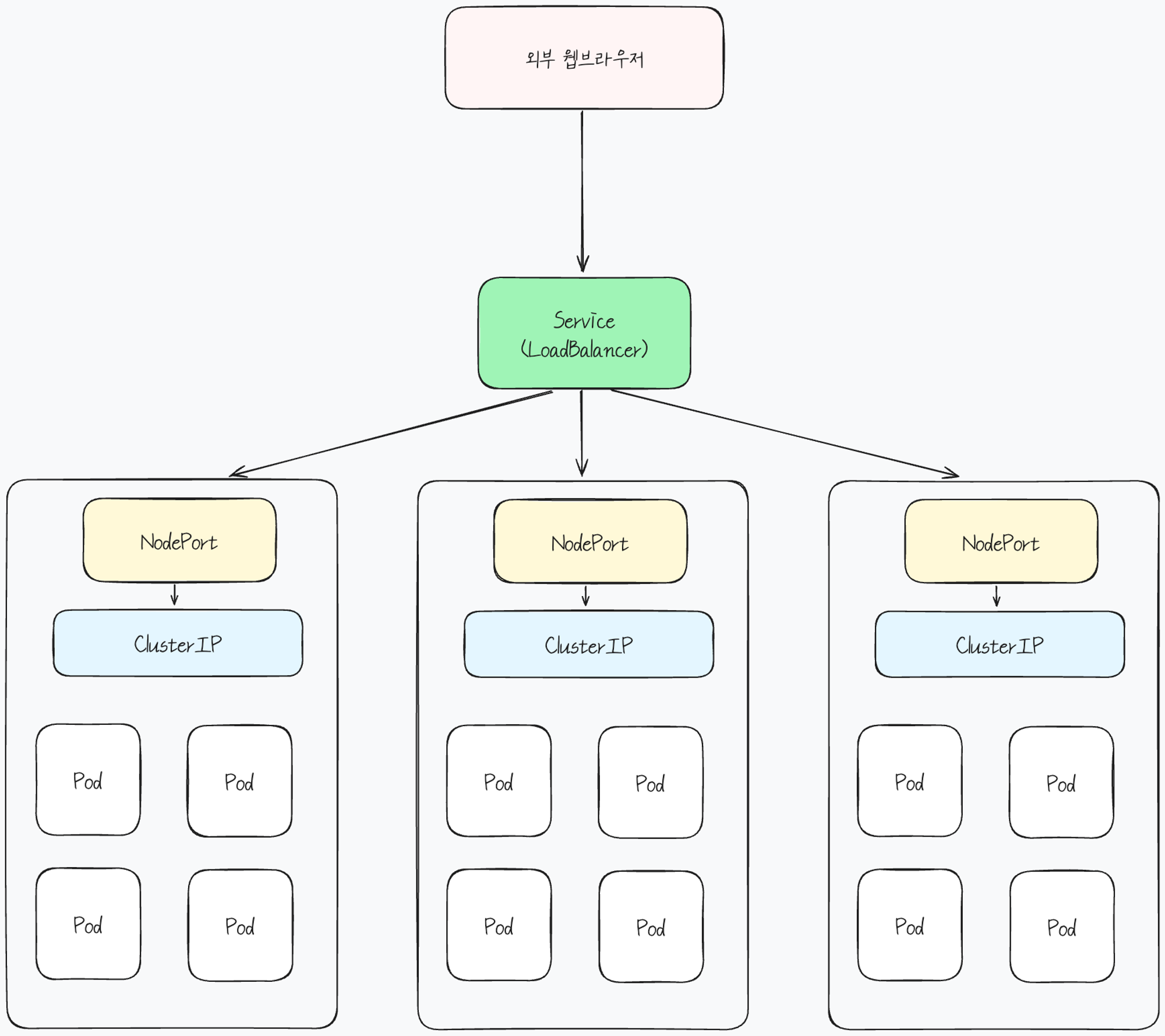
마이크로서비스 아키텍처를 도입하게 되면 하나의 트랜잭션이 여러 서버들이 협력하여 동작하기 때문에 시스템에서 각 요청의 흐름을 추적하고 시각화할 필요가 있습니다.
분산 추적(Distributed Tracing)은 마이크로서비스 아키텍처와 같이 여러 서비스가 협력하여 동작하는 시스템에서 각 요청의 흐름을 추적하고 시각화하는 방법입니다.
Zipkin
분산 추적은 Distributed Tracing이라고 하는데 그 중 OpenTracing이 애플리케이션 간 분산 추적을 위한 표준입니다.
그리고 OpenTracing 인터페이스를 구현한 구현체로는 유명한 것은 Zipkin과 Jaeger가 있습니다. 그 중 Zipkin은 Spring 프레임워크와 쉽게 연동할 수 있어 선택하게 되었습니다.
Zipkin은 다양한 언어에 대한 라이프러리를 제공하는데 Java는 Brave라는 라이브러리를 사용가능합니다.
OpenTracing에서 표준으로 사용하고, Zipkin에서 알아야 할 2가지 용어가 있습니다. Trace와 Span입니다.
Trace는 하나의 트랜잭션에서 전부 동일한 ID이고, Span은 작업 단위로 Trace ID 하나에 여러 개의 Span ID가 있다고 생각하면 됩니다.
- Trace (트레이스): 시스템 전체에서 하나의 요청이 흐르는 경로를 의미합니다. 각 트레이스는 여러 스팬(Span)으로 구성됩니다.
- Span (스팬): 하나의 작업 단위를 나타내며, 시작과 끝, 작업에 대한 메타데이터를 포함합니다. 예를 들어, 특정 서비스 내의 함수 호출이나 DB 접근이 하나의 스팬이 될 수 있습니다.
Spring Cloud Sleuth
Spring Cloud Sleuth는 Spring Boot 의존성으로 Zipkin을 활용할 수 있는 라이브러리입니다.
Spring Cloud Sleuth는 추적 정보를 수집하고, 이 정보를 Zipkin과 같은 분산 추적 시스템으로 전달하는 역할 Sleuth는 Spring 애플리케이션에서 발생하는 각 요청과 서비스 간 호출에 대해 자동으로 Trace ID와 Span ID를 추가하고 관리하고 Zipkin과의 통합 기능도 제공할 수 있습니다.
OpenTracing, Zipkin, Spring Cloud Sleuth의 관계
OpenTracing은 인터페이스, Zipkin은 OpenTracing을 구현한 구현체, Spring Cloud Sleuth은 OpenTracing을 Spring Boot에서 쉽게 사용하기 위한 라이브러리
예를 들어, JPA와 Hibernate에 비유하자면 Open Tracing이 인터페이스인 JPA이고 Zipkin Brave가 실제 JPA를 구현한 Hibernate라고 생각할 수 있습니다. 그리고 Spring Cloud Sleuth는 Spring Data JPA와 유사하다고 말할 수 있다습니다.
- OpenTracing ≈ JPA
- Zipkin ≈ Hibernate
- Spring Cloud Sleuth ≈ Spring Data JPA
사용하기
- Service의 yaml에 설정값 추가
management:
tracing:
sampling:
probability: 1.0
propagation:
consume: B3
produce: B3_MULTI
zipkin:
tracing:
endpoint: "http://localhost:9411/api/v2/spans"의존성 추가(gradle)
// spring cloud zipkin implementation 'io.zipkin.reporter2:zipkin-reporter-brave' implementation 'org.springframework.boot:spring-boot-starter-actuator' implementation 'io.micrometer:micrometer-tracing-bridge-brave'Zipkin 실행 (Docker)
docker run -d -p 9411:9411 openzipkin/zipkin4. Zipkin 실행 (http://localhost:9411)

실행결과
1. 서비스 로그 확인
- 유저 서비스 로그를 확인하면 request가 발생할 때, [user-service] [nio ] [${Trace ID} - ${Span ID}] 를 확인할 수 있습니다.
- 해당 Trace ID와 Span ID로 Zipkin에서 검색할 수 있습니다.
2. Postman에서 테스트(Gateway로 유저 로그인 요청 뒤 결과 확인)
http://localhost:8000/user-service/user/login
하나의 TraceID를 가지고 apigateway, Spring Security, user-service로 단계별로 요청된 것을 확인할 수 있습니다. 각각의 요청은 서로다른 SpaceID를 가지고 있습니다.
(오른쪽 상단에서 TraceID로 검색도 할 수 있습니다. )
마치며
현재는 하나의 서비스에서 테스트를 해보았지만 이후에 메시지 큐를 사용하고 여러 서비스에 흐름을 파악할 수 있게 구현해보겠습니다. 또, Grafana와 같은 모니터링 툴을 사용하여 UI도 개선하여 적용해보겠습니다.