주의깊게 봐야할 부분은 buffer를 활용하는 부분인데, 이 코드에서 buffer n개를 모두 사용하지 못한다. cell의 n-1개만 사용한다는 뜻인데, cell 하나는 채울 수가 없다. 이유는 index의 in과 out이 같은 것을 empty로 간주하기 때문에 마지막까지 사용하면 full인지 empty인지 구분할 수가 없게 된다.
→ in +1== out 일 때 full이라고 생각하기 때문에
( 컴파일할 때, n을 작게 하면 한 cell이 채워지지 않는다는 것을 알 수 있다. )
n개의 cell을 다 채울려면 어떻게 해야할까? in이나 out으로 full이나 empty를 판단하는 것이 아니라, 버퍼 안의 데이터의 개수를 셈으로써 full이냐 empty이냐를 알도록 하면 된다. 그렇게 하기 위해서는 변수가 필요하다. (아래에서는 공유변수 counter를 사용한다.)
개수를 다루는 변수로 counter를 사용하는데, counter는 전역변수이면서 공유변수 이여야 하는데 쓰레드의 counter 공유 변수 동시 접근 시 문제가 생긴다.
그 문제가 바로 Race Condition이다.
Race Condition
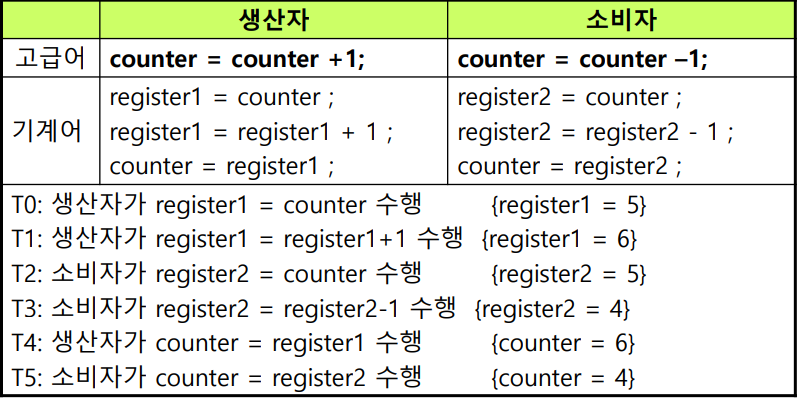
우리가 생각할 때, counter=counter+1이라는 코드가 실행되면 한 번에 딱 실행될거원라고 생각하지만 실제로는 아니다.
이 코드가 기계어로 실행될 때는, 3가지 과정을 거치는데 register에 저장하고 register에서 값을 증가하고 counter에 다시 register에 넣는 단계를 거친다.
counter=counter-1의 경우도 마찬가지이다. 따라서, 공유변수 counter를 두고, 2개의 thread에서 counter값에 접근하면, counter값이 이상하게 변할 수 있다. 위에서 보면 실행 상은 counter가 5여야 하는데, 실제로 기계어로 실행되면 4또는 6이 될 수도 있는 것이다.
이 문제가 Race condtition이다.Race 즉, 서로 다른 쓰레드가 같은 자원을 두고 경쟁하는 상태를 의미한다.
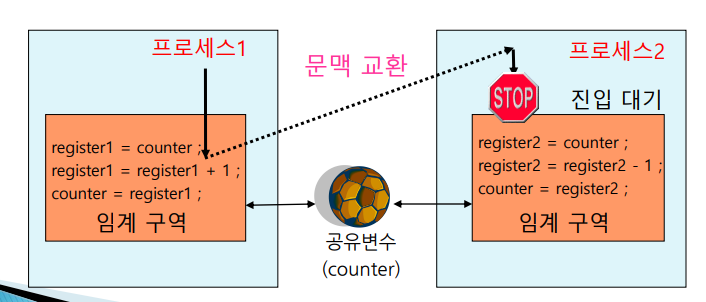
그렇다면 이런 Race condition은 어떠한 방법으로 해결할까? 지금 문제가 되는 것이 기계어가 3줄이니까 3줄이 한번에 돌지 않고 문맥 교환이 일어나서 상대 쓰레드가 들어와서 공유변수의 값을 수정해서 벌어지는 일들이다. 그럼 문맥교환이 일어나더라도 간섭이 없도록 코드가 실행되게 만들면 어떨까?
이 방법이 바로 Atomic한 실행이라고 한다. 예를 들어 counter부분을 임계구역으로 만들어놓으면 생산자에서 코드 2줄까지 실행하고 문맥교환이 일어나서 소비자에서 진입하려고 할 때, 진입하지 못하도록 하고 대기하도록 한다.
원소적(Atomic) 실행
: 공유변수를 통해 상호작용하는 프로세스 혹은 쓰레드 간에 문맥교환이 언제 일어나도 간섭이 없는 실행이 보장되는 것.
-> 공유변수를 사용하는 코드 영역에 임계 구역을 설정한다. 아까 코드에서는 register와 counter를 사용하여서 counter의 값을 증가시키거나 감소시키는 부분을 임계 구역으로 설정하는 것이다.
한 쓰레드가 먼저 임계구역 내에 진입하여 실행 중 문맥 교환이 발생하여 상대 쓰레드에 선점되더라도 그 쓰레드가 임계 구역에 진입하는 것을 허락하지 않고, 대기하도록 한다. 즉, 다른 쓰레드가 실행되더라도 임계구역에는 못들어간다는 의미이다.
임계구역(Critical Section) 설정
임계구역이란 Atomic 실행을 위하여 각 프로세스 혹은 쓰래드가 공유변수, 자료구조, 파일 등을 배타적으로 읽고 쓸 수 있도록 설정한 코드 세그먼트이다.
임계구역 설정하는 것이 비간섭으로 돌게 하는 수단이 된다. (임계 구역의 정의 중요)
→ 공유 변수가 임계 구역처럼 느껴질 수 있겠지만 변수는 수행되는 부분이 아니다. 수행은 코드가 하기 때문에 임계구역은 코드에 만들어 놓는다. 배타적으로 돌도록 코드에 설정해준다.
entry, exit을 설정해 놓음으로써 이 부분은 배타적으로 돌아야한다고 명시한다. enter, exit으로 임계구역을 만들어 놓아야 한다. 화장실을 예시로 든다면, 화장실에 들어갈 때 문을 잠그로, 나갈 때 여는 것과 유사하다.
임계구역을 하면 한쪽이 먼저 들어가게 되겠고, 그렇게 하면 경쟁하는 다른쪽들은 못 들어가고 있다가 먼저 들어간 쪽이 빠져나가면 그제서야 다른 쪽들 중에 하나가 들어가게 됨으로써 진입과 진출이 순서화된다. (Serialize)
이런 것을 동기화라고 한다. 즉, 코드 상으로는 독립적이지만 실행 상황에서 선행제약을 만드는 것이다.
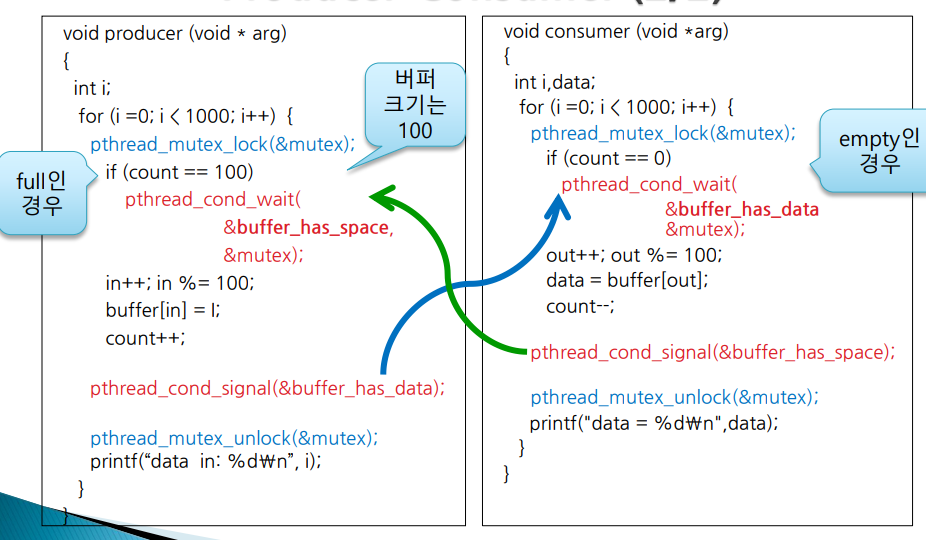
임계 구역 설정은 mutex가 기본이다. lock을 mutex 변수로 선언한다.
위의 코드에서 보면 pthread_mutex_lock으로 잠금을 걸고, 만약 버퍼 크기가 꽉찼으면 pthread_cond_wait으로 대기한다. 그리고 그게 아니라면 in으로 넣고 count값을 증가시켜준 뒤, pthread_cond_signal 함수를 호출한다. 이 함수는 대기 중인 쓰레드에게 signal을 보내 pthread_cond_wait으로 대기중인 쓰레드를 깨우게 되어 다른 쓰레드가 이후의 작업을 진행할 수 있도록 해준다.
- 멀티 프로세싱 혹은 멀티 태스킹(프로세스와 task는 같은 의미) -> 멀티 태스킹을 더 많이 사용함
- 시분할 시스템의 경우 여러
- 하나의 프로그램이 수행 중 여러 개의 프로세스개의 프로세스를 동시에 수행을 만드는 경우도 있음(ex> child)
- 사용자 프로세스와 시스템 프로세스로 나누어짐 - 자원 경쟁 측면에서는 동일
- 사용자 프로세스 - 응용 프로그램이 실행되는 것
- 시스템 프로세스 - 운영체제가 필요에 의해 생성
프로세스의 문맥(context)
- 문맥 : 시분할 시스템에서는 중단과 속개를 반복하게 됨. 중단, 속개 2개의 상태가 있기 때문에 프로세스는 동적인 상태 변화를 하는 객체이다. 프로세스의 모든 실행 정보가 중단될 당시 어디 보호되고 속개될 때 복구되어야 한다. 프로세스의 모든 수행 정보를 문맥이라고 한다. 문맥은 프로세스의 모든 실행 상태를 담고 있기 때문에 간단하지는 않다.
프로세스 문맥의 구성
- 사용자 수준 문맥(User-level context) - 메인 메모리 현재 상태
커널공간이랑 나머지는 프로세스. 한 프로세스가 커널 공간을 제외하면 마치 전체 공간 차지하는 것을 차지하는 것처럼 보인다(가상 메모리이기 때문) 각 프로세스는 가상 메모리 기법 에 의해서 전체 메모리 공간을 사용할 수 있다고 간주하고 넘어가도록 한다.
맨 밑에 text 영역, 그 위에 해당 프로그램에서 선언된 전역변수가 배치되는 부분, 이 광역변수 영역은 data와 bss부분으로 나뉜다. heap은 c에서 malloc으로 동적 메모리 할당 받는 요청이 왔을때 할당하고, free함수가 불리면 회수하는 동적인 곳. runtime시 일어나기 때문에 늘엇다 줄었다 하는 곳이다(힙이 운영된다) 맨 위가 stack인데 stack은 보통 프로그램의 함수가 호출될 때마다 call stack의 자료가 push가 되고 return될때 pop up 된다.
stack에서 다뤄지는 것 중에 지역변수라는 것이 있다. 지역변수는 call stack 내에서 잡히게 되어서 그 함수가 호출될때 stack에 push되고 함수가 return될 때 pop된다.
char g_ch =0 ; 이 부분에서 0으로 선언한 것은 컴파일 시부터 절대 잃어버리면 안되기 때문에 프로그램이 프로세스화 되는 과정에서 메인 메모리가 탑재해주는 그 시점부터 0으로 초기화 시켜줘야 한다.
char g_str[1024]와 int g_int 는 컴파일한 바이너리 코드를 다 잡고 있어야 할 필요가 없다. 초기화 정보가 없는 광역변수가 bss에 해당한다. bss는 속도가 빠르다. - 텍스트 영역 - 프로그램 코드 부분 : 코드는 binaray code를 의미, binary code가 메모리에 탑재된 것을 텍스트 영역
cf> Call Stack 프레임 - 파라미터, 지역변수, return address, frame point가 frame이다. stack에 들어가는 push, pop되는 시스템. Call stack 안에 call stack 프레임이 들어간것.
- 파라미터 : 호출되는 함수의 인자에 assign 되는 값
- 지역변수 : 호출되는 함수 내에서만 생성되는 변수
- return address : 호출되는 함수 종료 시 되돌아가 수행을 계속해 가기 위하여 jump해 가야 할 주소, 함수를 호출한 그 라인의 다음라인이 됨.
- frame point(stack frame pointer) : 스택 상의 프레임 시작 주소, 이 frame이 push가 될 때, 그 전 frame (push되기 전에 top에 있던 프레임)의 frame 시작주소를 여기 기억하고 있다. push 당한 놈의 frame 시작주소를 기억하고 있어야지만 된다.
- 프레임 : 함수호출 시 스택 상에서 운용되는 내용(데이터)
- 프레임 포인터 : 스택 상의 프레임 시작 주소(베이스 주소)
- 프레임의 크기가 함수마다 다르기 때문에 바로 이전 프레임의 프레임 포인터 값을 프레임 내에 간직하고 있어야 함.
Stack Pointer : 콜 스택의 최상위 메모리 주소, stack pointer를 가지고 있어야만 스택 operation을 원할히 할 수 있다. push나 pop같은 것을 수행하기 위해 가지고 있는것. 현재 어디까지 썼는지 stack을. 마지막에 저장된 데이터의 주소.
func1에 10,20을 호출하였을 경우
위에 부분이 main함수의 frame이 된다. main함수의 frame을 보면 frame의 base주소가 있을것이다. 약자로 mfp라고 썼다. main frame의 시작주소를 가리키고 있다. func1이 call일어나면 먼저 파라미터 2개를 push하고 return address를 적고 점프를 한다.
새로 불린 함수 내에서는 ebp(frame pointer)의 값을 copy해서 pop됐을때 다시 복구하기 위한 준비를 한다(mfp값을 caller's frame pointer에 save해두고) ebp에는 현재의 frame base 주소를 ebp에다가 넣어준다. 그리고 지역변수들을 stack에 push된다. stack pointer register는 intel에서는 esp레지스터가 된다. func를 호출하고 나면은 ebp와 esp는 다음을 가리키게 되고 있을 것이고, 나중에 pop up을 하기 위한 대비책으로는 즉 메인 프레임 포인터 값은 mfp에 save해두고 나중에 돌아갈 수 있게 해놓았다.
방금 한것을 assembly 언어로 해석한것
foobar.c -> foo가 불리게 되면 bar(111,222)호출해서 a,b에 assign된다.
main함수가 없어도 compile되어서 생성된 것 볼 수 있다. gcc 컴파일 돌려서 -S하면 assemble 코드가 생성됨.
-m32는 32bit machine assembly code로 생성해달라는 의미이다. 출력해서 나온 파일을 보면, foo에 해당하는 assembly line이 있고 bar에 해당하는 assembly라인이 있다.
foo로부터 bar를 호출하는 부분이 어디냐 하면은 빨간색, movl $222은 esp(stack pointer)가 포인팅하는 곳에다가 222를 move한다는 것은 push하는 것이다. movl $111 %esp도 push를 하는것이다. 그리고나서 call bar를 하면은 instruction ptr을 push하고, foo로 점프를 하는 것이다.
foo로 한 것이 3갱이다. 222 push하고, 111 push하고, instruction ptr값 push하고.
ESP는 stack pointer이고 EBP는 frame pointer이다. frame 내에서의 상대적인 주소들을 적절하게 다루기 위해서 EBP라는 변수를 별도로 두고 있다. 만약에 frame pointer를 따로 쓰지 않는 경우, 특히 frame이라는 개념자체가 없는 경우에는 EBP를 일반 레지스터로 쓸 수 있지만, 일반적으로는 EBP를 사용한다.
instruction ptr은 program counter인데, intel 32bit에서는 EIP(ip가 instruction pointer의 약자이다)레지스터. 프로그램 카운터라고 보면 된다. call을 하면 instruction ptr까지도 push를 하니까 3개가 push가 된것이고, bar로 점프를 하게 되는 것이다.
bar에서는 ebp, 즉 현재까지의 frame pointer register의 값, 그거를 다시 stack에 push를 하는 것이다. 그리고 나서 ebp의 값을 옮기는 것이다. push해서 save했으니까 ebp의 값을 현재 bar의 frame의 base값으로 삼는다. 그리고 나서는 local 변수와 계산들에 대한 operation을 상대적인 주소로 진행한다. (ebp로 operation한다) pop 했을때도 ebp값을 복구해주어야만 돌아가서도 제대로 동작한다는 것이다. ebp값을 save하는 것이 중요하다.
코드상으로는 그렇고 그림으로 그려보면
foo가 돌릴때도 ebp save하는 것이 있었고, bar를 부르기 위해 222,111 push. call이 일어나면 현재의 instruction pointer값을 push하고 3개가 stack에 들어가 있고, ebp값을 copy해서 return됐을 때 복구할 수 있도록 해놓고, 현재의 esp값이 바로 새로운 ebp값이 만들어지는 것이다.
마지막 그림이 call이 이루어진 다음의 상태이다.
- 커널 수준 문맥(Kernel-level context) - 커널이 관리하는 내용
- CPU 내의 각종 특수 레지스터의 내용 : 특수 레지스터의 종류
- 프로그램 카운터(PC) : 다음 수행할 명령어의 주소를 담고 있는 레지스터
- 스택 포인터(SP) : 스택 운영에 필요함
- CPU 상태 레지스터(PSR, Program Status Register) : 예를 들어 모드비트도 상태 레지스터의 한 비트에 해당한다.
// -> 커널이 관리해야 하는 중요한 문맥에 해당한다.
- CPU 내의 각종 범용 레지스터 내용 - 특수 레지스터와 달리 일반 계산용 레지스터가 된다.
- 프로세스의 현재의 각종 자원 사용 정보
- 커널의 프로세스 관리 정보
특수 레지스터에 어떤 것들이 있고, 각각의 역할이 무엇인지 이해하려면 CPU내의 레지스터를 중심으로하는 동작구조를 이해할 필요가 있다.
시작은 먼저 PROGRAM COUNTER(파란색부분)에서 시작해야 한다. CPU는 기본적으로 fetch(가져온다), decode, execute과정을 계속해서 반복하는 것이다. 메인메모리로부터 명령어 하나씩을 순차적으로 읽어오게 된다. 즉, fetch를 하게 된다. 그래서 Program Counter는 다음으로 읽어올 명령어의 주소를 담고 있는 것이 되고, 이 주소를 아래의 Address Buffer에 실으면 어떤 하드웨어적인 동작을 통해서 해당 명령어가 Instruction Register(명령어 레지스터)로 읽혀들어오게 된다. 어디서 읽혀들어오냐면 메인 메모리의 그 주소로 읽혀들어오게 된다. 여기까지가 fetch의 과정이다. 그러면 그 내용을 가지고 decode를 하게 된다. decode는 이 명령어를 해독하는 것이니까 그 다음에는 execute를 시키는 것이다. execute는 옆에 있는 연산 논리 회로(ALU)에 의해서 진행된다. 그러한 과정에서 PC라는 것은 CPU가 이제 다음으로 실행할 명령어의 주소, 즉 다음으로 fetch할 주소를 담고있는 특수 레지스터이다. 만약 방금전에 실행한 명령어가 조건 명령어였고, 그 결과로 특정 명령어로 jump를 해야할 일이 생겼다면 jump해갈 주소를 여기 담게 된다. 결과가 jump할 필요가 없었다면 계속 수행해야될 것이 되니까 조건 명령어의 바로 다음 주소가 Program Counter에 담겨있게 된다. 기본적으로 PC값은 현재 수행한 명령어의 바로 다음 명령어 주소로 자동으로 설정되도록 되어 있다. 그러니까 jump가 멀리 일어나지 않는다면, 자동적으로 그 다음 명령어가 수행되게 된다. 그런데 이게 왜 문맥으로 중요하냐? 시분할 시스템에서 하필이면 어떤 명령어에서 딱 time slice가 소진이 되어서 스케쥴링이 일어났는데, 우선순위가 떨어져서 다른 프로세스에게 그 다음 슬라이스를 주게되었을 경우 그렇게 되면, 현재 돌던 것은 잠시 중지된다. 중지된다는것, 어느 주소까지 수행되고 중지된다 그런 후에 나중에 다시 어떤 조건이 만족되어서 속개된다면 어디서부터 속개되어야 할까? 바로 현재까지 실행되었던 명령어 그 다음 주소의 명령어부터 실행이 되어야 한다. 그래서 그 다음 주소가 어디 담겨있냐하면 Program Counter에 담겨있다. 그래서 이 Program Counter값을 반드시 보존해야지만, 즉, 문맥으로 보존해야지만 시분할 시스템에서 잠시 중단되었다가 속개될때 문제가 없게 된다. 즉, Program Counter가 문맥을 형성하는 중요한 특수 레지스터이다.
그렇게 fetch 해온 데이터를 decode해서 실행하게 되면, 그 결과로 특정한 상태가 발생할 수 있게 되는데, 그러한 상태를 flag register에 반영을 한다. 상태는 다양한 것들이 있는데, 예를 들면 덧셈이나 곱셈을 했는데 캐리가 발생했다던지, 이런것들이 상태에 해당한다. 아까의 process 상태와는 다르게 CPU의 상태를 의미한다. PSR(Program State Register)이라고 하는 상태 레지스터가 있게 되는데, 현재 명령어 실행 후, 상태를 기록하는 것이 기본역할이기도 하지만, 그거 이외에도 decode한 명령어를 수행할 때 조건으로도 작용될 수 있고, 다음 명령어 수행할 때 중요한 정보로 반영되기도 하는 아주 중요한 레지스터이다. 예를 들어 덧셈을 했는데 올림이 생기면 올림이 생겼다는 것을 상태 레지스터에 기록을 해두고, 공교롭게도 덧셈 명령어 수행하고 난 다음에 time slice가 딱 끝나서 다른 process가 잠시 돌았다 그거 돌고 다시 속개될때 올림이 일어났다는 정보를 까먹었다, 어디다 기록하지 않았었다. 그렇게 되면 숫자가 날라가게 된다. 그렇게 되면, 연산에 오류가 생긴다. 상태 자체를 잘 보존해야 한다. 즉 PSR이라는 특수 레지스터의 값이 문맥의 중요한 역할이 된다.
Stack Pointer(SP)가 process 수행 시 call stack에 운영된다고 하는데 이 call stack의 탑에 해당하는 주소를 저장하는데 사용되는 특수 레지스터이다. 이것도 함수 중심의 프로그램을 수행할 때는 굉장히 중요한 역할을 하게 된다. 문맥으로도 따로 관리를 해야하는 부분이다. PC, PSR, SP 레지스터는 시분할 시스템에서 프로세스가 번갈아 가면서 수행될 때, 중단과 속개를 오류없이 반복하기위해서 잘 보존되어야 하는 중요한 레지스터들이 된다.
범용 레지스터들 : 사칙연산이나 논리 연산들을 수행하는 명령어에 사용이 된다. 특히, 그러한 명령어에 operand로 사용되는 계산 목적의 레지스터로서 이 범용 레지스터의 내용도 process가 중단되었다가 속개될때, 잘 보존되었다가 복구되어야만 process가 원할히 돌 수 있다.
사용자 수준의 문맥과 PC, SP, PSR과 어떤 연관관계를 가지고 있을까? 임의 프로세스가 현재 실행되고 있다고 볼 때, Call stack의 탑 주소 관리는 SP 레지스터가 하고, 그리고 text 내에 다음 수행할 명령어의 주소는 PC 레지스터에 담겨있다. 물론 그 명령어가 하나하나 실행되고 난 결과로 생겨나는 CPU의 상태는 PSR에 저장된다. 이렇게 현 프로세스가 진행될 때에는 이러한 특수 레지스터들이 그 수행에 주어진 역할들을 함께 하게 된다. 근데 스케쥴링에 의해서 다른 프로세스가 돌아가기 시작하면 이 값들을 덮어쓰고 만다. 그러면 다시 속개될때 수행에 문제가 생긴다. 따라서 다른 프로세스가 수행을 시작하기 전에 반드시 그 시점의 특수 레지스터 값들을 어딘가에 save해야 된다. 그곳이 바로 PCB이다. 즉, 프로세스 컨트롤 블록이라는 것인데, 그곳에 save를 했다가 다시 속개될때 그곳으로부터 restore를 해야지만 원할하게 돌아가게 된다. 특수 레지스터만 이렇게 PCB를 이용해서 save와 restore를 반복하는 것은 아니다. 범용 레지스터들도 마찬가지이다. (여기 그림에는 안나타냄) PCB가 이러한 레지스터 값들만 보존하는 것일까? 그것은 아니다. 그보다 더 많은 정보들을 담고 있는데, 이에 대해서는 나중에 설명한다.
PC 레지스터와 SP레지스터는 이름 자체가 의미하는 바가 있기 때문에 그 역할을 금방 이해할 수 있다. 그러나 PSR, 즉, Program Status Register 또는 Flag Register는 추가 설명이 필요하다. PSR은 PSW(Program Status Word)라고도 부른다.
예를 보면, Pentium Flag CPU의 경우, 다음과 같은 Flag Register를 갖고 있다.
flag register는 위와 같은 내용을 담고 있다는 것인데, 프로세스의 중단과 속개를 위해서는 반드시 보존되어야하는 주요한 내용인 것이다. 예를 들어, AND 명령어를 수행하고 난 결과가 true이면, ZF 비트가 1이 된것이다. 곧바로 스케쥴링이 되어서 다른 프로세스를 진행시킨 후에 나중에 속개하게 될때 이 flag ZF가 0일지 1일지 보장이 안되면, 만약에 0으로 바뀌어있으면, 속개된 후 프로세스는 엉망이 된다. 따라서, 잘 보존했다가 속개 시에 꼭 리스트화를 하고 속개해야 된다.
ARM 계열의 CPU의 PSR의 사례이다. 여기도 28번에서 31번 bit에 유사한 flag들이 있다. NZCV가 대표적인 4가지 flag이다. 이러한 flag뿐만 아니라 interrupt enable, disable이런 다양한 flag들을 여기에 담고있다. 참고로 ARM process의 경우, processor 수행 모드가 여러가지가 있어서 모드에 따라서 적합하게 작동하도록 아주 정교하게 설계가 되어있다. Fast Interrupt, Trap과 관련된 다양한 모드들이 함께 구분되어 동작되도록 되어있다. 즉, Rest, Data Abort, FIQ... 이러한 여러가지 모드가 있다. 이런 모드로 적절하게 변경을 해가면서 수행이 될 수 있도록 되어있다. 참고로 NZCV(Negative, Zero, Carry, Overflow)의 약자이다. 이런 것들이 상태 플래그가 된다.
문맥교환
- CPU를 다른 프로세스로 넘기는 작업( CPU라는 자원 입장에서 )
- 실행이 정지되는 프로세스의 문맥은 보존되고, 새로 실행되는 프로세스의 문맥이 활성화됨
- 사용자 수준 문맥은 메모리에 남아 있다( 원래 메모리에 있었음 ), 메모리의 현재 상태를 이야기한다. 원래 메모리에 있었기 때문에 그대로 두면 문맥이 보존된다. 커널 수준의 문맥이 문맥 교환에서 중요하다.
- 커널 수준의 문맥 중에서 Program Counter, Stack Pointer, PSR, 범용 레지스터.
- CPU에 있던 레지스터의 내용들은 추후의 복구를 위해 저장(save)되고(왜냐하면 다른 프로세스가 될 때 이 값들을 뭉게버리기 때문에), 스케쥴링된 새로운 프로세스의 문맥이 적재(restore)됨.
- 실행 중단 프로세스의 범용 레지스터와 특수 레지스터 값들을 저장해두고(PCB에 저장한다), 그 다음에 스케쥴링에 의해서 속개될 프로세스 문맥 정보를 그 프로세스 PCB로부터 restore하는 과정을 문맥 교환이라고 한다.
- 그 이외의 커널 수준 문맥, 각종 자원 정보와 프로세스 관리정보들은 어떻게 해야 할까? 그건 PCB에 이미 담겨있기때문에 그대로 두면 보존이 된다.
- 문맥 교환은 프로세스의 중단과 속개를 반복할 때 일어나는 문맥의 보존과 복구의 절차이다.
문맥교환의 시점
- 프로세스가 중단되고 다른 프로세스가 수행되는 경우에 발생한다고 볼 수 있다. 문맥 교환의 시점이라는 것이 프로세스의 상태라는 주제로 넘어가게 되고, 스케쥴링과 PCB에 대한 설명으로도 이어지게 된다.
- 문맥교환이 일어나는 시점은 4가지로 이루어질 수 있는데, ( 스케쥴링, 인터럽트, 입출력 요청, 시그널 대기요청 )
- 첫번째가 시분할 기반의 스케쥴링. 스케쥴링이 일어나는 시점에 문맥교환이 일어날 수 있다. 스케쥴링은 기본적으로 타임 슬라이스가 소진되었을때 스케쥴링이 일어난다.
- 두번째가 인터럽트로 인해 CPU가 선점 당할 때.
- 세번째로 프로세스 스스로가 입출력 요청을 하게 되면, 당연히 다른 프로세스가 CPU를 돌려야 한다. 그 경우 문맥교환이 일어날 수 있다.
- 네번째로 프로세스 스스로가 다른 프로세스가 보낼 시그널에 대한 대기 요청을 하여 CPU를 반납할 때. 즉, 다른 프로세스의 상태 변화를 기다리기 위해서 대기를 해야할 경우 마냥 대기할 수 없으니까 CPU를 반납함으로써 잠시 다른 프로세스가 돌아야되는데 그것을 위해서 문맥교환이 일어난다.
// 문맥, 문맥교환 전부 시분할 시스템이 전제되어 있다.
프로세스의 상태 천이
중단과 속개 2개의 상태보다는 더 복잡하고 다양한 상태가 존재한다. 특히 운영체제의 종류에 따라서 상태들의 종류가 다르다.
프로세스의 상태(영어로 알아두면 좋다.)
생성(new) : 프로세스가 생성된 상태, PCB와 메모리 상의 주소 공간이 마련된 상태.
준비(ready) : CPU의 배정을 기다리는 상태. 큐에 스케쥴링 되기를 기다리는 상태
실행(running) : 프로세스가 CPU에 의해 실행되고 있는 상태. 예를 들어 core가 하나라면 한순간에 돌리는 process는 하나.
대기(blocked) : 프로세스가 어떤 사건(event)이 발생하기를 기다리고 있는 상태 (사건의 예 : 입출력의 완료 또는 시그널의 접수)
종료(terminated) : 프로세스가 종료된 상태
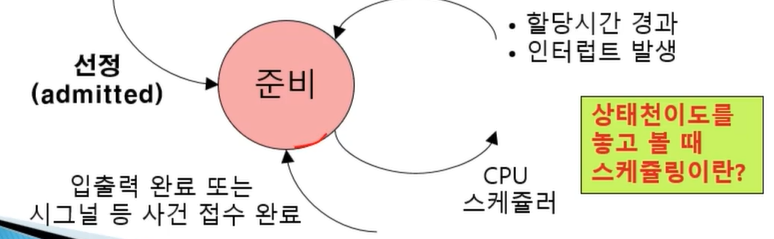
비자발적 문맥교환(할당시간 경과, 인터럽트 발생) 이 경우는 곧바로 준비상태로 처리한다. 사건을 기다리기 위해 block될 이유가 없기 때문이다. 입출력 요청이나 시그널 대기는 대기상태로 천이했다가, 입출력 완료 또는 시그널 접수 되면 준비상태로 천이된다.
실행상태가 되기 위해서는 준비상태를 거쳐서야만 실행상태로 천이될 수 있다. 즉, 스케쥴러에 의해서 CPU가 할당되어야만 실행상태로 가게 된다.
준비상태 : 스케쥴링에 의하여 언제든지 실행이 될 수 있는 상태
여기서 준비 상태를 빠져나가는 화살표는 하나, 그 대상은 실행상태로 가는 경우이다. 즉, 프로세스가 CPU에 의해서 실행되기 위해서는 반드시 준비 상태를 거쳐야 한다. 결국, 준비 리스트(ready list), 준비 큐(ready queue)를 통과해야만 한다는 것이다. 왜 준비 큐만 얘기하지 않고, 준비 리스트라고 하는지? -> 스케쥴러가 큐만 사용하는 것은 아니다. 큐라고 하면 FIFO이 원칙인데, FIFO 원칙만 사용하는 것은 아니기 때문에 혼용해서 부를 수 밖에 없다.
- 준비상태로 천이되어 오는 경우(그림에서 3가지)
1. 프로세스 생성 후, 선정되어 CPU 할당을 대기하고 있게 되거나, (생성상태에서 들어오는 경우)
2. 프로세스가 실행되던 도중에 비자발적인 문맥교환이 일어났거나, (실행상태에서 들어오는 경우, 비자발적 문맥교환)
- CPU의 독점 방지를 위해서 타임 슬라이스 소진 시,
- 또는 인터럽트 발생으로 커널이 CPU를 회수하고 프로세스를 일시 중지시킨 상태
3. 대기하고 있던 입출력 또는 시그널 사건이 완료된 경우(대기 상태에서 들어오는 경우)
- 상태천이도를 놓고 볼 때 스케쥴링이란 준비 상태에 있는 준비리스트 또는 준비 큐에 있는 것을 뭔가의 원칙에 의해서 하나 선택해서 CPU가 수행할 수 있도록 타임슬라이스를 배정해 주는 것.
실행 상태 : CPU가 프로세스를 실행하는 상태
- 실행상태에서 천이되는 경우
1. 실행 상태 -> 준비 상태
실행상태에서 할당시간이 지나고 나면, 회수를 당해서 준비상태로 천이되게 되고, 그렇게 되면 스케쥴링을 통해서 다른 프로세스에 있는 프로세스들과 우선순위 경쟁을 하게 된다.
물론 할당시간이 모두 경과되지 않더라도 입출력 제어기로부터 어떤 인터럽트가 발생했다, 이 프로세스랑 관련이 있는 인터럽트이든, 관련이 없는 인터럽트이든 입출력 제어기로부터 어떤 인터럽트가 발생하면 이때도 역시 준비상태로 천이가 된다. 이렇게 할당시간이 경과되거나 인터럽트 발생하면 비자발적 문맥 교환을 거쳐 준비상태로 천이된다.
2. 실행 상태 -> 대기 상태
: 주어진 할당시간 동안 프로세스를 진행하다보면 두 개의 모드 중에 한 모드에 있게 된다. 사용자 프로그램이 사용자 모드로 수행되다가 시스템 콜을 실행하면 커널 모드로 들어가서 커널 부분을 실행하게 되는데 그러다가 입출력 요청이나 시그널 대기하는 내용을 수행하면 대기 상태로 들어가게 되어있다.
3. 실행 상태 -> 종료 상태 : 퇴출(exit)
대기 상태
대기 상태로 가면 블럭되게 된다. 블럭된 기간 동안은 CPU가 더 이상 프로세스를 수행할 필요가 없어진다. 따라서 CPU를 반납을 하게 되는데, 이렇게 대기 상태로 들어가면 프로세스는 사건별로 구성된 대기 리스트로 이동을 해서 대기를 하게 된다. 그런 후 대기하던 사건이 완료되면, 다시 준비 상태로 천이하게 된다. 사건만 해당하는 것은 아니고 입출력도 해당한다. 대기 상태인 동안 입출력 장치는 입출력을 진행하고 있을 것이고, 어떤 프로세스는 이 프로세스에게 시그널을 보낼 준비를 하고 있을 것이다. CPU는 준비 상태에 있던 프로세스들 중 하나를 스케쥴러를 통해 선택해서 실행시키고 있을 것이다. 대기 상태로 존재한다는 것은 입출려과 CPU가 overlap되어서 동시에 동작할 수 있는 기회를 제공하는 것이다.
PCB(Process Control Block)
문맥, 상태는 과연 어디에 보관되어 있을까? 보관의 실체는 어디일까? PCB라고 하는 것이다.
PCB는 프로세스의 일생 동안 해당 프로세스의 모든 정적 및 동적인 정보를 저장하느 저장소이다. 결국 프로세스의 문맥을 저장하는 자료구조이자 현재 프로세스의 상태, 그리고 메모리나 파일 통신 등 각종 자원 정보가 저장되는 저장소이다.
커널이 프로세스를 관리하기 위한 실체 - 커널은 PCB를 통해 프로세스 관리.
( 리눅스의 경우 PCB에 해당하는 커널 내 자료구조의 이름은 task struct이다 )
- 프로세스 상태 천이도에 있었던 준비 리스트나 대기 리스트는 결국에는 PCB의 포인터의 리스트였던 것이다.
단, PCB라는 자료구조 자체가 리스트들로 이리저리 옮겨다니도록 구현하진 않고, PCB의 포인터가 리스트를 옮겨다닐 것이다. C가 왜 시스템 언어로 적합한지가 이런 이유이다.
- 실행상태 시에 PCB는 준비리스트에 존재하며, 상태표시만 RUNNING 상태로 변경
5가지 상태 중 실행상태가 있었는데 실행상태라는 것은 리스트를 담고있는것이 아니고, 프로세스가 실행된다는 사실이다. 상태 표시만 있는 것이다. 실질적으로 CPU가 프로세스를 돌리는 것이다. 그래서 PCB에 실행상태 즉 RUNNING이라고 상태를 표시하는 것이다. 단, PCB는 그냥 준비리스트에 존재한다. CPU가 프로세스를 타임슬라이스 동안 실행시키는 특수 상태가 실행상태이다.
프로세스 하나마다 커널 내의 자료구조인 PCB가 만들어져서 사실은 커널은 PCB를 관리하는 것이다는 내용이다.
CPU 스케쥴링 정보 : 스케쥴링은 스케쥴링 알고리즘에 의해서 실행되는데 스케쥴링 알고리즘은 각종 정보를 분석해서 최고의 우선순위의 프로세스를 결정해주어야 하기 때문에, 이를 위해서 어딘가 저장해야 되는데 그게 PCB이다.
1은 User Space와 Kernel Space를 제어하는 System call 부분이고, HW Interface가 아래에 있다.
1번 화살표 : 그림은 부팅이 끝나 이미 각종 interrupt에 ISR의 시작주소가 interrupt vector table 또는 interrupt descriptor table인 IDT에 이미 등록되어 있는 상태. IDT가 있고 ISR의 시작주소가 초록색 박스에 쭉 등록되어 있다. 현재 이 상태에서 2층에 있는 응용 프로그램이(여기서는 read(buf) 파란색 박스) 1층에 있는 커널에게 read라는 시스템 콜을 호출하였다. 단 read라는 것은 데이터를 얻어오는 것이다. 사용자 공간내에 이를 위한 버퍼를 미리 잡아두어야한다. 이에 대한 포인트인 buf를 read호출 시 인자로 넣어주었다. 이 호출이 trap을 거쳐 커널내의 정보를 따라서 해당 디바이스 드라이브 내의 실제 구현 함수인 sys_read()까지 다다른 상태라고 보자.
2번 : 디바이스 드라이버 내의 sys_read() 함수는 응용프로그램이 요청하는 데이터를 예를 들어서 하드웨어의 장치제어기로부터 받아와서 잠시 저장하기 위한 용도로 커널 내의 버퍼를 하나 할당받아야 한다. User Space의 메모리 공간하고 Kernel Space의 메모리 공간은 다르기 때문에 장치제어기가 바로 UserSpace의 버퍼에 copy하지는 못한다. 그 전에 kernel이 갖고 있는 space에 copy를 먼저 해놓은 다음에 kernel에 의해서 copy를 해줘야하는 구조이다. kernel내의 버퍼를 만들어 놓고, 그 버퍼를 pointing하는 변수의 이름이 ptr이라는 것이 된다. 그런 후, 2번 레지스터와 같이 장치 제어기의 명령 레지스터에 ptr이라는 값과 함께 하드디스크의 읽기 명령을 기록을 한다. ptr를 넘겨주는 이유는 장치 제어기가 버퍼에 써야하기 때문에 주소도 같이 넘겨주어야 하기 때문에 그렇다. 명령 레지스터에 기록을 한다 라고하였는데 그 이유는 메모리 mapped I/O를 사용하고 있기 때문에 명령 레지스터에 상응하는 메모리 상의 주소에 read라는 시스템 콜에 해당하는 장치 제어기로의 명령 코드를 기록함으로써 명령을 내리기 때문에 그렇다. 명령을 내리는 것은 기록하는 것이다. 그럼 ptr값은 왜 같이 넘겨주었을까? 장치제어기가 DMA를 할 때, 그리로 직접 접근할 수 있도록 시작 주소를 알려놓게 위함. 그럼 이 시점에서 어떤 일이 벌어질까? 명령이 내려갔으니까, 즉 장치제어기가 명령 레지스터를 통해 명령을 받았으니까 곧바로 하드디스크의 해당 블록을 찾아서 읽어오도록 하는 물리적인 동작을 시작시키게 될 것이다. 장치제어기의 물리적인 하드디스크를 동작시키기 시작했다는 소리이다.
상태레지스터는 생략되어있다.
3번 : CPU는 더 이상 할 일이 없으므로 하드디스크 작업이 끝날때까지 기다려야 한다. 여기서 busy waiting으로 기다리면 성능이 떨어질 것이고, 따라서 디바이스 드라이버 상의 코드로 볼 때, 2번 화살표 작업을 수행하고 난 다음에는 3번과 같이 Sleep()을 하게 된다. Sleep함수의 내부에 들어가보면 결국에는 이 프로그램이 Sleep상태로 들어가면서 이제는 CPU가 수행시킬 다른 프로세스를 선정하기 위한 스케쥴링 함수를 불러오게 된다. 그럼 어떻게 될까? 스케쥴함수(Sched())에 의해 선정된 다른 프로세스가 CPU의 문맥교환이라는 것을 통해서 그 다른 프로세스를 수행하게 된다. 그 동안에 이 프로세스는 Sleep()상태에 있고 안 돌고 있는 것이다.
4번 : 그렇게 CPU가 다른 프로세스를 진행하고 있는 동안에 장치 제어기는 하드 디스크를 물리적으로 구동해서 결국 응용프로세스가 read해 오고자 하는 블록을 찾아내서 자료 레지스터로 읽어들일 것이다. 여기서 자료레지스터는 장치 제어기 내의 저장 공간으로 보아도 된다. 이렇게 데이터가 준비가 되면, 2번 작업을 통해 전달받은 ptr 주소값에 해당하는 메인 메모리의 주소로부터 시작해서 그 데이터를 전달하게 된다. 이 전달하는 과정에서 바로 DMA가 사용된다는 것인데, 블록 데이터이기 때문에 블록을 옮기기 위해서 CPU가 간섭할 필요가 없고, 블록 단위로 바로 장치제어기에서 Device Driver의 버퍼로 copy되게 하기 위해서 DMA를 사용한다.
5번 : 4번이 끝나고 나면 device driver내의 버퍼에 해당 자료가 와 있는 상태가 되는 것이다. 이제 device driver가 깨어날 시점이 된 것이다. 그럼 device driver가 ptr저기 다음 라인을 실행 시키게 되는 것이다. 그런데 현재 sleep상태라는 것이다. 그러면 어떻게 속개될 수 있도록 장치제어기가 작동하느냐, 바로 장치 제어기가 DMA 끝났읍니다 하고 interrupt를 CPU에게 걸어준다. interrupt는 다수준 인터럽트로 인터럽트 번호나 masking이 동반되어 결국 IDT에 기록된 해당 디바이스 드라이브 내의 ISR 처리 함수로 jump가 되는 것이다.
6번: 하드웨어의 도움을 받아서 IDT에서 해당 Device Driver내에 위치한 ISR의 시작주소를 알아낼 수가 있고, 그 시작주소를 PC(Program Counter)에 얹으면 해당하는 ISR로 jump하게 된다. 이렇게 호출된 ISR은 interrupt처리에 필요한 작업과 아울러서 궁극적으로 아까 sleep상태로 들어간 프로세스(아까 read프로세스)를 깨우는 작업을 하게 된다.
7번 : 이를 위해서 프로세스를 스케쥴링 queue에 넣게 된다. 이렇게 스케쥴링 queue에 들어가면 시점이 문제이지 언젠가는 프로그램이 속개된다. 결국 sleep상태로 들어간 프로세스가 wake-up되는 것이다. 이렇게 wakeup이 되고나면 시간이 얼마 지났는지 모르지만 결국 device driver코드 상으로 볼 때 아까 3번에서 호출한 sleep함수가 그제서야 return이 되는 것이고, 그 다음 라인을 수행하게 될 것이다. 거기가 바로, ptr 다음 라인부분이 된다.
그럼 sleep전과 sleep후 달라진 것은 무엇일까? : 시간이 얼마나 지났는지는 모르지만 전에는 버퍼에 데이터가 없었는데 sleep후 꺠어나 보니까 버퍼에 데이터가 생긴 것이다.
8번 : 그럼 곧바로 ptr이 포인팅하는 버퍼 내의 데이터를 사용자 공간으로 copy해준다. (커널 공간과 사용자 공간이 부리되어 있기 때문에 그렇게 해야 넘어간다)
9번 : sys_read()함수는 역할을 다했기 때문에 return과정을 거친다. 리턴과정을 거쳐서 응용 프로그램으로 돌아가는 것이다. 그렇게 되면 응용프로그램 입장에서 보면은 read함수가 끝나고 다음라인으로 속개되는 것이다.
CPU와 장치드라이버(I/O device)만 두고 상태변화 보기
CPU는 그림과 같이 2가지 상태를 반복한다. 즉, 사용자 프로세스를 수행하다가 인터럽트가 들어오면 ISR을 수행하다가 두 상태를 번갈아가면서 계속 진행한다.
반면에 I/O 장치는 쉬다가(idle 상태이다가) 입출력 작업을 받아서 입출력 작업 수행(transferring)하다가 두개의 상태를 반복한다.
소프트웨어로 만들어진 커널이 응용 프로그램에 의하여 문제가 발생하는 경우가 생길 수 있다. 어떻게 이를 하드웨어의 도움을 받아서 protect할 수 있는지에 대하여.
보호(Protect) 대상 : 전부를 보호하는 것이 아니라 근원적인 부분 보호함으로써 직간접적으로 보호
불법(Illegal) I/O : 응용 프로그램이 저지를 수 있는 잘못된 입출력에 대한 보호. 특히 장치제어기를 임의로 접근함으로써 시스템이 오작동하는 방법에 대해서 설명. 불법 메모리 접근 : 응용 프로그램이 다른 응용프로그램이나 커널 프로그램이 탑재된 메모리 영역을 임의로 접근하거나 내용을 변경해서는 안된다. 이를 방지하기 위한 방법에 대해서 설명.
무한 루프(Infinite Loop) : 응용 프로그램이 무한 루프를 돌 경우 CPU가 그 루프만 돌리도록 놓아두면 시스템이 마치 정지한 것과 같을 것이다. 무한 루프를 방지하는 방법에 대해서 설명하겠다.
이중모드와 모드비트
이중모드
커널이랑 커널 모드의 차이점?
커널 : 하드웨어에 접근하기 위한 프로그램
커널 모드 : OS의 함수들
사용자 모드 : 사용자 공간 상의 코드만 실행 가능
인터럽트나 입출력 제어와 관련된 특권명령어(privileged instruction) 수행 불가
특권명령어 수행 시도 시 트랩 발생
메모리 참조 영역도 제한
커널 모드 : 커널 공간 상의 코드만 실행 가능하며 특권명령 사용 가능
사용자 프로그램의 시스템 호출(트랩), 인터럽트 처리, 명령어 수행 오류 발생 시 발생하는 트랩 처리
하드웨어적인 제한이나 보호를 수행치 않음 -> 커널 모드로 수행할 코드를 작성할 경우 매우 조심해야한다.
그전에 이러한 보호 방법의 근본적인 수단인 이중모드에 대해서 먼저 설명하도록 하겠다. 방금 전 3가지 보호대상이 있다고 하였는데, 사실 이 세가지 대상말고도 보호대상은 많을 것이다. 하나하나에 대해 방법 강구하는 것은 소모적이다. 그보다는 근본적이고 이를 통해 여러 문제가 해소되는 방법을 찾아야 한다. 그러한 것으로 이중 모드라는 것이 있다. 즉, 이중모드란 커널모드나 사용자 모드를 분리하는 것을 이야기 하는데, 기본적으로 메인메모리를 사용자 프로그램이 탑재한 사용자 프로그램과 커널 프로그램이 탑재된 커널 프로그램으로 나누어서 CPU가 사용자 프로그램을 수행할 때는 사용자 모드로 수행하도록 하고, 커널 공간의 프로그램을 수행하도록 할 때는 반드시 커널 모드로만 수행하도록 하는 것이다. 왜 이렇게 할까?
- 기본적으로 자원 공유 환경에서는 한 응용 프로그램의 오동작이 다른 프로그램의 오동작을 야기시킬 수 있다. 그러한 오동작에는 잘못된 명령어 사용, 타 영역 접근, 임의로 입출력 장치 제어기에 접근 등, 다양한 것들이 있을 수 있다. 이러한 오동작은 결국 CPU가 프로그램, 즉 코드를 수행할 수 밖에 없기 때문에 벌어지는 건데, 그렇다면 코드 중, 커널이나 다른 프로그램의 오동작을 일으킬 소지가 있는 코드는 커널 내에서만 수행하도록 하면 될 것이다. 따라서, 커널의 그러한 코드들을 함수로 만들어 모아놓고, 응용 프로그램은 필요시에 그 함수를 불러서 쓰면 되는 것이다. 문제가 있을만한 코드는 커널내에 집어넣어놓고, 그것을 사용할 떄는 커널모드에서만 수행될 수 있도록 통제를 한다. 모아만 놓고 응용 프로그램들이 아무렇게 불러쓰도록 하면 서로 여전히 간섭이 생겨서 마찬가지로 문제가 되고, 이렇게 모아놓은 것은 별 소용이 없게 된다. 따라서 이러한 커널 내 함수는 CPU로 하여금 별도에 모드인 커널 모드에서만 수행되도록하고, 응용 프로그램이 그 함수를 호출할 필요가 생기면 커널 모드로의 진입을 허가받아서 수행을 하도록 한다. 그것이 바로 이중 모드(dual mode)를 두는 이유인 것이고, 문제가 될 만한 코드는 커널 내에다 놓고, 그것을 응용프로그램은 호출을 통해서, 여기서 호출은 시스템 콜이 되는 것이다. 트랩이라는 시스템 콜을 통해서 커널 모드로 진입해서야만 수행할 수 있도록 하겠다는 것이다.
이중 모드는 어떻게 실현시킬 수 있을까? 코드를 그렇게 모아놓고 커널모드에서만 실행시키는 것은 좋은 아이디어인데 어떻게 실현??? 이를 위해서 CPU내에 특수 레지스터라는 것들이 있는데, 그 특수 레지스터라는 것들 중에 상태 레지스터라는 것이 있다. 상태 레지스에서 1비트를 모드비트(mode bit)로 사용한다. 모드비트가 0이면 커널 모드이고, 1이면 사용자 모드인 것인데 CPU는 이 모드 비트를 보고 커널모드인 경우에만 소위 말하는 특권 명령어(priviledge Instruction)를 수행한다. 특권 명령어는 다양한데, 입출력 명령이라든지 interrupt관련 명령어, 특히 이 모드 비트 자체를 변경시키는 명령어 등이 특권 명령어에 속한다.
시스템 콜이 호출되면 트랩과정을 거치게 되는데 이 과정에서 모드비트가 커널모드인 0으로 설정이 되는 것이다.(이 부분이 중요) 해당 시스템 콜에서 return을 할 때는 모드 비트를 다시 1로 두는 것이다. 그렇게 해서 return을 하고나면, 응용 프로그램에서는 다시 시스템 콜을 하지 않고는 특권 명령어를 사용할 수 없게 되는 것이다.
이러한 이중모드를 잘 사용하면 몇가지 보호 수단을 잘 사용할 수 있다.
Illegal I/O 차단 (불법 I/O 차단)
모든 I/O 관련 명령을 특권명령어로 함 -> 시스템 호출 즉, 트랩을 통해서만 I/O가 가능하도록 해놓으면 된다.
명령어만 방어해서는 안되고 메모리 영역도 방어해야 한다.
메모리의 커널 영역 보호 수단과 함께 사용
인터럽트 처리 루틴(ISR) 및 장치 구동기 영역
시스템 버퍼 영역
인터럽트 벡터 영역
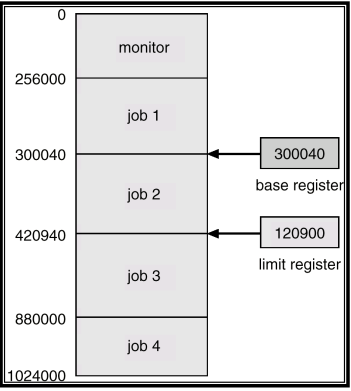
불법 메모리 접근 차단 : 이를 위해 특권 명령어로만 접근할 수 있는 2개의 레지스터를 사용하는 것이다. (Base register와 Limit register)
Base와 Limit 레지스터로 프로그램 공간 정의 - 레지스터의 적재 명령은 커널 모드 명령(특권명령어)
사용자 모드에서 주소 생성시에 범위를 확인, 벗어나면 커널로 트랩함
가상메모리의 경우 메모리 보호가 페이지 단위로 제공됨(맵에 정의된 주소공간 초과 여부를 하드웨어가 차단) ex> UNIX나 LINUX의 경우 "Segmentation Fault"
job2가 메모리 어딘가를 접근하려고 할 때마다 그 대상주소가 이 범위를 벗어나는지를 메모리 관리 유닛이라는 것이 이 두 레지스터를 활용해서 항상 체크하도록 하는 것이다. 그래서 거기서 벗어나게 되면 오류가 발생했고 그 오류가 발생해도 트랩이 걸리는데 오류 발생에 의한 트랩이 걸림으로써 그 오류를 커널이 처리하도록 그렇게 하는 것이다.
가상 메모리의 경우 메모리 보호가 페이지 단위가 되고 이를 보호하기 위한 메커니즘이 하드웨어적으로도 지원이 된다.
Segmentation Fault는 코드에서 포인터를 잘못 사용할 경우, 해당 프로세스에 할당된 메모리 영역을 벗어날 때 발생하는 오류 메시지
Infinite Loop 방지(CPU 보호)
시분할에서는 타이머 인터럽트를 이용하여 타임슬라이스를 구현함으로써 CPU 공유 실형
타이머 또는 클럭으로 하여금 고정된 빈도로 인터럽트를 발생토록 함(예: 1/100초)
타임 슬라이스 실현을 위해 필요한 최고 우선순위 인터럽트 설정, 인터럽트 인터벌 설정 등 모드 특권 명령어로만 수행하도록 함 -> 응용프로그램이 타임슬라이스 인터벌을 악의적으로 수정할 수 없게 되고, 결국 매 타임슬라이스마다 스케쥴링이 이루어짐으로써 무한 루프도는 프로그램만 도는것을 방지
프로그램의 실행 시간을 제야함으로써 한 프로그램의 무한루프 수행(CPU 독점)을 방지
기타 : 몇가지 주제를 두서없이 집고 가겠다
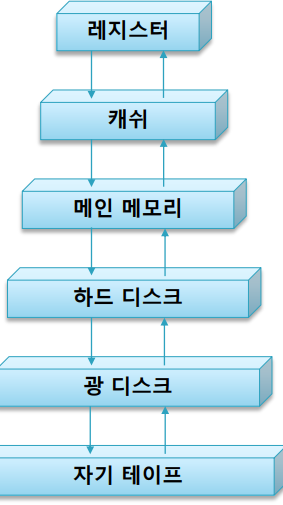
캐시(Cache) : 캐시와 레지스터는 CPU 내에 있고 특히 레지스터는 Core내에 있다. 이 둘은 용량이나 속도면에서 반비례적인 특징이 있다. 레지스터가 가장빠르지만 용량은 제일 적다. 메인 메모리는 용량은 크지만 속도는 느리다. 두 가지 장점을 절충해서 속도도 레지스터에 버금가도록 빠르고 용량도 메인메모리처럼 큰 장치가 있는것같은 착각을 줄 수 있는 방법 -> 캐시가 이것을 위해서 고안됨.
캐시
레지스터와 메모리 사이에 접근시간 또는 데이터 이동속도의 심한 격차가 있을 때에 이의 완화를 위하여 사용
CPU에서 메인메모리에 접근 시에 그 자료를 메모리보다 속도가 빠른 캐시에 복사해놓고 다음번 접근시에 캐시를 방문하여 찾는 자료가 다행히 거기에 있으면 캐시로부터 바로 갖고 가고, 없으면 그때서야 메인메모리에서 가져온다.
CPU가 갖고있는 값이 항상 캐시에 복사되어 있다면 메인메모리의 속도가 캐시만큼 빨라지게 되는 것이고, 용량은 메인메모리의 용량과 다름없어진다.
알고리즘 여부에 따라서는 캐시에서 데이터를 갖고 있을 확률(Hit Ratio)을 90%이상 개선 가능
Hit Ratio가 높아서 100%에 근접할수록 사용하는 효과 극대화 : 가격이 비싸고 용량은 적지만 빠른 속도로 메인메모리의 용량을 사용할 수 있는 효과를 만들어 냄.
캐시 - 메모리 계층구조
-> 개념을 확장하면 시스템 전체의 기억 장치의 성능이 획기적으로 개선될 것이다. 이러한 발상으로 고안된 거시 메모리 계층구조이다. 맨 위에 레지스터, 그리고 메인 메모리 사이에 캐쉬, 그러면 캐쉬와 하드디스크 사이에서 메인 메모리는 캐쉬의 역할을 하지 않을까? 이러한 관점을 확대하서 운영하면 전체적으로 용량은 최하위 기억장치의 용량으로 확대가 되고, 접근 속도는 최상위 기억장치 속도처럼 제공될 수 있다. 그래서 컴퓨터 시스템은 메모리 계층 구조를 갖게 되는 것이다.
부트스트래핑(bootstrapping) : 흔히 부르는 부팅의 풀네임
Bootstrap의 어원적 의미 : 장화 뒤에 고리인데 장화를 신을때 부트스트랩을 혼자 신을 수 있도록 도와주는 것으로 나중에 개념이 확장되어 남의 도움 없이 자기가 스스로 수행한다는 의미. 장화에 달려있다는 점이 중요한데 이래서 운영체제의 관점에서 볼 때 운영체제의 시동을 운영체제 일부 기능이 스스로 수행한다는 과정을 뜻하는 용도.
부팅 시퀀스 - 시스템에 따라 차이가 크겠지만 원론적에서 아래와 같다. : "process of chain loading"
전원이 처음들어오면 메인 메모리에는 아무것도 없다.(volatile memory이기 때문에) 부팅을 시작시키는 조그마한 프로그램이라도 어딘가에 있어야 그것으로부터 부팅과정을 시작할 수 있게 된다. 그 조그마한 프로그램은 volatile 메모리에 있으면 안되고, 비휘발성 메모리에 있어야 한다. 그것의 예가 ROM이다. ROM에 들어있는 20~30바이트의 간단한 프로그램(롬 로더)를 제일 먼저 수행한다.
롬 로더는 DMA를 이용해서 하드디스크 0번 섹터(부트섹터)에 존재하는 마스터 부트 레코드로부터 부트스트랩 로더의 첫번째 블록을 읽어, 메인 메모리에 적재한 후 이 첫번째 블록으로 점프(첫번째 블록의 시작주소)하여 역할을 끝냄 -> 롬로더의 역할은 끝남 -> 부트스트랩 로더의 첫번째 블록이 시작됨.
첫번째 블록이 수행되면 그 첫번째 블록은 부트스트랩 로더의 나머지 부분을 순차적으로 끌어서 적재하게 된다.
그렇게 나머지 부분의 적재가 끝나면 자신을 메모리의 상위 장소로 옮긴 후 전체를 실행한다. 그렇게되면 커널 프로그램을 읽어들여서 하위 기억장소에 다시 적재하게 되는 것이다. 부트스트랩의 역할은 커널 프로그램을 하위장소로 읽어들여서 적재하는 것이다.
부트스트랩은 이제 커널 적재가 끝나면 약속된 장소로 점프하여 커널을 시작시킨다. ---> chain loading 방식(아주 작은 프로그램에서 실행하여 다음 것을 로딩하고 그리고 그리로 점프하는 과정을 연쇄적으로 실행해서 운영체제 전체를 실행하게 되는 것이다.)으로 이루어진다.
모노리틱 커널 vs 마이크로 커널 : 커널의 구성상의 특징을 지칭하는 것이다.
모노리틱 커널 : 커널이 하나로 되어있다.
프로세스 관리, 메모리 관리, 파일시스템, 입출력 관리 및 네트워크 관리 등 모든 기능을 커널 내부에 포함 - 효율성을 높임
다른 플랫폼으로의 이식성이나 확장성의 한계를 하드웨어나 환경에 종속적인 부분을 따로 분리한 계층구조로 극복
예 : 리눅스 - 모듈 사용으로 확장성 문제 해결 // 새로운 장치 모듈을 사용해서 장치 하나만 컴파일하면 됨.
장점 : 일반적으로 시스템 호출 서비스가 빠름
단점
전체적으로 볼 때 새로운 하드웨어 플랫폼에 대한 이식성은 떨어짐
한 부분에서 발생한 문제가 시스템 전체에 영향을 줄 수있음
구성요소들 간의 의존성이 높아져 디버깅이 어려워짐
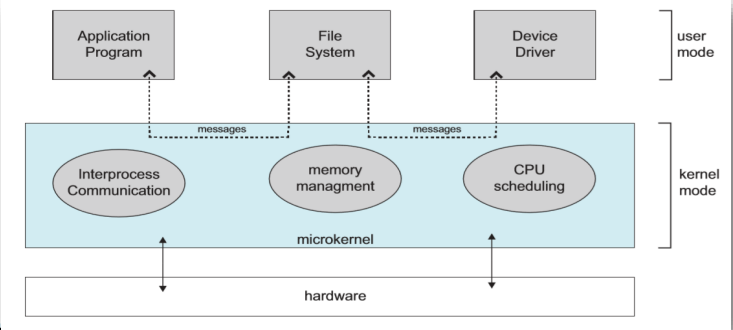
마이크로 커널
프로세스간 통신, 메모리 관리, 클럭 인터럽트 처리와 CPU 스캐쥴링 등 아주 핵심기능만을 커널에 포함시키고 나머지는 서버 형태로 두어 사용자 모드의 프로세스로 수행
시스템 콜이 들어오면 file system이나 device driver로 메시지를 전달하는 구조이다. 전달하고 결과를 받아서 다시 전달하고 하다보니까 user와 kernel 모드를 스위칭하는 것이 빈번해짐.
통신 프로토콜, 디바이스 드라이버 등의 수행은 사용자 프로세스로 존재한다
파일 시스템도 일종의 서버 프로세스로 수행한다
인터럽트도 인터럽트 서비스 프로세스에 메시지를 보내 처리한다
예 : CMU의 Mach, Windows-NT(마이크로 커널과 계층구조를 겸비한 독특한 구조)
장점
유연성이 좋다 : 커널의 핵심부분을 제외하고 나머지 User Application으로 실행하기 때문에
- cf> (상주) 모니터의 등장 : 다중 프로그래밍 기법을 고안하다 보니 작업관리 프로그램을 메모리에 상주시켜야 했고 입력장치와 비동기적 교신을 위해서 interrupt 처리를 위한 ISR도 메모리에 상주시켜야 했는데 이런 것들이 모여서 상주 모니터가 되었다. => 커널은 상주 모니터의 연장선
- 운영체제의 핵심 부분으로서 부팅 이후 메모리에 상주하는 부분 (부팅자체가 커널을 메모리에 탑재하는 과정)
- 상주모니터보다 발전해서 시분할 시스템을 제대로 지원하고 메모리와 CPU, 입출력 장치들을 관리하게 된다.
- 즉, 주로 자원 관리 및 자원 사용에 관한 서비스를 제공함
- 응용 프로그램과 커널은 하드웨어 지원을 받아 원천적으로 분리되게 되어있다. 즉, 응용프로그램하고 커널은 공간이 분리되어있다.
- 커널은 응용프로그램에게 시스템 호출이라는 것을 제공한다. 즉, 운영프로그램으로 하여금 입출력 등 커널 기능이 필요할 경우 이 시스템 호출을 호출하도록 한다. 그렇게 함으로써 커널은 스스로의 코드를 보호하고 응용프로그램은 시스템 호출을 통해서 커널 기능을 사용할 수 있게 된다.
시스템 프로그램 (커널과 혼동가능)
- 커널 이외의 프로그램으로써 운영체제 개발자가 기본적으로 제공하는 라이브러리나 운영체제 사용 도구
- ex> 편집기(vi 등), 컴파일러(gcc 등), 디버거(gdb), 쉘(ssh 등), 쉘 명령어(ls, cd, ps, grep 등)
- 쉘은 윈도우의 명령 프롬프트 또는 dos창, 우분투의 터미널 창 -> 명령어를 통해 사용자와 대화를 나누는 프로그램
- 쉘은 윈도우 형태의 유저인터페이스(GUI)가 보편화되면서 윈도우매니저가 그 역할을 대신한다. 윈도우 매니저의 전신이 쉘이다.
cf > 윈도우 매니저 : GUI 환경에서 각 프로그램들이 뜨는 창을 다루는 프로그램. MS 윈도나 애플 Mac에는 기본 시스템에 포함되어 있음.
커널의 구성요소
- 기능적 측면 의 구성요소
부팅 단계의 기능
하드웨어 진단 및 초기화 기능 - 커널 수행 이전에 하드웨어들을 진단하고 초기화하는 기능(커널이 수행되기에 적합하도록 하드웨어가 오류 없이 잘 준비되었는지를 진단하고 필요에 맞춰서 설정하는 기능)
디스크 상의 커널 프로그램을 메모리에 적재하는 기능 ( 커널 프로그램을 탑재할 때는 한꺼번에 탑재하지 않고 하드디스크 상의 마스터 부트 레코드로부터 순차적으로 chain식으로 탑재하게 된다)
부팅 후 기능 -> 각종 경영 기능
자원 경영(프로세스 경영, 중앙처리장치 경영, 주기억 장치 경영, 파일 시스템과 보조 기억장치 경영, 시스템 클럭 경영, 네트워크 경영, 입출력 장치 경영)
보안 및 정보보호 기능
- 형태적 측면 의 구성요소 -> 커널을 각종 기능을 수행하는 함수들이 어떻게 모아져 있느냐를 뜻한다
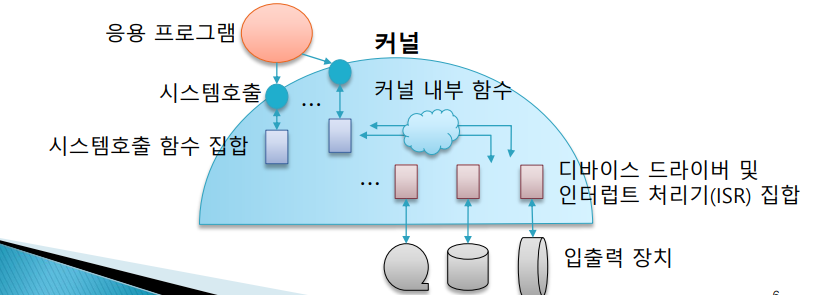
그림 : 커널 중심으로 맨 위에 응용 프로그램이 있고 맨 아래에 입출력 장치가 있다. 응용 프로그램은 위에서 커널이 제공하는 시스템 호출을 통해 커널 내의 함수 서비스를 받게 되어있다. 반면, 입출력 장치는 인터럽트를 통해서 커널의 ISR, 디바이스 내의 ISR을 작동시켜서 커널의 서비스를 받게 되어있다.
이렇게 시스템 호출, ISR 둘밖에 없는 것은 아니고 둘 사이에는 커널 내부의 작동을 담당하는 많은 함수들, 커널 내부 함수가 존재한다.
경우에 따라서는 시스템 호출 함수와 디바이스 드라이브 내의 함수들이 커널 내부의 함수들과 연결이 되게 되어있다.
인터럽트 처리기의 집합 - 시스템 클럭 및 대부분의 입출력 장치와 관계된 장치 드라이브의 핵심들이 된다.
커널 내부 함수의 예로는 [스케쥴러]가 있다. 스케쥴러는 중요한 기능이지만 형태적으로는 시스템 호출 함수나 인터럽트 처리기에 의하여 필요에 따라 호출되는 커널 내부 함수이다. 스케쥴링이 필요할 때 내부적으로 호출된다.
시스템 호출(system call)
- 응용 프로그램과 커널이 만나는 곳에 시스템 호출이 있다.
- 응용 프로그램 개발자에게는 함수 호출하는 것과 큰 차이가 없다. 예를 들어 printf, open, read, write -> 이런 것들이 라이브러리 내의 함수를 호출하듯이 사용하지만 알고 보면 시스템 호출이 이루어져서 커널의 함수가 내부적으로 작동하는 것들이 된다.
- 사용자 모드로 돌아가는 응용 프로그램이 open() 함수를 호출하게 된 것이고, 이것이 시스템 호출로 전환되어서 커널 내의 시스템 콜 테이블에서 해당 함수가 i번 함수인 것을 알아내서 처리가 이루어지고 처리가 끝나면 다시 사용자 모드로 가서 open() 함수의 다음 부분을 실행하는 그림.
시스템 호출이 이루어지는 과정
- 두 가지를 통해서 이루어진다
1. 파라미터 전달 방법(시스템 호출도 함수 호출과 비슷하기 때문에 파라미터를 전달함)
- Linux나 Solaris 같은 경우 : 파라미터를 레지스터를 통해 주소를 전달하는 방식
- X라는 곳에 전달하고자 하는 파라미터를 기록한 다음에 X의 주소를 특정 레지스터에 로드를 해놓는다. 즉, 메모리 상의 블록이나 테이블에 파라미터 값을 기록하고 시작 주소(X)를 레지스터에 기록하면 커널에서 레지스터 상의 주소를 얻어 파라미터 값들을 접근
- 다른 방식 : 레지스터가 아니라 스택을 사용
- 스택에 파라미터 값을 Push 하면 커널에서 pop해가는 방식
- 커널에 시스템 호출 사실은 어떻게 알릴까? : CPU의 명령을 실행
2. 특정 CPU 명령 실행
커널상에서 어떻게 대응되는지 정해져 있음
- open을 예시로 들면 open의 system call 고유번호가 13(시스템 호출 번호)이라는 숫자라고 볼 때, X를 담았던 레지스터와는 다른 CPU 내의 또 다른 레지스터에 담아서 interrupt를 거는(소프트웨어적인 인터럽트인 트랩) CPU 명령어를 실행하는 것이다. 즉 13을 다른 레지스터에 담고 interrupt명령어를 수행시켜 준다.
- interrupt를 거는 CPU 명령어 -> 소프트웨어 interrupt명령어(트랩 명령어)
- 트랩 명령어 : X86 계열의 경우 int라는 명령어, ARM 계열의 CPU인 경우 swi
- 이러한 interrupt는 하드웨어 interrupt와는 다르고, 단지 시스템 호출을 위해서 소프트웨어적으로 거는 것이라서 trap이라고 부른다.
- 리눅스의 경우의 예(리눅스 커널 2.4)
: 왼쪽에서는 응용프로그램이 사용자 공간에서 현재 수행 중에 있다. main을 수행하다가 read()를 만났을 경우이다. read함수 호출이 일어났다고 실질적인 내용이 막바로 실행되는 것이 아니다. 시스템 라이브러리인 libc 안에 있는 read함수가 호출된다. 이 응용프로그램이 컴파일되고 나서 링크될 때 read함수가 바로 libc함수로 링크되었기 때문에 libc내의 read함수가 호출되게 되는 것이다.
libc내의 read함수는 read라는 함수 번호가 3번으로 약속되어있다는 것을 커널 프로그래머가 지정해서 알고 있고 3번을 범용 레지스터인 eax 레지스터(명령어 주소를 담았던 레지스터와는 다른 레지스터)에 기록하고 (movl 3, % eax) trap명령어인 int를 수행하게 되는 것이다. 시스템 내에는 수없이 많은 interrupt가 존재하기 때문에 커널에게 trap임을 인지시키기 위해서 trap의 고유번호인 0x80을 int instruction의 operand에 담아서 실행시킨다(결국 int $0x80이 하나의 명령어로 실행되는 것)
이렇게 되면 커널로 0x80번의 interrupt가 걸리게 되는 것이다. 이에 따라서 IDT(Interrupt Descriptor Table)에서 0x80 interrupt의 ISR의 주소를 알아내서 노란색 저기로 점프를 하게 된다. ISR에서는 eax 레지스터의 4byte 값, int 수행 전인 3번을 읽어내서 call ~~~(% eax,4))-> 3
sys_call_table이라는 곳으로 가게 된다. sys_call_table은 system call table이다. sys_call_table에서 3번째 항으로 간다. 3번 항에 기록된 주소로 다시 한번 jump를 하게 된다. 이런 과정을 거쳐서 드디어 응용 프로그램이 read함수를 호출한 종착점인 sys_read() 함수로 도달하게 된다. (이 부분은 디바이스 드라이브 내부에 있을 공산이 크다..?) -> a와 b는 이후에 나올 내용과 연관. a는 커널 쪽을 얘기하고 b는 디바이스 드라이브 쪽.
- 시스템 콜의 실질적인 mechanism은 trap mechanism이다.
- 시스템이 다르면 맞지 않는 경우가 생긴다(ex. 파라미터의 순서, 시스템 콜의 번호) -> 호환성에 치명적인 문제 -> POSIX사용 (일관성)
- 국제 표준 - POSIX(시스템 콜의 표준)
- POSIX에서는 시스템 호출을 6개의 경우로 나누고 있다.
1. 프로세스 제어 ex. kill
2. 파일 조작 ex. open, close, read, write
3. 주변장치 조작
4. 정보관리
5. 통신 ex. send, receive(TCP socket)
6. 프로텍션(보호)
시스템 콜을 응용프로그램 개발자가 이용할 때 알아두어야 할 것
- 시스템 호출에는 2가지 유형이 있다.
1. 동기식(blocking call) : 입출력을 시작시키고 끝날 때까지 대기
- read() 같은 시스템 콜을 하고 결괏값이 넘어오기를 기다린다. 넘어오기까지 기다린 후에 넘어오면 read 다음 라인으로 계속해서 수행해가는 것. 그것이 blocking call이다. read가 실행되는 동안에는 진행을 멈추고 있다. 대부분의 시스템 콜은 이런 방식으로 지원된다. 기다리는 동안 CPU는 아무 일도 하지 않을까? ㄴㄴ -> 시분할 시스템에서는 그사이 다른 프로세스를 실행시키게 되어있다. 대기하는 동안 CPU를 다른 프로세스가 사용
2. 비동기식(non-blocking call) : 입출력을 시작시키고 바로 다음 연산을 수행, 입출력이 이루어지는 동안 자식도 CPU를 사용할 수 있음
- 시스템 콜이 이루어지면 커널에 요청만 해놓고 바로 리턴 그러고 나서 다음 라인을 바로 진행. 요청한 시스템 콜이 종료가 될 때 event가 전달된다. event가 처리할 함수를 인자로 알려주게 되어있다. --> callback함수. 이벤트가 온다는 것은 callback함수가 불린다는 것이다. callback함수는 전달되어온 데이터를 응용프로그램에 일종 자료구조에 저장하거나 직접 처리를 하게 되는 것이다. 이런 비동기식 시스템 콜은 사용하는 장치가 그러한 기능을 제공할 뿐만 아니라 디바이스 드라이브에서 비동기식에 필요한 기능을 잘 구현해놓은 경우에만 가능하다.
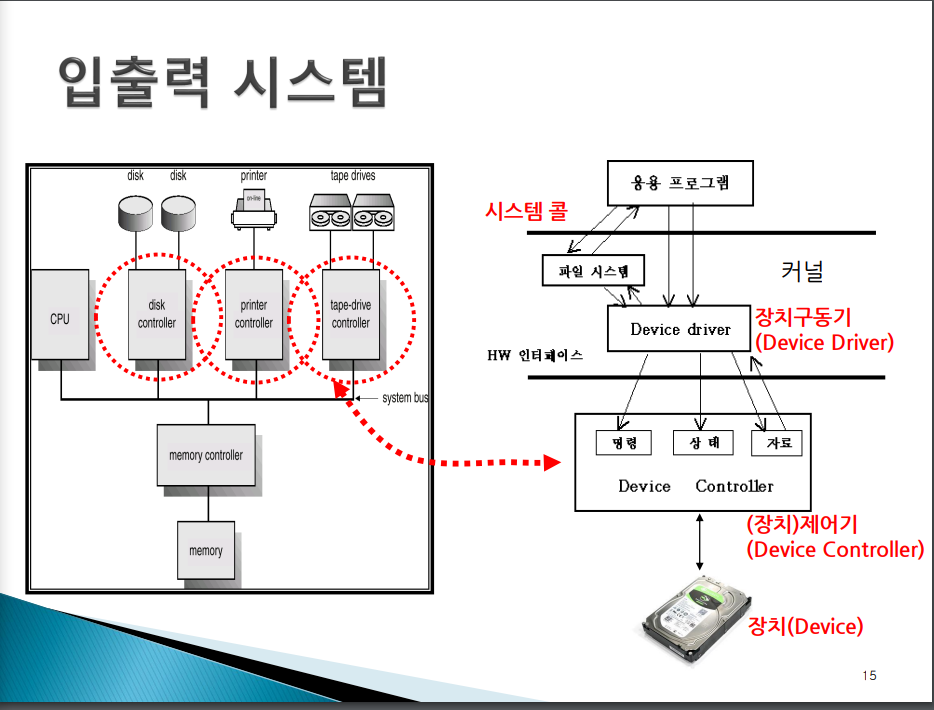
입출력 시스템 : 커널과 입출력 장치와의 인터페이스
물리적인 입출력 장치가 바로 시스템 버스에 접촉되어있는게 아니라 장치 제어기를 통해 연결되어 있다. 굳이 비유하자면 지상의 2층, 지하의 1층 건물과 같다. 2층은 응용프로그램, 1층은 커널이다. 지하 1층에는 하드웨어가 있다.
하드웨어는 제어장치와 장치로 이루어진다. 제어하기 위해 커널에는 Device driver가 있다. 층과 층 사이에는 인터페이스가 있다. 2층과 1층 사이에의 인터페이스는 시스템 콜이 되고, 1층과 지하 1층 사이의 인터페이스는 버스가 된다. (ex> PCI 버스)
Device driver는 하드웨어인 장치 제어기와 약속된 바에 따라서 명령과 정보를 주고 받는다. 그것의 실체가 무엇일까?
그것은 장치제어기 내에 있는 레지스터에(명령, 상태, 자료 레지스터들) 정해진 값을 쓰거나 읽어오는것이 된다. 장치 제어기의 레지스터들은 메인메모리 상의 주소에 mapping되어 있다. 따라서 Device driver는 이 주소에 값을 쓰거나 읽으면 바로 해당 레지스터의 값을 쓰고 읽게 되는 것이다. 그렇게 하드웨어가 만들어져 있다.
- 레지스터
명령 레지스터 : 장치가동을 위한 명령 코드 적재
상태 레지스터 : busy/done플래그, 오류코드 표현
자료 레지스터 : 장치 내의 하드웨어 버퍼
Device Controller(장치 제어기) 내에는 어떤 레지스터들이 있을까? 적어도 3종류의 레지스터들이 있다. 즉, 명령, 상태, 자료 레지스터. 명령 레지스터는 장치의 쓰기나 읽기 동작을 명령하기 위해서 명령 코드를 적재하기 위한 레지스터. 상태 레지스터는 현재 해당 장치에 오류가 있는지 또는 작업이 진행중에 있는지 작업을 끝내고 쉬고 있는지 등의 장치의 상태를 체크해보는 용도로 사용된다. 자료 레지스터는 명령 레지스터의 명령 오고갈 데이터를 읽고 쓰기위한 버퍼같은 용도로 사용된다.
층과 층사이의 인터페이스를 자세히 설명하자면 3가지로 봐야 한다. 두가지는 시스템 콜, HW인터페이스(버스).
장치들을 커널의 코드들을 바꾸지 않고 플러그 앤 플레이 식으로 install할 수 있도록 해야한다. 이 경우 커널과 디바이스 간의 인터페이스를 매우 잘 디자인해서 공개해주어야 한다. 그렇게 공개된 커널(1층)과 디바이스 간의 인터페이스가 3번째 인터페이스이다.
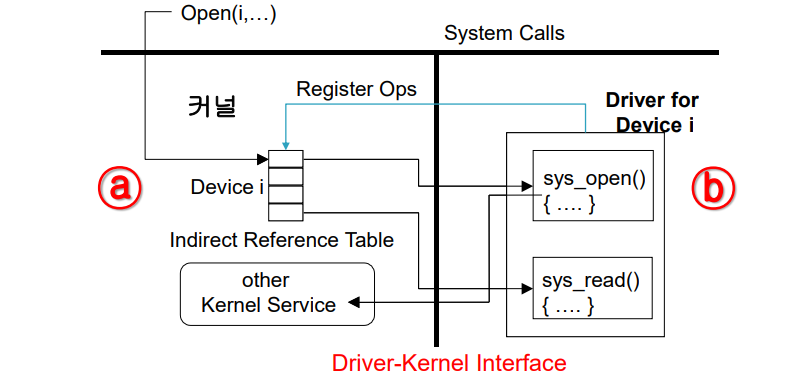
- 커널과 디바이스 간의 인터페이스(장치구동기- 커널 인터페이스)
: 왼편이 커널, 오른편이 디바이스 드라이브이다. 그 사이에 커널과 디바이스 간의 인터페이스(Driver-Kernel Interface)가 있다. 커널안에는 디바이스 드라이브가 등록되면 디바이스 드라이브의 번호가 생김, 여기서는 번호가 i 이다.
그 디바이스 드라이브가 제공하는 함수들이 등록되는 table같은 구조가 있다. 앞서 설명한 시스템 콜 테이블이 일례이다. 이후, 응용 프로그램에서 장치 i를 사용하고자 open이라는 시스템콜을 호출하면 트랩을 통해 진입. 그런 후 i를 위한 커널 내의 테이블에서 open함수의 실제 구현함수인 디바이스 드라이브 내의 sys_open이라는 함수 포인터를 얻어서 그 함수로 점프를 하게 된다.
이러한 과정을 통해서 커널과 디바이스 드라이브 간의 인터페이스가 동작하게 되는 것이다. 디바이스 드라이브는 커널 모드에서 커널과 함께 동작하기 때문에 디바이스 드라이브가 커널 내의 커널 함수를 직접 호출하거나 커널 내의 변수를 직접 접근할수도 있다. 커널의 기능을 효과적으로 이용하는 디바이스를 만들 수 있을것이다.
하지만 커널 내의 함수와 커널 내의 전역변수들을 바로 접근할 수 있기 때문에 디바이스 드라이브를 만들때 상당히 조심해서 만들어야한다.
디바이스 드라이브와 장치제어기 사이에 명령이나 정보가 오고가는 그것의 실체가 뭐냐라는 것을 얘기할때 레지스터를 접근하는 것이다 이렇게 설명함. --> 파고들어가면 방법이 다양함.
전반적으로 HW 인터페이스와 관련된 것이다. 먼저 HW 인터페이스 운영체제 관점에서 중요한 점들. (디바이스 드라이브를 설계하는데 있어서 결정적인 영향을 미치는 중요한 요소들) (장치와 장치제어기를 만드는 menufactoror들이 커널 안의 디바이스 드라이브를 짜는 software또는 개발자들에게 반드시 정확히 설명해주어야 할 부분이 있는 것이다. 그것을 장치 메뉴얼로 전달한다) 3가지 포인트가 있다.
장치제어기와 장치를 만드는 사람들이 디바이스 드라이브를 짜는 사람들에게 반드시 알려주어야 할 사항들
1. 접근 방식에 의한 분류 (레지스터 접근 방식) 어떤 방식이 있느냐
- 격리형(isolated I/O)
- 메모리 사상형(memory-mapped I/O)
2. 자료이동 방식에 따른 분류(디바이스 드라이브가 장치 제어기 내의 준비된 자료를 가져오는 방식)
- 직접 입출력 방식
- DMA 방식
3. 제어 방법에 의한 분류(장치 제어기 내에서 벌어진 상태변화를 디바이스 드라이브에게 알리는 방식)
- 폴링(polling)
- 인터럽트
아래에서 설명
1. 레지스터 접근 방식
격리형(Isolated I/O 또는 I/O mapped I/O) 입출력
입출력 장치가 메모리와는 별도의 주소공간 사용(하드웨어 구조상 주변장치를 위하여)
이 방식은 메모리 주소 지정을 위해 사용하는 주소 버스와는 별도로 I/O 장치를 위한 주소 라인을 따로 사용하기 때문에 주소값이 메모리 주소인지 입출력 장치 주소인지 구별하는 제어라인을 따로 사용하는 하드웨어 구조를 전제하는 방식이다.
결국 이러한 하드웨어적 특성을 이용하기 때문에 특수한 입출력 명령어를 사용해야 한다. (제어기 레지스터 접근을 위하여 하드웨어에 특화된 특수한 입출력 명령어)
장점 : 입출력이 메모리 주소 공간의 크기나 할당에 영향을 주지 않음
단점 : 메모리 접근 명령어와는 별도의 입출력 명령어를 사용하게 되어 프로그래밍의 일관성이나 이식성이 떨어짐
메모리 사상형(Memory-Mapped IO) 입출력
장치를 위한 별도의 주소 공간과 명령어를 정의하지 않고 메모리의 논리적 주소 공간에 제어기의 레지스터를 사상(mapping)
메모리 주소 지정을 위해서 주소 버스와 입출력 제어 라인을 공유를 하고 주소 버스에 실린 값으로 메모리 주소와 입출력 주소를 구분하는 하드웨어 특징을 전제로 한다. 메모리 주소냐 입출력 주소냐를 구분하는 별도의 라인을 두지 않고 주소 자체로 판단한다.
따라서 메모리에 할당된 주소의 일부를 장치 제어기의 레지스터를 접근하는 주소로 사용할 수 있게 되는 그런 방식이다.
별도의 주소 공간과 입출력 명령어가 필요 없고 기존의 메모리 접근을 위한 명령어를 사용
예를 들어서 CPU가 제공하는 LOAD명령과 STORE명령으로 수행(모든 입출력에 관한 명령은 해당 메모리에 대한 LOAD와 STORE 명령으로 수행)
장점 : 명령어 개수를 줄일 수 있어 프로그래밍이 용이하고, 일관성과 이식성이 좋다
단점 : 입출력을 위하여 메모리의 일부를 사용하므로 메모리 영역이 감소된다.(최근은 메모리가 커져서 큰 손해는 아님 -> 메모리 사상형 입출력이 보편화되었다)
2. 자료 이동 방식 : 장치제어기 내의 자료 레지스터하고 메인 메모리 사이의 데이터가 어떤 방식으로 이동하는 것인가에 관한 것. 직접 입출력 방식과 DMA 방식이 있다.
직접 입출력
CPU가 장치 제어기 내의 레지스터하고 메모리 자료 이동을 매번 직접 관장
CPU는 기본적으로 입출력 장치가 입출력을 하는 도중에도 프로세스 수행을 계속 할 수 있도록 되어있다. 하지만 이 방법 사용시 매 입출력 마다 인터럽트가 들어오기 때문에 CPU에게 상당한 부담이 될 수 있다.
따라서 이 방식은 입출력발생의 시간간격이 비교적 큰 장치들(ex> 문자 장치(chararcter device)) 캐릭터 단위로 입출력(ex> 키보드) Serial 입출력 방식이 여기에 해당한다.
반면, 대용량의 입출력 장치를 블록 장치라고 하는데(block device) (가장 대표적으로 하드디스크) 이런 장치에 직접 입출력 방식을 사용하는 것은 문제가 크다.
이걸 극복하는 방식이 DMA 방식이다.
DMA(Direct Memory Access)
입출력장치가 CPU 도움 없이 독자적으로 메모리(시스템 버퍼)에 Direct로 접근하여 한 입출력 명령으로 많은 자료(블록)을 입출력/전송
한 가지 문제가 있을 수 있는데 메모리 입장에서 CPU도 독립적으로 접근할 것이고, DMA도 독립적으로 접근을 하게 되어서 서로 간에 충돌이 일어날 수 있다.
해결 : Cycle Stealing -> CPU와 DMA가 동시에 메모리 접근을 요구한다면 DMA에 우선권을 주고, CPU는 한 사이클을 쉬게 됨.
Cycle : CPU가 instruction을 수행하는데 있어서 한번에 instruction 수행하는 것이 아니라, CPU수행을 위해서는 몇번의 cycle을 돌게 되어 있다.
CPU 입장에서 보면 I/O는 가끔 일어나는 셈이 된다. I/O가 일어나는 interval이 길기 때문에 우선권을 한 사이클정도는 DMA에 줘도 괜찮음
DMA의 주체는 하드웨어이다.
한 블록의 입출력 완료시 한번만 인터럽트 발생시켜 빈도수를 줄인다.
3. 장치제어기 상태를 CPU로 하여금 알게 하는 방식(CPU가 장치제어기 상태를 알아내는 방식)
폴링(Polling) 방식 vs 인터럽트 방식
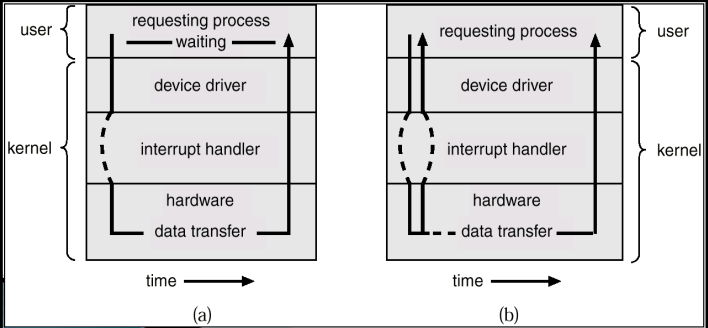
폴링(Polling) 방식 : 상대방의 상태를 내가 주도적으로 체킹한다 -> CPU가 레지스터를 반복적으로 체크하면서 목표한 상태로 바뀌었는지 체크한다. 따라서 상태변화가 있을때까지는 CPU가 계속 대기하면서 체크하고 있다. 폴링을 위해서 디바이스 드라이브가 동작하는 내용을 순서적으로 본다면
응용 프로세스로부터 입력이 요청됨
장치구동기가 장치제어기의 명령 레지스터에 명령어 적재(장치제어기는 하드웨어이기 때문에 즉시 장치 가동) -> 장치 가동
상태 레지스터가 busy 상태에서 done으로 바뀔 때까지 대기(그 명령어로 인해 장치가 끝날때까지 기다림)
done이 되면 제어기의 자료레지스터 내용을 응용 프로세스 공간으로 복제
단점 : 루프를 사용하여(busy waiting 방식) 제어기의 상태를 체크하는 것은 CPU를 낭비하게 됨
그러나, 인터럽트가 제공되지 않는 장치의 경우 일정시간 주기적으로 제어기 상태 조사
폴링 방식을 사용하면 busy waiting으로 인하여 CPU에 부담이 가중된다. 할 수 없이 폴링 방식을 사용해야 되는 경우도 있지만 좋은 방법은 아니다. 대안은 인터럽트 방식이다.
인터럽트 방식 : (폴링이 대기 방식이였다면 인터럽트는 알림 방식이다.)
CPU가 디바이스 드라이브의 코드를 실행함으로써 결국 입출력 명령을 장치 제어기에 전송을 한다. 그리고는 CPU는 다른 프로세스를 수행하고 있으면 그 요청에 뜬 입출력 작업이 다 끝났다는 것을 장치제어기가 CPU에게 알리는 것이다. 여기서 알리는 것을 인터럽트라고 부른다. 즉, 인터럽트는 장치제어기가 보내는 것이고 인터럽트는 CPU가 받는 것이다. 그래서 장치제어기가 입출력 작업이 끝나면 다 끝났다고 CPU에게 알리는 것, 그것이 interrupt라는 것이다.
인터럽트 방식은 하드웨어가 인터럽트 처리 체계를 갖고 있다는 것을 전제로 하고 있는 것이다.
인터럽트가 발생하면..
1. (중단) 현재 진행중인 프로세스 또는 하위의 ISR(Interrupt Service Routine) 수행을 즉시 중단
2. (문맥보존) 프로그램 카운터 (PC) 및 CPU 레지스터 값들을 보존(문맥에 해당)
3. (마스크설정) 현재의 인터럽트에 해당하는 마스크를 설정하여 자신보다 하위 인터럽트가 먼저 처리되지 않도록 함(상위 하위 이런것들 판단하기 위해 마스크 설정)
4. (ISR 진입) 현재의 인터럽트에 해당하는 ISR으로 제어를 넘김(즉, 프로그램 카운터를 해당 ISR의 첫주소로 셋팅) (ISR 시작주소 알아야함)
인터럽트 백터 테이블에 장치번호 순서대로 ISR의 시작주소가 기록되어 있음.
인터럽트 처리가 끝나면 인터럽트 당한 프로세스 또는 수행중이던 하위 ISR을 계속 실행하기 위해 보존된 레지스터 내용을 복구 <- 운영체제의 결정이 필요
어떤걸 복구하냐 -> 프로세스이면 여러개 중에 운영체제의 결정이 필요하다(스케쥴링에서 필요)
여러 종류의 인터럽트 간의 경쟁 조정을 위해 인터럽트 priority level을 결정할 필요가 있다
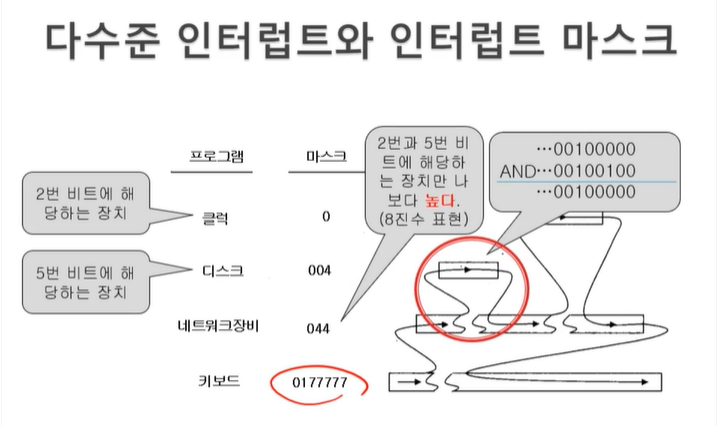
다수준 인터럽트와 인터럽트 마스크
시스템의 모든 장치에 대해 비트(또는 비트번호)를 지정
예를 들어서 시스템에 접속될 수 있는 장치 최대 장치 개수가 16개라 한다면 인터럽트 종류도 16개가 된다. 그렇게 하기 위해서면 2byte면 된다. 2byte라 하고 각 비트마다 하나의 인터럽트를 지정해주는 것이다. 예를 들어 디스크는 5번, 클럭은 2번 이렇게 지정. 8진수면 디스크는 040 클럭은 004
인터럽트 마스크를 통해 수준(Interrupt priority level) 적용
인터럽트 마스크도 2byte를 사용하겠고 그것도 장치마다 지정했던 비트를 사용한다. 인터럽트 마스크는 우선순위 비교용인데 우선순위 비교를 어떻게 하냐.
예를 들어 방금 전에 interrupt가 들어와서 이에 해당하는 ISR을 처리중인데 그 ISR에 들어가기 전에 interrupt mask를 044로 설정했다고 하자.
044면 2번이랑 5번 bit에 1이 표시되어있다. 2번이랑 5번이 아까 클럭과 디스크라 함. 무슨 뜻이냐하면 현재 ISR이 뭔가 처리중에 있는데 ISR을 위해 처리하기 바로 전에 뭐라고 마스크를 설정했냐 하면은 2번이랑 5번은 나보다 쎈 놈입니다. 그놈들이 들어오면 나를 잠시 중지시키세요하고 설정을 하고 들어갔다는 의미이다. 그게 바로 클럭하고 디스크이다. 현재 진행하고 있는 인터럽트 처리보다 클럭이나 인스턴스의 우선순위가 높으니 그것들로부터 인터럽트가 들어오면 나를 잠시 중지시켜달라. 그게 인터럽트 마스크를 설정했다는 의미이다.
그러한 상황에서 새로 인터럽트 들어왔는데 디스크 인터럽트가 떴으면 그러면 그 인터럽트는 어떻게 표현이 되냐하면 5번 비트가 1로 표현이 된다. 그래서 현재 새로 들어온 인터럽트는 00100000으로 표현이 된다. 그럼 새로 들어온 인터럽트가 더 쎈놈이냐 판단을 해야 하는데 그래서 두개사이에 AND operation을 취한다. 이게 결국에 masking을 해보는 것이다. masking을 했더니 한 bit가 맞아서 1이 되었다. 그래서 전체 값이 양수가 나왔다. 양수가 나왔다는 것은 0이 아니라는 것이고 0이 아니면 False가 아니라는 뜻이므로 새로 들어온 인터럽트가 쎄다라는 것을 판단할 수 있다. 그래서 지금 들어온 디스크 인터럽트부터 처리한다. 그게 인터럽트 마스크의 역할이다.
인터럽트 마스크를 통해 수준(Interrupt priority level) 적용
임의 인터럽트가 들어오면 해당 인터럽트와 현재의 마스크를 비교하여(마스킹) 우선순위 판단
그래서 인터럽트 마스크를 항상 설정해주어야 한다. 언제 설정하냐 -> 인터럽트의 ISR시작에 앞서서 인터럽트 마스크를 재설정하고, ISR 종료시 원상복구 해준다. -> 디바이스 드라이브 만드는 사람의 책임이다.
Q> 가장 순위가 낮은 인터럽트(아마도 키보드 인터럽트), 키보드 인터럽트의 ISR을 처리하는 동안에는 인터럽트 마스크는 어떻게 설정되어 있을까? 당연히 모든 비트가 1로 setting된 0177777이 될것이다.
이 말은 어떠한 interrupt가 와도 새로운 인터럽트를 처리해도 된다는 뜻이다.
만약 키보드 인터럽트를 처리중에 있다가 네트워크 장비로부터 인터럽트가 들어오면 키보드 인터럽트보다는 네트워크 인터럽트가 우선순위가 높으니까 당연히 현재 처리중인 것은 중단이 되고 네트워크 인터럽트를 처리하러 들어간다. 네트워크 장비에 해당하는 마스크를 044로 설정하고 들어갔다 하자. 즉, 2번과 5번, 클럭과 디스크에 해당하는 장치만 나보다 높다라는 뜻. 그렇게 해서 네트워크 인터럽트를 처리하는 도중에 디스크 인터럽트가 떴다. 그럼 다시 마스크를 004로 설정하고 디스크 인터럽트에 들어간다. 그래서 클럭이라는 것은 2번비트에 표현하고 디스크 인터럽트 ISR 처리하기 위해 들어간다. 즉 자신보다 인터럽트 높은건 지금 클럭밖에 없기때문에. 누가 우선순위 높은지는 빠르게 판단하기 위하여 하드웨어 기준으로 이루어져야 한다. 즉, 마스킹 오퍼레이션은 하드웨어적으로 이루어진다. 이를 위해 AND 연산을 한번만 사용하면 masking operation이 되도록. 즉 디스크로부터 인터럽트가 들어왔다는 것은 004, 네트워크장비는 044, 두개를 AND연산하면 0이 아니므로 더 쎈 인터럽트가 들어왔다는 의미가 됨. 그래서 바로 디스크 인터럽트 처리를 위한 ISR이 된다.
Fast interrupt Handler(FIQ) => 지엽적인 내용이긴함
Fast Interrupt : 특별히 빠른 처리 혹은 빠른 반응을 위해 ISR에서 다른 인터럽트 처리를 disable 시키고 짧은 시간에 처리를 마무리하는 것을 의미한다. 시스템에서는 clock 같은 것들이 중요한데 clock interrupt같은 것들은 fast interrupt로 처리한다.
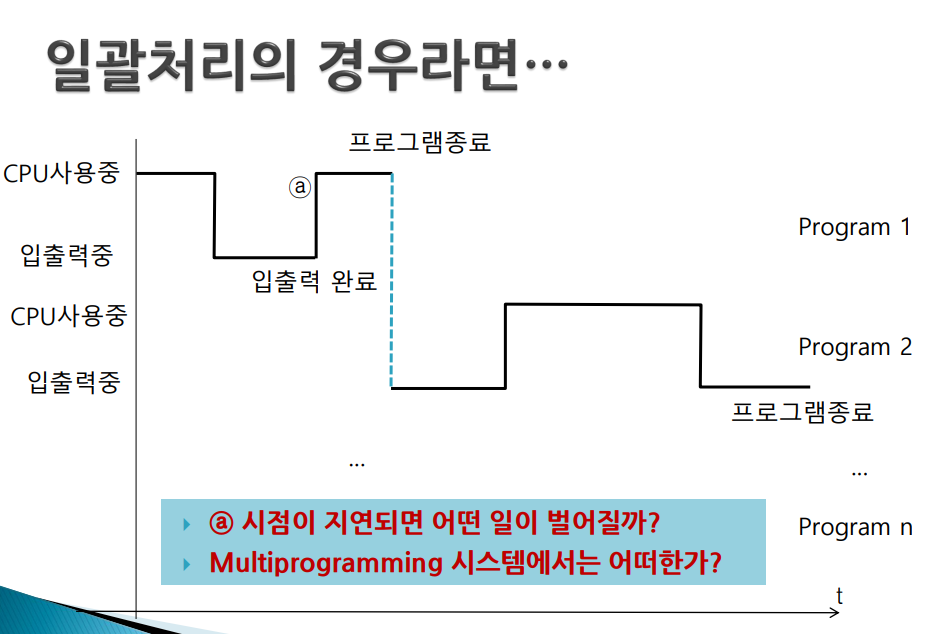
다중 프로그래밍은 더이상의 대화성 증진에는 한계가 있었다. 입출력이 일어날 때에만 스케쥴링이 일어나기 때문에
- 한 프로그램의 입출력 빈도와 시간이 다른 프로그램의 수행에 영향을 준다.
- 한 프로그램의 수행시간이 다른 프로그램의 수행시간에도 영향을 준다.
시분할 시스템
다음처럼 a시점 이후 b까지의 대기시간이 있다 -> Program2가 Program1에 영향을 준다.
- 따라서, 사용자와의 빈번한 대화성(편리성) 증진에는 한계가 있다.
시분할 시스템의 핵심은 타임슬라이스
- 입출력 발생이 일어났을 경우에도 스케쥴링이 일어나지만 타임슬라이스가 도래하면 무조건 스케쥴링을 시행한다.
- 프로그램의 간섭을 없애고 대화성도 증진시킬 수 있었다
- 시분할 시스템은 1960년 CTSS가 시초인데 하드웨어 여건 부족으로 안되다가 현재에 운영체제의 기본적인 체계로 자리잡았다
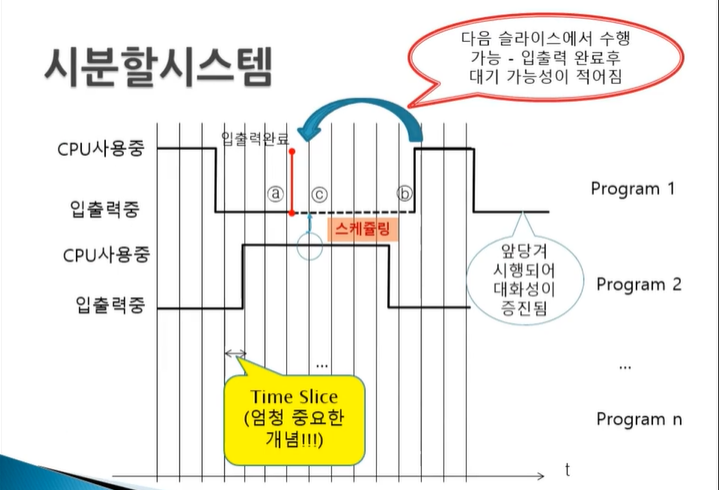
시분할 시스템의 원리
다중 프로그래밍과 비슷하지만 한가지가 바뀌었다. 세로줄들이 여러개 추가되었다.
이 세로줄이 타임슬라이스(Time Slice)이다. Time Slice가 끝날때마다 스케쥴링을 실행한다. 이렇게 되면 입출력이 되었을때도 스케쥴링이 일어나겠지만 그 외에도 Time Slice 도래했을때도 반드시 스케쥴링 일어나서 서로간의 간섭을 최소화할 수 있다.
Program1이 입출력을 완료한 시점인 a 바로 다음 시점에 타임슬라이스 일어났을때 속개될 수 있는 가능성이 생기는 것이다. 여기서 b-c만큼 앞당겨질 수 있는 가능성이 생긴 것이다. 단, 여기서 우선순위가 개입된다. C 시점에서 스케쥴링을 하는데 이 때 우선순위가 2가 더 높다면 c에서 1이 실행되지는 않는다.
궁금한 점은 Time Slice는 그럼 컴퓨터 상에서 어떻게 실현할까? Time Slice는 기본적으로 Timer Interrupt를 통해 구현한다고 생각하면 된다. 보통 10msec로 interrupt를 설정해서 그 interrupt가 들어올때마다 스케쥴링을 하는 것이다.
- 시분할 시스템이 대두되었을때는 컴퓨터의 수요도 늘고 있었을뿐만 아니라 대화형 편집기의 인기가 높아졌을때.
이에 따라서 빈번한 대화, 즉 입출력 요구가 수행시간의 대부분을 차지하는 프로그램이 보편화되었고 그럼에 따라서 시분할 시스템이 좋은 해결책이 되었다.
- 대화성이 증진되다보니 사용자 입장에서는 시스템 전체를 혼자서 사용하고 있다는 착각이 가능했다. 여러 사용자가 개인용 모니터를 통하여 한 시스템에 동시에 연결하여 동시 사용이 가능해졌다. 즉, 운영체제가 각 사용자들 프로그램 사이를 재빠르게 전환함으로써 혼자 컴퓨터 독점했다는 착각. 각 사용자에게 각자의 모니터를 통해 접속하도록 해서 혼자 사용한다는 느낌.
- 터미널이라고 부름(키보드와 브라운관으로 이루어짐)
- RS232라는 시리얼 통신표준 사용
- 시리얼 라인을 통해서 전산센터의 중앙컴퓨터의 각 포트에 원격으로 연결
- 각자의 방에서 vi같은 편집기를 통해 작업할 수 있다
- CPU의 효율성 증대, 빠른 응답시간을 제공함으로써 편의성도 증대
- 타임 슬라이스 이외에도 다양한 연구주제들을 파생시킴
- 가상 메모리 : CPU 활용의 효율성이 높아짐에 따라서 더 많은 프로그램을 동시에 적재하고자 하는 요청이 들어온다. 이는 결과적으로 메모리 부족을 야기하게 되었다. 그래서 한정된 메모리로서 여러 프로그램을 실행시킬 수 있도록 했어야 했는데 이를 위해서 탄생한것이 가상메모리 기법이다.
- CPU 스케쥴링, 동기화 및 교착상태 같은 이슈 대두
실시간 시스템
- 특수한 분야를 위해 발전시킨 기술. 프로그램의 동작에 실시간성, 즉, 엄격한 마감시간(deadline)이 요구되는 분야가 있으며, 이러한 요구를 만족하는 시스템을 실시간 시스템이라 함.
- 예를 들어, 공장 생산 라인, 과학실험 제어, 산업제어, 항공기/미사일 제어, 로봇, 동영상 처리
- 실시간성은 두가지 부류로 나누어진다.
1. 경성 실시간성(hard real-time)
- 데드라인 위반사건 발생시 재앙적 사건이 발생 - 무기 제어, 원자력 발전소.
- 데드라인 100% 준수한다는것을 수학적, 실험적으로 증명해야 함
- 경성실시간 운영체제는 아주 크기가 작다. 코딩량이 많을수록 증명하기 어렵기 때문
2. 연성 실시간성(soft real-time)
- 데드라인은 존재하지만 위반시 재앙까지는 야기하지는 않음 - 동영상 플레이어
- 만족여부는 주로 확률적으로 제시되며 보통 실시간 작업과 일반 작업 간의 우선순위 제어로 해결한다
- 실시간과 관련해서 스케쥴링 알고리즘에서 실시간 스케쥴링 알고리즘 다룰 예정
실시간 시스템을 시분할 시스템과 굳이 구분하여 얘기하자면 실시간 시스템 경우 deadline의 b시점일 경우 그에 앞서서 반드시 실행시켜야 할 작업을 수행하는데 걸리는 최대소요예측시간(WCET)이 주어졌다고 하자. (안주어질 경우도 있다)
b라는 마감시간을 놓치지 않으려면 아무리 늦더라도 c시점까지는 스케쥴링이 마무리 되어서 프로그램1이 속개되도록 해야될것이다. 프로그램2가 c에서 스케쥴링을 당해야한다.
트랩은 커널공간과 사용자공간을 나누어서 접근할 수 있는 권한설정에서 매우 중요한 역할을 한다.
-> CPU는 CPU나름 입출력장치는 입출력장치 나름대로 데이터를 출력하고 메모리 어느 곳에 데이터를 얹어놓는데 이곳이 버퍼이다. 양쪽이 분리되어 동작하고 서로 소통은 CPU를 통해 진행한다.
- 문제는 주컴퓨터 CPU가 부하가 걸린다(operator가 있을땐 나눌 수 있었는데 operator를 없애다 보니까 CPU가 과부하)
-> 해결 : 입출력장치와 CPU가 각자의 간섭없이 작업을 하도록 하고, 그동안 입출력장치가 컴퓨터 메모리상의 약속된 장소를 직접 접근하면서 입출력을 끝내도록 하고, 그 작업이 끝나면 CPU에 알리도록 해서 CPU가 다음 입출력 작업을 지시하도록 한다.
일괄처리시스템에서 모니터의 태동 : operator 자동화를 위해서는 메모리에 상주하는 프로그램이 필요하다
-> operator 대신 프로그램이 메모리에 올라가 있어야 되기 때문( ex> ISR, 적재기, JOB Sequencer, 제어카드 번역기)
상주모니터(Resident Monitor)
- 컴퓨터가 시동되는 시점부터 메모리에 탑재되어서 영구적으로 상주해야되는 것들
- 인터럽트 처리기 또는 입출력 관리자를 메모리에 영구적으로 상주시켜야 할 필요성 대두
- 작업 제어 명령어, 적재기, 작업 순서 제어기를 상주시켜 컴퓨터의 운영을 좀더 자동화 시킴
보호 이슈 >>
- 모니터가 메모리에 상주하는데 메모리에는 모니터도 있지만 채널을 통해서 버퍼에 들어오는 것이 프로그램이 탑재되어 들어올 수도 있다.
-> 다른 프로그램이 메모리 한 부분에 위치하게 되어서 CPU에 의해서 수행될 수도 있다. (ex> 사용자 프로그램들)
-> 이 프로그램을 수행하다가 모니터의 영역을 침범하는 경우가 생긴다 (즉, 덮어쓰는 경우가 생겨서 상주 모니터 보호의 필요성 대두된다)
특히 입출력할 때 자주 발생해서 이를 방지하기 위해 모든 사용자 프로그램은 입출력을 직접 하지 않고 반드시 모니터가 제공하는 입출력 함수를 호출해서 입출력하도록 했다 (-> 시스템 콜의 태동) ex> fork() 함수
(시스템 콜 : 커널 내의 함수를 응용 프로그램이 불러 쓰는 것)
-> 미리 작성된 테이블에 기록된 메모리 접근 허용치(사용자 프로그램이 접근할 수 있는 메모리 영역 허용치) 참조하여 각 연산 수행 시 메모리 접근 범위를 제한한다.
일괄처리시스템의 장점
- 초기 일괄처리 시스템에 비하여 효율성 개선됨(효율성 높이는데 큰역할)
- 하나의 작업이 CPU를 독점하므로 해당 작업으로 볼 때는 처리 속도가 가장 빠르다 (프로그램이 자원 독점)
- 사용자와의 대화가 필요하지 않은 CPU-bound 응용 프로그램 수행에 적합하다 (수치 계산, 대용량 데이터 처리 등)
단점
- 사용자와의 대화가 필요한 요구들이 많을때(ex> 편집기 ) 이것을 수행하기에는 부족하다
- 일괄 처리 시스템은 한 작업, 한 작업을 순차적으로 처리 -> 한 프로그램이 입출력을 위해 소모한 시간은 다음 프로그램에게는 기다리는 시간(즉, 전체 처리량 저하)
--> 그렇다면 여러 프로그램을 동시에 실행시키면??
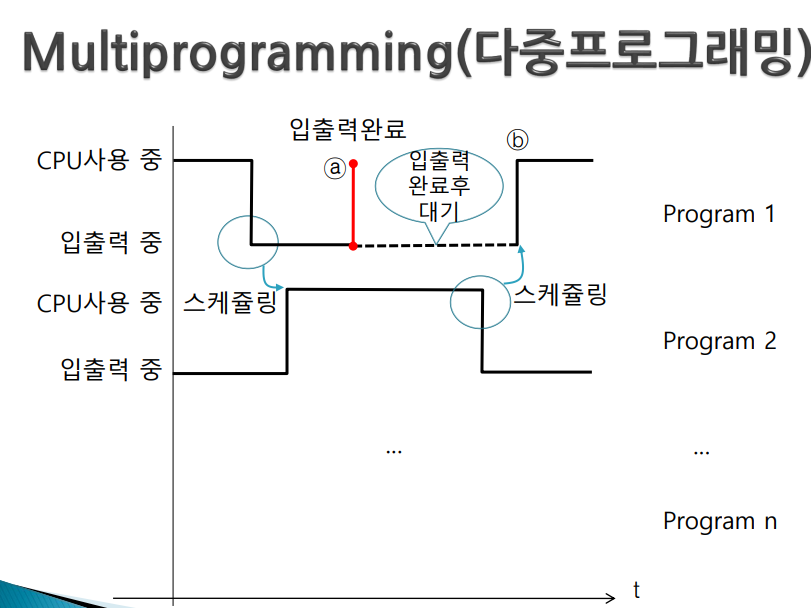
다중 프로그래밍(Multiprogramming)
다중 프로그래밍은 일괄처리시스템과 달리 프로그램을 번갈아 수행한다
- 프로그램을 수행하다보면 어느 순간 입출력이 일어남(키보드 입력을 기다리거나 출력이 끝나기를 기다리는 상태에 도달)
-> 입력이 들어오기까지 마냥 기다리는 것이 아니라 입력이 들어오면 interrupt를 걸도록 해놓고 그 사이 다른 프로그램 선택해 수행 (이걸 모든 프로그램에 적용하면 번갈아가며 수행시킬 수 있게 된다)
- 한 시점에 여러 프로그램을 사용자 영역에 탑재
-- 시스템에 들어오는 모든 작업은 일단 작업 풀(디스크 사용)에 적재됨
--작업풀 내의 작업은 운영체제의 정책에 따라 선택되어 메모리에 탑재
- 탑재된 작업 중 하나를 선택하여 실행한다
- 한 프로그램이 입출력을 하는 동안 다른 프로그램을 선정하여 CPU가 실행한다(이것이 스케쥴링, 어떤것 선정이 좋을지 정책 필요)
- 스케쥴링이 언제 일어나냐 -> 다중 프로그래밍인 경우 수행중이던 프로그램에서 입출력이 일어날 경우에만 스케쥴링이 일어난다.
(- 시분할 시스템에서도 스케쥴링 일어나는데 차이 구분하면??)
- 만약 program2에 문제가 있어 무한 loop 돈다(program1은 cpu 받기를 기다리고 있다) -> 스케쥴링은 입출력 변할때만 이루어지니까 program2가 무한루프를 돌면 입출력을 하는 순간은 오지 않는다. 즉, 입출력 요구하는 상황이 벌어지지 않는다 -> 스케쥴링도 일어나지 않는다 -> program1 영원히 대기
- 그래서 다중 프로그래밍인 경우 프로그램 간섭이 일어날 수 있다
1. 스케쥴링은 입출력이 일어났을때만 된다 2. 프로그램 간의 간섭이 일어날 수 있다
-> 대부분 프로그램의 실행 시간에서 CPU의 사용 시간은 극히 일부분이고 나머지는 입출력 시간이다.
-> N개의 프로그램이 실행된 시간이 각각 t1, t2, ... ,tn이라 할 때,
- 일괄처리 또는 uniprogramming : t1+t2+t3+... +tN
- 다중프로그래밍인 경우 대략 : max(t1,t2,,,,tN)
- 한 프로세스의 입출력 시에 다른 프로세스를 처리할 수 있게 되므로, CPU가 항상 일을 하고 있게 됨
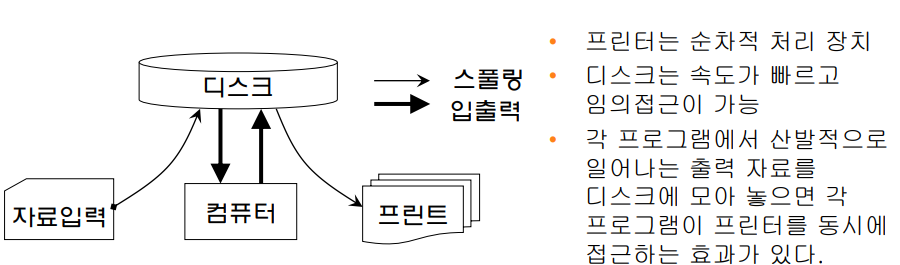
- 또한, 디스크를 이용한 Buffering과 Spooling으로 입출력과 CPU수행의 중복 정도를 높일 수 있게됨
- Input Spooling은 Job Scheduling에 사용
- Output Spooling은 산발적인 프린트 출력을 모아서 프로세스가 끝난 후에 출력
- 새롭게 대두되는 이슈
- Job Scheduling : 최적의 스케쥴링 방법
- 메모리 경영 - 여러 작업이 메모리 상에 존재, 한정된 메모리 공간에 n개의 프로그램 탑재해야 되기 때문에 어떤 것들을 탑재하느냐에 대한 알고리즘
우리가 알고있던 프로그램이 실행되면 CPU에서 프로세스라는 것으로 실행된다는 것을 알았다. 그렇다면 프로세스는 어떻게 생성되고 복사되는지 알아보자.
1. 프로세스의 구조
: 프로세스는 코드영역, 데이터 영역, 스택영역으로 구성된다. 예를 들어 워드프로세서 프로그램을 실행하면 이 프로그램은 코드 영역에 탑재되고, 워드프로세서로 편집중인 문서는 데이터 영역에 탑재된다. 또한 운영체제가 워드프로세서를 작동하기 위해 사용하는 각종 부가 데이터는 스택 영역에서 관리한다. 이렇듯 프로그램이 프로세스가 될려면 3가지 영역이 유기적으로 작동한다.
코드 영역 code area : 프로그램의 본문이 기술된 곳으로 텍스트 영역text area 라고도 한다. 프로그래머가 작성한 프로그램은 코드영역에 탑재되며 탑재된 코드는 읽기 전용으로 처리된다. 자기 자신을 수정하는 프로그램은 존재하지 않기 때문이다.
데이터 영역 data area : 코드가 실행되면서 사용하는 변수variable나 파일 등의 각종 데이터를 모아놓은 곳이다. 데이터는 변하는 값이기 때문에 이곳의 내용은 기본적으로 읽기와 쓰기가 가능하다.
스택 영역 stack area : 운영체제가 프로세스를 실행하기 위해 부수적으로 필요한 데이터를 모아놓은 곳이다. 예를 들어 프로세스 내에서 함수를 호출하면(function call)함수를 수행하고 원래 프로그램으로 되돌아 올 위치를 이 영역에 저장한다. 스택 영역은 운영체제가 사용자의 프로세스를 작동하기 위해 유지하는 영역이므로 사용자에게는 보이지 않는다.
2. 프로세스의 생성과 복사
: 프로세스는 프로그램을 실행할 때 새로 생성된다. 사용자가 프로그램을 실행하면 운영체제는 프로그램을 메모리로 가져와 코드 영역에 넣고 프로세스 제어 블록을 생성한다. 그리고 메모리에 데이터 영역과 스택 영역을 확보한 후 프로세스를 실행한다.
그런데 프로세스를 새로 생성하는 방법뿐만 아니라 실행중인 프로세스로부터 새로운 프로세스를 복사하는 방법도 있다.
2.1 fork()시스템 호출의 개념
fork() 시스템 호출은 실행중인 프로세스로부터 새로운 프로세스를 복사하는 함수이다. 커널에서 제공하는 이 함수는 프로세스를 복사하는 일종의 시스템 호출이다. fork() 시스템 호출을 사용하면 실행중인 프로세스와 똑같은 프로세스가 하나 더 만들어진다. 이렇게 복사해서 실행하면 처음 실행하는 속도보다 훨씬 빠르다.
또 다른 예로 구글의 웹브라우저인 크롬에서 어떤 웹사이트를 보다가 ctrl+N을 누르면 크롬 웹페이지가 하나 더 실행된다.
**fork() 시스템 호출**
: fork() 시스템 호출은 실행 중인 프로세스를 복사하는 함수이다. 이때 실행하던 프로세스는 부모 프로세스, 새로 생긴 프로세스는 자식 프로세스로서 부모-자식 관계가 된다.
2.2 fork() 시스템 호출의 동작 과정
fork() 시스템 호출을 하면 시스템 내부에서는 어떤 일이 일어날까?
fork() 시스템 호출을 하면 프로세스 제어 블록을 포함한 부모 프로세스 영역의 대부분이 자식 프로세스에 복사되어 똑같은 프로세스가 만들어진다. 단, 프로세스 제어 블록의 내용 중 일부가 변경되는데 변경되는 부분은 다음과 같다.
프로세스 구분자(PID)가 바뀐다. 이는 부모와 자식의 주민등록번호가 다른 것과 마찬가지이다.
부모 프로세스와 자식 프로세스가 차지하고 있는 메모리의 위치가 다르므로, 메모리 관련 정보가 바뀌게 된다.
부모 프로세스 구분자PPID와 자식 프로세스 구분자CPID가 바뀐다(둘은 부모-자식 관계이기 때문)
2.3 fork() 시스템 호출의 장점
프로세스의 생성 속도가 빠르다
추가 작업 없이 자원을 상속할 수 있다
시스템 관리를 효율적으로 할 수 있다
2.4 fork() 시스템 호출의 사용
: fork() 함수는 unistd.h 헤더를 포함한 후 사용가능하다. fork() 문은 부모프로세스에 0보다 큰 값, 자식 프로세스에 0을 반환한다. fork()문 이전에 파일을 열거나 변수를 선언하면 이것이 모두 자식 프로세스에 상속된다.
3. 프로세스의 전환
3.1 exec() 시스템 호출의 개념
: exec() 시스템 호출은 기존의 프로세스를 새로운 프로세스로 전환하는 함수이다.
fork() : 새로운 프로세스를 복사하는 시스템 호출이다.
exec() : 프로세스는 그대로 둔 채 내용만 바꾸는 시스템 호출이다. exec() 시스템 호출을 하면 현재의 프로세스가 완전히 다른 프로세스로 전환된다.
exec() 시스템 호출을 사용하는 목적은 프로세스의 구조체를 재활용하기 위함이다. 새로운 프로세스를 만들려면 프로세스 제어 블록을 만들고 메모리의 자리를 확보하는 과정이 필요하다. 또한 프로세스를 종료한 후 사용한 메모리를 청소(garbage collection)하기 위해 상위 프로세스와 부모-자식 관계를 만들어야 한다. 이때 exec() 시스템 호출을 사용하면 이미 만들어진 프로세스 제어 블록, 메모리 영역, 부모-자식 관계를 그대로 사용할 수 있어 편리하다. 새로운 코드 영역만 가져오면 되기 때문에 운영체제의 작업이 수월하다.
3.2 exec() 시스템 호출의 동작 과정
exec() 시스템 호출 동작 과정은 간단하다. exec() 시스템 호출을 하면 코드 영역에 있는 기존의 내용을 지우고 새로운 코드로 바꿔버린다. 또한, 데이터 영역이 새로운 변수로 채워지고 스택 영역이 리셋된다. 프로세스 제어 블록의 내용 중 프로세스 구분자, 부모 프로세스 구분자, 자식 프로세스 구분자, 메모리 관련 사항 등은 변하지 않지만 프로그램 카운터, 레지스터 값을 비롯 각종 레지스터와 사용한 파일 정보가 모두 리셋된다. 마치 프로세스를 처음 시작하는 것처럼 내용이 정리된다.
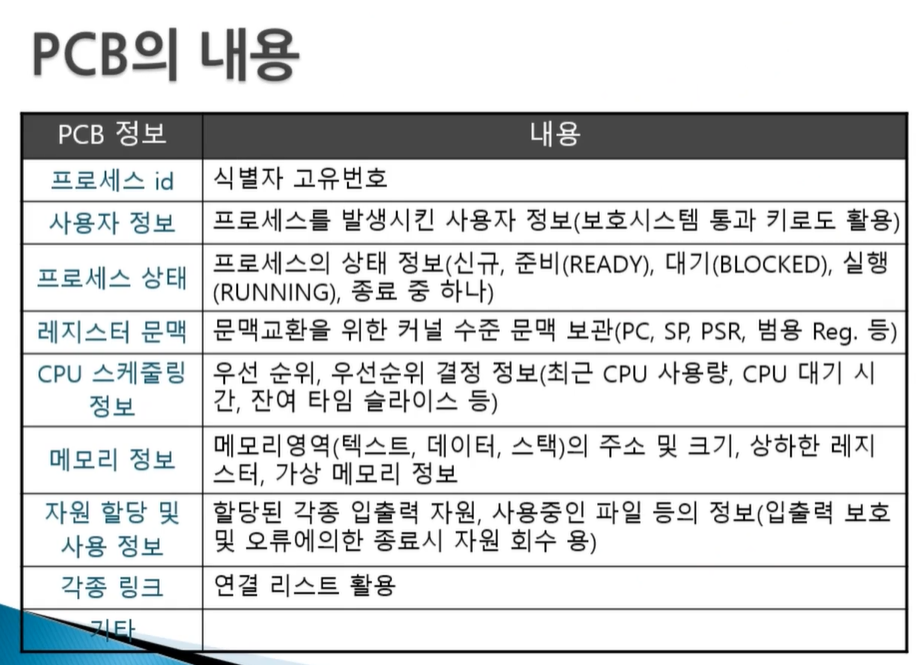
프로세스 제어블록 PCB는 프로세스를 실행하는데 필요한 정보를 보관하는 자료구조로 TCB(Task Control Box)라고도 한다. 모든 프로세스는 고유의 프로세스 제어 블록을 가지며, 프로세스 제어블록은 프로세스 생성 시 만들어져서 프로세스가 실행을 완료하면 폐기된다. 프로세스 제어 블록에 저장되는 정보는 무엇일까?
1. 포인터 : 프로세스 제어블록의 첫번째 블록에는 포인터가 저장된다. 준비 상태나 대기 상태는 큐로 운영되는데, 프로세스 제어블록을 연결하여 준비 상태나 대기 상태의 큐를 구현할 때 포인터를 사용한다.
2. 프로세스 상태 : 프로세스 상태에는 생성, 준비, 실행, 대기, 보류 준비, 보류 대기 등이 있다. 이는 프로세스가 현재 어떤 상태에 있는지를 나타내며, 프로세스 제어블록의 두번째 블록에 저장된다.
3. 프로세스 구분자 : 운영체제 내의 여러 프로세스를 구별하기 위한 구분자를 저장한다. (PID)
4. 프로그램 카운터 : 다음에 실행될 명령어의 위치를 가리키는 프로그램 카운터 값을 저장한다. (레지스터의 한 종류)
5. 프로세스 우선순위 : 프로세스 상태를 설명할 때 이해를 돕기위해 대기 상태에서 기다리는 모든 프로세스가 한 줄로 서있다고 가정했다. 이는 대기 큐waiting queue가 하나라는 의미로, 모든 프로세스의 우선 순위가 같다고 본 것이다. 그러나 실제로는 프로세스의 중요도가 각각 다르다. 사용자 프로세스보다 중요도가 큰 커널 프로세스는 우선순위가 높고, 사용자 프로세스끼리도 우선순위가 다르다.
다양한 우선순위의 프로세스가 대기 상태로 들어오기 때문에 대기 상태의 큐도 우선순위별로 따로 운영된다. 다시 말해, 우선순위에 따라 프로세스 제어블록들이 여러 줄로 서 있다. CPU스케쥴러가 준비상태에 있는 프로세스 중 실행상태로 옮겨야 할 프로세스를 선택할 때는 프로세스 우선순위를 기준으로 삼는다. 높은 우선순위의 프로세스가 낮은 우선순위의 프로세스보다 먼저 실행되고 더 자주 실행된다.
6. 각종 레지스터 정보 : 프로세스 제어블록에는 프로세스가 실행되는 중에 사용하던 레지스터, 누산기(accumulator), 색인 레지스터(index register), 스택 포인터(stack pointer)와 같은 레지스터의 값이 저장된다. 이전에 실행할 때 사용한 레지스터의 값을 보관해야 다음에 실행할 수 있기 때문에 자신이 사용하던 레지스터의 중간값을 보관한다.
7. 메모리 관리 정보 : 프로세스 제어 블록에는 프로세스가 메모리의 어디에 있는지 나타내는 메모리 위치 정보, 메모리 보호를 위해 사용하는 경계 레지스터 값과 한계 레지스터 값 등이 저장된다. 그 외에 세그먼테이션 테이블(segmentation table), 페이지 테이블(page table)등의 정보도 보관한다.
8. 할당된 자원 정보 : 프로세스를 실행하기 위해 사용하는 입출력 자원이나 오픈 파일 등에 대한 정보를 말한다. 어떤 프로세스가 하드디스크에 저장된 파일을 열어서 작업하거나, 음악을 출력하기 위해 사운드카드에 접근하고 있다면, 파일이나 사운드카드에 대한 정보가 필요한데, 이러한 정보를 프로세스 제어 블록에 저장한다.
9. 계정정보 : 계정번호, CPU 할당시간, CPU 사용시간 등
10. 부모 프로세스 구분자와 자식 프로세스 구분자 : ParentPID(PPID), ChildPID(CPID)
**포인터의 역할**
프로세스 제어블록의 맨 위에 있는 포인터의 역할을 알아보자. 입출력이 완료되기를 기다리는 프로세스는 대기상태로 모인다. 시스템 내에는 다양한 종류의 입출력장치가 있기 때문에 대기상태로 모이는 프로세스도 다양하다. 그런데 이것들을 하나로 모아놓으면 관리하기가 불편하다. 예를 들어, 하드디스크로부터 인터럽트가 들어왔을 때, 대기상태의 프로세스가 한군데에 모여 있다면 해당 프로세스를 찾기 위해 대기 상태의 모든 프로세스를 뒤져야 한다. 이러한 불편함이 없도록 대기 상태에는 같은 입출력을 요구한 프로세스끼리 모아놓는다.
**문맥 교환**
1. 문맥 교환의 의미
문맥 교환context switching은 CPU를 차지하던 프로세스가 나가소 새로운 프로세스를 받아들이는 작업을 말한다. 이때 두 프로세스 제어 블록의 내용이 변경된다. 실행상태에서 나가는 프로세스 제어 블록에는 지금까지의 작업 내용을 저장하고, 반대로 실행상태로 들어오는 프로세스 제어 블록의 내용으로 CPU가 다시 세팅된다. 이와 같이 두 프로세스의 프로세스 제어 블록을 교환하는 작업이 문맥 교환이다.
2. 문맥 교환의 절차
실행상태에 있는 프로세스 P1이 자신에게 주어진 시간을 다 사용하여 타임아웃이 되면, P1의 프로세스 제어 블록에 현재까지의 작업결과가 저장되고, P1은 준비상태로 쫓겨난다. 준비 상태에 있던 프로세스 P2가 실행상태로 가면, CPU의 레지스터가 P2의 프로세스 제어 블록 값으로 채워진다.