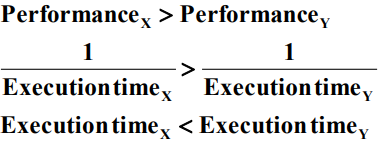고정 사이즈의 윈도우가 이동하면서 윈도우 내에 있는 데이터를 이용해 문제를 풀이하는 알고리즘을 말합니다.
배열이나 리스트의 요소의 일정 범위의 값을 비교할때 사용하면 매우 유용합니다.
원래 네트워크에서 사용되던 알고리즘을 문제풀이에 응용한 경우라고 할 수 있습니다.
Go Back N
GBN에서 송신자는 송신한 패킷에 대한 확인 응답 없이, 최대 N개의 패킷을 전송할 수 있습니다.
이를 크기가 N인 윈도우로 표현합니다. (N은 흐름제어와 혼잡제어에 의해 조정된다.)
송신한 패킷이 올바르게 수신측에 도착하여 확인 응답을 받으면, 윈도우는 앞으로 이동하고 다음 패킷을 전송합니다.
이를 슬라이딩 윈도우 프로토콜(sliding-window protocol)이라고 부릅니다.
Selective Repeat
Selective Repeat 프로토콜은 손실 되거나 손상된 패킷에 대해서만 재전송 합니다.
GBN처럼 윈도우 크기만큼 패킷들을 전송하지 않는다. 즉, 불필요한 재전송을 하지 않습니다.
GBN 수신자는 누적확인 응답을 하지 않는다. 순서번호가 앞서는 패킷이 도착하면 그대로 수신합니다.
📌 TCP
TCP
TCP (전송 제어 프로토콜)는 두 개의 호스트를 연결하고 데이터 스트림을 교환하게 해주는 네트워크 프로토콜입니다.
3 way handshake
3-way-handshake는 신뢰적인 데이터 전송을 보장하기 위해 3개의 패킷을 주고 받으며 사전 연결 설정을 수립하는 과정입니다.
4 way handshake
4개의 특별한 패킷을 주고 받으며 TCP 연결을 해제하는 방법입니다.
TCP 빠른 재전송
타임아웃에 의한 재전송의 문제점은 타임아웃의 주기가 때때로 길다는 점입니다.
다행히도 송신자는 중복 ACK 수신을 통해 타임아웃이 일어나기 전에 송신된 패킷이 손실되었음을 인지할 수 있습니다.
수신자는 순서가 올바르지 않은 세그먼트를 수신하면, 마지막으로 올바르게 수신된 세그먼트에 대한 ACK를 송신측에 전송합니다.
송신자가 만약 같은 세그먼트에 대해 3개의 중복된 ACK를 수신하게 되면
해당 ACK에 해당하는 세그먼트가 손실되었음을 인지하게 재전송을 하게됩니다.
이는 타임아웃에 상관없이 이루어지므로 빠른 재전송이라고 할 수 있습니다.
Congestion control
네트워크 혼잡을 줄이기 위해 패킷 송신 속도 즉, 송신측의 윈도우 크기를 조절하는 것을 말합니다.
네트워크가 혼잡해지면 지연이 커지고 패킷 손실이 발생합니다.
패킷이 지연되거나 손실되면 재전송이 이루어지는데, 이렇게 되면 네트워크는 더욱 혼잡해집니다.
Flow control
송신자가 패킷을 보내는 속도가 수신자가 수신버퍼에서 패킷을 읽어드리는 속도보다 빠른경우
수신 버퍼에 오버플로우가 일어나 패킷을 수신할 수 없는 상황이 발생합니다.
이를 방지하기 위해 송신자가 패킷 송신 속도를 조절하는 것. 즉 송신측의 윈도우 크기를 조절하는 것을 flow control이라고 합니다.
TCP와 달리 UDP는 연결 지향형이 아니고, 신뢰적인 데이터 전송을 보장하지 않습니다.
단지 체크섬을 통해 수신된 패킷의 오류 여부 정도만을 알 수 있습니다.
하지만 UDP는 TCP에 비해 기능이 별로 없기 때문에 적은 오버헤드로 빠른 전송이 가능 합니다.
따라서 일정 전송 요구량이 있고, 조금의 데이터 손실을 허용하는 스트링 애플리케이션에 어울립니다.
DNS 서버도 UDP를 사용합니다.
UDP의 장단점
UDP의 장점은 비연결형 서비스이므로 TCP에 비해 속도가 빠르며 네트워크 부하가 적습니다.
또한, 1:1, 1:N, N:N 통신이 가능합니다.
단점으로는 데이터의 신뢰성이 없습니다.
UDP 체크섬
UDP 체크섬은 UDP 세그먼트의 오류 검출을 위해 사용되는 것 입니다.
체크섬은 송신할 세그먼트를 16비트 단위로 나누고, 모두 더한 다음 1의 보수를 취해서 만들어 집니다.
이 체크섬을 세그먼트와 같이 전송 합니다.
수신자는 수신된 세그먼트에 대해 동일한 방식으로 체크섬을 만들고
헤더의 체크섬과 일치 하는지 비교함으로써
수신된 세그먼트의 오류를 검출할 수 있습니다.
전송 후 대기 프로토콜
전송후 대기 프로토콜은 패킷을 전송하고 그 패킷에 대한 수신 확인 응답을 받고나서, 다음 패킷을 전송하는 방식 입니다.
이러한 방식은 네트워크 링크 이용률이 낮아 속도가 느리다는 단점이 있습니다.
파이프라인 프로토콜
파이프라이닝 프로토콜은 전송한 패킷에 대한 수신 확인 응답을 받지 않고도,
여러 개의 패킷을 연속으로 전송하여 링크 이용률과 전송 속도를 높이는 프로토콜 입니다.
DNS는 도메인 네임을 IP 주소로 변환해주는 프로토콜이자 계층형 구조로 구현된 분산 데이터베이스 입니다.
호스트가 도메인 네임에 대한 IP 주소를 요청하면 DNS는 계층 질의를 통해 IP 주소를 얻어다가 줍니다.
만약 로컬 DNS에 해당 IP 주소가 캐싱되어 있다면 바로 받습니다.
빠른 응답을 제공하기 위해 DNS는 UDP 기반으로 동작하고 DNS 서버들은 요청 정보를 캐싱해둡니다.
DNS 작동 방식
사용자가 웹 브라우저에서 도메인 이름을 입력합니다.
브라우저는 해당 도메인을 DNS 서버에 보내서 IP 주소를 요청합니다.
DNS는 IP주소를 찾아서 브라우저에 보내고, 브라우저는 IP주소를 통해 서버에 요청을 보냅니다.
DNS 질의 종류
재귀적 질의는 도메인 네임에 해당하는 IP주소를 통해 DNS가 다른 DNS에게 재귀적으로 IP 주소를 물어보는 것을 뜻합니다.
반복적 질의는 IP 주소를 찾기 위해 반복적으로 질의하는 것입니다.
로컬 DNS가 루트 DNS에게 IP주소를 물어봤는데 없으면 TLD DNS에게 물어보고 또 없으면
authoriative DNS에 반복적으로 물어보는 것을 예시로 들 수 있습니다.
DNS 서버에게 IP 주소를 요청할 때, UDP를 사용하는 이유
DNS는 신뢰성보다 속도가 더 중요한 서비스이기 때문에 연결 설정에 드는 비용이 없는 UDP를 사용합니다.
DNS는 연결 상태를 유지할 필요가 없고, TCP보다 많은 클라이언트를 수용할 수 있는 UDP를 사용합니다.
DNS 레코드
DNS 서버는 데이터베이스 서버의 한 유형이며, 클라이언트로부터 질의를 받았을 때 그에 맞는 데이터를 응답해야 합니다.
데이터베이스의 한 항목(row)을 DNS 서버에서는 리소스 레코드라고 부릅니다.
- A
- IP 주소와 도메인 주소를 매핑할 때 사용하는 레코드입니다.
- CNAME
- 기존 도메인에 별명을 붙인 레코드입니다.
- TXT
- 텍스트를 입력할 수 있는 레코드입니다.
- 개인 프로젝트에서 무료 SSL 인증서를 등록하는 과정에서 사용하였습니다.
쿠버네티스는 컨테이너 애플리케이션을 분산 환경에서 운용 관리하기 위한 오케스트레이션 툴이다. (단어 하나씩 뜯어봤는데도,, 말이 어려워서 기억하기 위해..)
결과적으로는 온프레미스 환경에서 쿠버네티스를 사용할 것이지만, 일단 Azure를 사용해서 클라우드 환경에서 쿠버네티스를 사용해 보겠다!
컨테이너 이미지 빌드와 공개
전체적인 흐름
컨테이너 애플리케이션을 개발하고 운용할 때의 흐름을 알고, 순서대로 진행해 보겠다.
개발 환경 준비 Azure를 실행하기 위해서 IDE나 로그인 등을 해야함
컨테이너 이미지의 작성 및 공유 컨테이너를 동작시키려면 애플리케이션을 움직이기 위한 것들이 이미지로 있어야 한다. 필요한 것들로는 바이너리, OS, 네트워크 같은 설정들을 이야기 한다. 만약 도커일 경우에는 Dockerfile이라는 텍스트 파일에 구성을 기술하고, 이것을 빌드하면 빌드된 것을 실행 환경에서 이용 가능한 레포지토리로 공유한다. (마치 로컬에서, github에 커밋을 하고 다른 컴퓨터에서 pull해서 사용하는 느낌이였다.)
클러스터 작성 (실제 환경 작성) 실제로 컨테이너 애플리케이션을 작동시키는 서버를 구축해야 한다. 개발 환경이나 테스트 환경에서는 로컬 머신으로 작동시키지만, 서비스 공개할려면 클라우드 서비스를 사용하든지, 실제 서버 컴퓨터(온프레미스) 환경이 있어야 한다.
[ 1번의 진행과정 ]
쿠버네티스 클러스터
쿠버네티스 클러스터란, 쿠버네티스가 분산 환경에서 여러 대의 서버나 스토리지와 같은 컴퓨팅 리소스가 네트워크로 연결된 환경에서 각각 다른 역할을 가지면서 서로 협조해 가며 컨테이너 애플리케이션을 실행시키는 것을 의미한다.
쿠버네티스 클러스터를 만들려면 여러 대의 서버나 가상 머신에 쿠버네티스를 설치하고 네트워크 설정 등을 해야 한다.
클러스터를 쉽게 운용하기 위해서 먼저 Azure 컨테이너 서비스를 이용해보겠다!
먼저 Azure에 개인 계정을 만들어야 된다. (나는 건국대학교 학생 계정을 이용해서 1년 무료로 사용할 수 있다고 해서 학교 계정을 사용하였다)
Azure 포털 사이트에서도 cli 창을 띄울 수 있었는데, 리눅스 명령어도 익힐 겸 Azure CLI 명령을 설치해서 할 수 있었다. (사이트에서 MSI 인스톨러로 다운받았다.)
만약 Azure에 로그인을 하면 cmd창을 켜서 az login을 입력하면, redirect페이지가 나오고 로그인이 된다.
4. Azure의 서비스를 이용하기 위해 리소스 프로바이더도 할당한다.
Azure 리소스 프로바이더를 활성화해야 하는 이유 Azure에서 리소스 프로바이더를 활성화해야 하는 이유는 해당 리소스를 생성하고 관리, 조작하기 위해서이다. Azure의 각각의 서비스는 Azure Resource Manager(ARM)이라는 것에 의해서 관리되는데, 리소스 프로바이더는 이 ARM에서 각각의 서비스에 대한 API 엔드포인트를 제공한다.
그래서 Azure 리소스를 만들거나 관리하려면 해당 리소스 유형에 대한 프로바이더가 활성화되어 있어야 한다.
예를 들어서 Azure Virtual Machines를 만들려면 Microsoft.Compute 리소스 프로바이더가 필요하다. 이 프로바이더는 Virtual Machine과 관련된 API 엔드포인트를 제공해서, 가상 머신의 생성, 삭제, 업데이트 등의 작업을 수행할 수 있도록 한다.
여기서는 Microsoft.Network, Storage, Compute, ContainerService 모두 활성화시켰다.
kubectl 명령
쿠버네티스 클러스터를 조작하려면 GUI를 사용해도 되는데, 일반적으로는 명령으로 조작한다고 한다.
명령으로 조작하기 위해서는 kubectl을 사용한다. kubectl 명령은 쿠버네티스 클러스터의 상태를 확인하거나 구성을 변경하기 위한 것이다. 개발을 하는 클라이언트 머신에 설치하면 된다.
서버를 도커를 사용해서 배포해야 한다, 도커를 사용하면 신세계를 경험할 수 있다. 이러한 말만 많이 듣고, 정작 배포할 때는 배포파일을 명령어로 EC2로 이동시켜서 실행해 본 경험 밖에 없어서 도커에 대한 개념을 알고 배포까지 해보려고 한다.
먼저, 이 글은 도커에 대한 개념을 공부한 내용이다.
도커의 정의
도커란 개발자가 컨테이너화된 애플리케이션을 빠르게 빌드, 테스트 및 배포할 수 있게 해주는 가상화 도구 라고 한다.
이 말만 들어서는 정의 안에 너무 모르는 말들이 많았다. 가상화, 컨테이너에 대한 용어부터 알고 가겠다.
가상화
가상화란 하나의 물리적 서버 호스트에서 여러 개의 서버 운영 체제를 게스트로 실행할 수 있게 해주는 아키텍쳐이다.
내 물리적 서버는 현재 윈도우를 사용하고 있는데, 우분투나 다른 운영체제를 사용해야 할 경우가 생긴다. 그 때 가상화라는 것을 사용하는 것이다.
가상화가 필요한 이유는 서버의 성능을 나누어서 사용하기 위해 필요하다. 하나의 서버를 나누어서 성능을 분산시키고, 분산된 서버들은 각기 다른 서비스를 수행한다. 즉, 내가 여러 서비스를 실행하고 싶을 때, 컴퓨터를 여러 대 사는게 아니라 하나의 서버에서 서버를 여러 개 쓰는 효과를 누리게 된다.
가상화를 통해서 사용자가 많은 서비스에는 많은 자원을 할당해주고, 적은 서비스에는 적게 할당해 줄 수 있다.
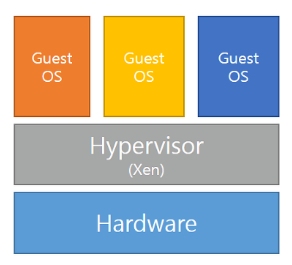
이런 가상화를 구현해주는 기술은 Hypervisor라는 가상화 기술을 사용한다. Hypervisor는 여러 개의 운영체제를 하나의 Host OS에 생성해서 사용할 수 있게 해주는 소프트웨어이다. 여러 개의 운영체제는 하나 하나가 가상머신 이라는 단위로 구별이 된다.
그럼 Hypervisor는 os들에게 자원도 나누어주고, os들이 요청하는 커널 번역해서 하드웨어에게 전달도 해준다. Hypervisor에 의해 생성되고 관리되는 운영체제는 guest 운영체제라고해서, 각 guest 운영체제는 완전히 독립된 공간과 시스템 자원을 할당받아서 사용하게 된다.
그럼 위에서 얘기했던 도커를 사용하는 이유랑 같은거 같다. 그럼 가상화의 어떠한 단점 때문에 도커가 나오게 된 것일까?
가상화를 사용하는 툴은 Virtual Box나 VMWare 같은 것들이 있다. 근데 이러한 가상화 툴의 단점은 Hypervisor를 반드시 거쳐야 하므로 일반 호스트에 비해서 성능 손실이 발생한다. 그리고 가상머신에 guest 운영체제를 사용하기 위한 라이브러리, 커널 등을 전부 포함해서 배포할 때 크기도 커진다.
즉, 가상머신을 완벽한 운영체제를 생성할 수 있는 장점이 있긴 하지만, 성능이 떨어지고 용량 문제도 생기는 것이다.
이를 해결하기 위해 나온 것이 컨테이너의 개념이다.
컨테이너
컨테이너란 가상화된 공간을 생성하기 위해서 리눅스 자체 기능을 사용해서 프로세스 단위의 격리환경을 만든다. 여기서 격리 환경을 컨테이너라고 하게 된다.
컨테이너의 사전적 의미는 어떤 물체를 격리하는 공간으로 이걸 소프트웨어에서 사용할 때는 파일 시스템+격리된 자원 + 네트워크를 사용할 수 있는 독립된 공간이라는 의미로 가져온다.
우리가 아는 컨테이너는 스프링에서 자주보던 서플릿 컨테이너나 IoC 컨테이너, Bean 컨테이너 같은 것들이다. 이런 컨테이너들은 컨테이너에 담긴 것들의 라이프 사이클을 관리해준다. 어떤 것들을 생성하고, 운영하고, 제거까지 컨테이너가 관리해주는 것이다.
그럼 도커에서의 컨테이너란 이미지의 목적에 따라서 생성되는 프로세스 단위의 격리환경으로 프로세스의 생명 주기를 관리하는 환경을 제공해준다.
컨테이너 안에는 애플리케이션을 구동하는데 필요한 라이브러리와 실행 파일만 존재해서 이미지로 만들게 되면, 이미지 용량도 매우 적다. 여기서 이미지란 컨테이너를 만드는 데 필요한 모든 지시사항과 dependency를 포함하는 템플릿으로 ‘컨테이너를 만들어주는 틀’이라고 생각하면 된다.
이 컨테이너를 다루는 기술 중 하나가 도커가 되는 것이다. (도커 이외에도, Red Hat Openshit, ECS, 이런 것들이 있다고 한다..)
Q> 그럼 컨테이너를 왜 써야 하는가? A> 이미지의 실행, 배포가 빨라지고 Host와의 격리를 통해서 독립된 개발을 할 수 있다.
여기서 도커는 컨테이너 기술에 여러 기능을 추가한 오픈소스 프로젝트인 것이다.
도커
그럼 컨테이너를 도커는 어떻게 관리하는 것일까? 도커는 Docke Engine을 통해서 컨테이너를 관리할 수 있다. 도커 엔진은 유저가 컨테이너를 쉽게 사용할 수 있게 하는 주체로 컨테이너의 라이프 사이클을 관리해주고 이미지, 볼륨, 네트워크 까지 관리해준다.
그래서 최근 자바 프로젝트는 SpringBoot + Docker + EC2 조합으로 환경을 구성한다고 한다. 그럼 도커 시스템을 구축하고 배포하는 방법을 보겠다.
도커를 통해서 배포하기
먼저 도커를 설치해야 한다. 나는 도커 데스크톱까지 설치해주었다.
그리고 테스트할 SpringBoot 프로젝트를 만들었다. 해당 프로젝트에 Dockerfile을 만들어서 설정을 해주면 된다. 제일 간단한 설정만 따와서 해보았다.
FROM amazoncorretto:11
COPY build/libs/*.jar dockerpr-0.0.1-SNAPSHOT.jar
ENTRYPOINT ["java", "-jar", "dockerpr-0.0.1-SNAPSHOT.jar"]
해당 설정을 해준 뒤, Docker Image를 만들어야 한다. Intellij에서 터미널에서 제일 루트 위치에서 실행시켜주면 된다.
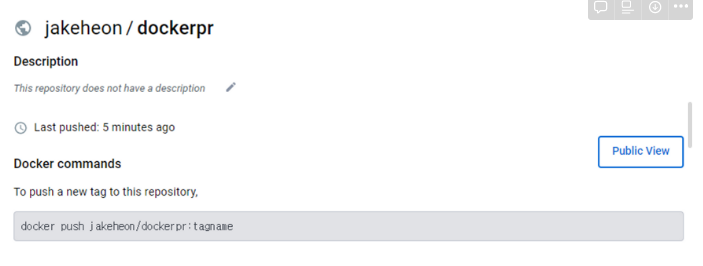
docker build -t jakeheon/dockerpr
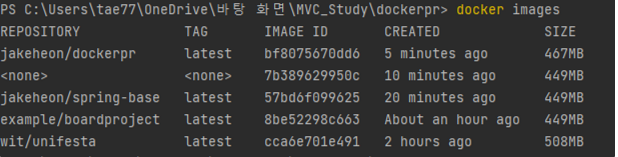
그리고 docker images로 도커 이미지가 생성되었는지 확인하면 된다. (잘 안되어서 몇 번 하다보니까 이미지가 잔뜩 생겼다.. 오류는 docker에 로그인을 하지 않았거나(docker login) 파일 위치가 잘못되었거나 하는 경우였다)
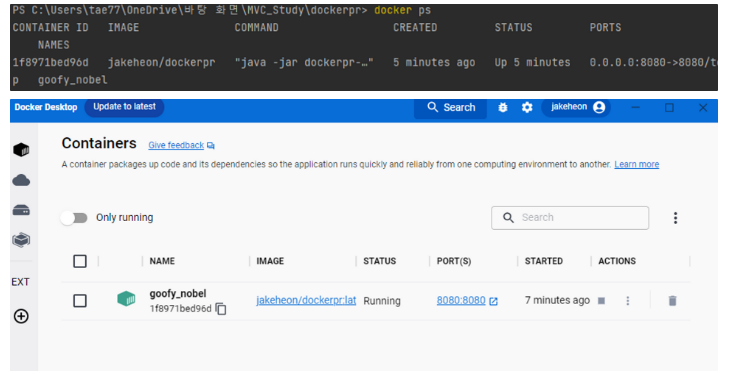
그리고 Container를 실행해준다. Host Port와 Container Port를 연결할려고 port를 2개 입력하였다.
우리는 컴퓨터의 한 측면의 개선이 전체 성능을 개선 크기에 비례하여 증가시킬 것으로 기대하지만, 실제로는 그렇지 않다.
만약에 어떤 프로그램이 실행되는데 100초 정도 걸린다고 가정하자. 곱하기 하는게 80초 정도 걸린다. (나머지는 따른거)그래서 곱하기가 많이 차지하니까 곱하기에서 성능을 향상 시키려고 하였다. 만약 4배정도 빠르게 실행하고 싶으면 곱하기 성능이 얼마정도 빨라져야 될까??-> 그럼 변수로 두고 생각해보자. Tmultiply(Tm이라고 하겠다)는 80초이고, Tother(To)는 20초이다. 그리고 Tnew는 4배정도 빨라져야 되기 때문에 100/4 = 25s가 된다. - Tm = 80s- To = 20s- Tnew = 25sTnew = To + Tm/speedUp25 = 20 + 80/x -> x = 80/5 = 16. 즉, speed up이 16배 정도 되어야 전체는 4배정도 빨라질 수 있다.
그럼 5배정도 빠르게는 할 수 있을까? 80/speedup + 20 = 20이 되어야 하는데 그렇게 될려면 speedup이 무한대가 되어야한다. 실제로 불가능하다는 이야기이다.