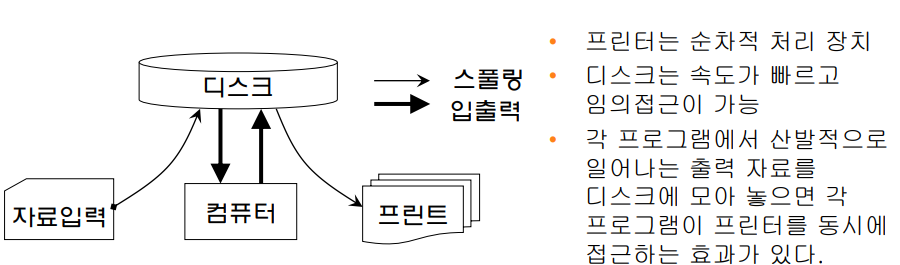
1은 User Space와 Kernel Space를 제어하는 System call 부분이고, HW Interface가 아래에 있다.
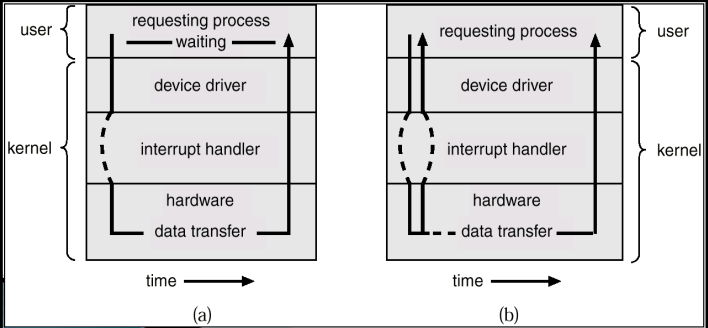
1번 화살표 : 그림은 부팅이 끝나 이미 각종 interrupt에 ISR의 시작주소가 interrupt vector table 또는 interrupt descriptor table인 IDT에 이미 등록되어 있는 상태. IDT가 있고 ISR의 시작주소가 초록색 박스에 쭉 등록되어 있다. 현재 이 상태에서 2층에 있는 응용 프로그램이(여기서는 read(buf) 파란색 박스) 1층에 있는 커널에게 read라는 시스템 콜을 호출하였다. 단 read라는 것은 데이터를 얻어오는 것이다. 사용자 공간내에 이를 위한 버퍼를 미리 잡아두어야한다. 이에 대한 포인트인 buf를 read호출 시 인자로 넣어주었다. 이 호출이 trap을 거쳐 커널내의 정보를 따라서 해당 디바이스 드라이브 내의 실제 구현 함수인 sys_read()까지 다다른 상태라고 보자.
2번 : 디바이스 드라이버 내의 sys_read() 함수는 응용프로그램이 요청하는 데이터를 예를 들어서 하드웨어의 장치제어기로부터 받아와서 잠시 저장하기 위한 용도로 커널 내의 버퍼를 하나 할당받아야 한다. User Space의 메모리 공간하고 Kernel Space의 메모리 공간은 다르기 때문에 장치제어기가 바로 UserSpace의 버퍼에 copy하지는 못한다. 그 전에 kernel이 갖고 있는 space에 copy를 먼저 해놓은 다음에 kernel에 의해서 copy를 해줘야하는 구조이다. kernel내의 버퍼를 만들어 놓고, 그 버퍼를 pointing하는 변수의 이름이 ptr이라는 것이 된다. 그런 후, 2번 레지스터와 같이 장치 제어기의 명령 레지스터에 ptr이라는 값과 함께 하드디스크의 읽기 명령을 기록을 한다. ptr를 넘겨주는 이유는 장치 제어기가 버퍼에 써야하기 때문에 주소도 같이 넘겨주어야 하기 때문에 그렇다. 명령 레지스터에 기록을 한다 라고하였는데 그 이유는 메모리 mapped I/O를 사용하고 있기 때문에 명령 레지스터에 상응하는 메모리 상의 주소에 read라는 시스템 콜에 해당하는 장치 제어기로의 명령 코드를 기록함으로써 명령을 내리기 때문에 그렇다. 명령을 내리는 것은 기록하는 것이다. 그럼 ptr값은 왜 같이 넘겨주었을까? 장치제어기가 DMA를 할 때, 그리로 직접 접근할 수 있도록 시작 주소를 알려놓게 위함. 그럼 이 시점에서 어떤 일이 벌어질까? 명령이 내려갔으니까, 즉 장치제어기가 명령 레지스터를 통해 명령을 받았으니까 곧바로 하드디스크의 해당 블록을 찾아서 읽어오도록 하는 물리적인 동작을 시작시키게 될 것이다. 장치제어기의 물리적인 하드디스크를 동작시키기 시작했다는 소리이다.
상태레지스터는 생략되어있다.
3번 : CPU는 더 이상 할 일이 없으므로 하드디스크 작업이 끝날때까지 기다려야 한다. 여기서 busy waiting으로 기다리면 성능이 떨어질 것이고, 따라서 디바이스 드라이버 상의 코드로 볼 때, 2번 화살표 작업을 수행하고 난 다음에는 3번과 같이 Sleep()을 하게 된다. Sleep함수의 내부에 들어가보면 결국에는 이 프로그램이 Sleep상태로 들어가면서 이제는 CPU가 수행시킬 다른 프로세스를 선정하기 위한 스케쥴링 함수를 불러오게 된다. 그럼 어떻게 될까? 스케쥴함수(Sched())에 의해 선정된 다른 프로세스가 CPU의 문맥교환이라는 것을 통해서 그 다른 프로세스를 수행하게 된다. 그 동안에 이 프로세스는 Sleep()상태에 있고 안 돌고 있는 것이다.
4번 : 그렇게 CPU가 다른 프로세스를 진행하고 있는 동안에 장치 제어기는 하드 디스크를 물리적으로 구동해서 결국 응용프로세스가 read해 오고자 하는 블록을 찾아내서 자료 레지스터로 읽어들일 것이다. 여기서 자료레지스터는 장치 제어기 내의 저장 공간으로 보아도 된다. 이렇게 데이터가 준비가 되면, 2번 작업을 통해 전달받은 ptr 주소값에 해당하는 메인 메모리의 주소로부터 시작해서 그 데이터를 전달하게 된다. 이 전달하는 과정에서 바로 DMA가 사용된다는 것인데, 블록 데이터이기 때문에 블록을 옮기기 위해서 CPU가 간섭할 필요가 없고, 블록 단위로 바로 장치제어기에서 Device Driver의 버퍼로 copy되게 하기 위해서 DMA를 사용한다.
5번 : 4번이 끝나고 나면 device driver내의 버퍼에 해당 자료가 와 있는 상태가 되는 것이다. 이제 device driver가 깨어날 시점이 된 것이다. 그럼 device driver가 ptr저기 다음 라인을 실행 시키게 되는 것이다. 그런데 현재 sleep상태라는 것이다. 그러면 어떻게 속개될 수 있도록 장치제어기가 작동하느냐, 바로 장치 제어기가 DMA 끝났읍니다 하고 interrupt를 CPU에게 걸어준다. interrupt는 다수준 인터럽트로 인터럽트 번호나 masking이 동반되어 결국 IDT에 기록된 해당 디바이스 드라이브 내의 ISR 처리 함수로 jump가 되는 것이다.
6번: 하드웨어의 도움을 받아서 IDT에서 해당 Device Driver내에 위치한 ISR의 시작주소를 알아낼 수가 있고, 그 시작주소를 PC(Program Counter)에 얹으면 해당하는 ISR로 jump하게 된다. 이렇게 호출된 ISR은 interrupt처리에 필요한 작업과 아울러서 궁극적으로 아까 sleep상태로 들어간 프로세스(아까 read프로세스)를 깨우는 작업을 하게 된다.
7번 : 이를 위해서 프로세스를 스케쥴링 queue에 넣게 된다. 이렇게 스케쥴링 queue에 들어가면 시점이 문제이지 언젠가는 프로그램이 속개된다. 결국 sleep상태로 들어간 프로세스가 wake-up되는 것이다. 이렇게 wakeup이 되고나면 시간이 얼마 지났는지 모르지만 결국 device driver코드 상으로 볼 때 아까 3번에서 호출한 sleep함수가 그제서야 return이 되는 것이고, 그 다음 라인을 수행하게 될 것이다. 거기가 바로, ptr 다음 라인부분이 된다.
그럼 sleep전과 sleep후 달라진 것은 무엇일까? : 시간이 얼마나 지났는지는 모르지만 전에는 버퍼에 데이터가 없었는데 sleep후 꺠어나 보니까 버퍼에 데이터가 생긴 것이다.
8번 : 그럼 곧바로 ptr이 포인팅하는 버퍼 내의 데이터를 사용자 공간으로 copy해준다. (커널 공간과 사용자 공간이 부리되어 있기 때문에 그렇게 해야 넘어간다)
9번 : sys_read()함수는 역할을 다했기 때문에 return과정을 거친다. 리턴과정을 거쳐서 응용 프로그램으로 돌아가는 것이다. 그렇게 되면 응용프로그램 입장에서 보면은 read함수가 끝나고 다음라인으로 속개되는 것이다.
CPU와 장치드라이버(I/O device)만 두고 상태변화 보기
CPU는 그림과 같이 2가지 상태를 반복한다. 즉, 사용자 프로세스를 수행하다가 인터럽트가 들어오면 ISR을 수행하다가 두 상태를 번갈아가면서 계속 진행한다.
반면에 I/O 장치는 쉬다가(idle 상태이다가) 입출력 작업을 받아서 입출력 작업 수행(transferring)하다가 두개의 상태를 반복한다.
소프트웨어로 만들어진 커널이 응용 프로그램에 의하여 문제가 발생하는 경우가 생길 수 있다. 어떻게 이를 하드웨어의 도움을 받아서 protect할 수 있는지에 대하여.
보호(Protect) 대상 : 전부를 보호하는 것이 아니라 근원적인 부분 보호함으로써 직간접적으로 보호
불법(Illegal) I/O : 응용 프로그램이 저지를 수 있는 잘못된 입출력에 대한 보호. 특히 장치제어기를 임의로 접근함으로써 시스템이 오작동하는 방법에 대해서 설명. 불법 메모리 접근 : 응용 프로그램이 다른 응용프로그램이나 커널 프로그램이 탑재된 메모리 영역을 임의로 접근하거나 내용을 변경해서는 안된다. 이를 방지하기 위한 방법에 대해서 설명.
무한 루프(Infinite Loop) : 응용 프로그램이 무한 루프를 돌 경우 CPU가 그 루프만 돌리도록 놓아두면 시스템이 마치 정지한 것과 같을 것이다. 무한 루프를 방지하는 방법에 대해서 설명하겠다.
이중모드와 모드비트
이중모드
커널이랑 커널 모드의 차이점?
커널 : 하드웨어에 접근하기 위한 프로그램
커널 모드 : OS의 함수들
사용자 모드 : 사용자 공간 상의 코드만 실행 가능
인터럽트나 입출력 제어와 관련된 특권명령어(privileged instruction) 수행 불가
특권명령어 수행 시도 시 트랩 발생
메모리 참조 영역도 제한
커널 모드 : 커널 공간 상의 코드만 실행 가능하며 특권명령 사용 가능
사용자 프로그램의 시스템 호출(트랩), 인터럽트 처리, 명령어 수행 오류 발생 시 발생하는 트랩 처리
하드웨어적인 제한이나 보호를 수행치 않음 -> 커널 모드로 수행할 코드를 작성할 경우 매우 조심해야한다.
그전에 이러한 보호 방법의 근본적인 수단인 이중모드에 대해서 먼저 설명하도록 하겠다. 방금 전 3가지 보호대상이 있다고 하였는데, 사실 이 세가지 대상말고도 보호대상은 많을 것이다. 하나하나에 대해 방법 강구하는 것은 소모적이다. 그보다는 근본적이고 이를 통해 여러 문제가 해소되는 방법을 찾아야 한다. 그러한 것으로 이중 모드라는 것이 있다. 즉, 이중모드란 커널모드나 사용자 모드를 분리하는 것을 이야기 하는데, 기본적으로 메인메모리를 사용자 프로그램이 탑재한 사용자 프로그램과 커널 프로그램이 탑재된 커널 프로그램으로 나누어서 CPU가 사용자 프로그램을 수행할 때는 사용자 모드로 수행하도록 하고, 커널 공간의 프로그램을 수행하도록 할 때는 반드시 커널 모드로만 수행하도록 하는 것이다. 왜 이렇게 할까?
- 기본적으로 자원 공유 환경에서는 한 응용 프로그램의 오동작이 다른 프로그램의 오동작을 야기시킬 수 있다. 그러한 오동작에는 잘못된 명령어 사용, 타 영역 접근, 임의로 입출력 장치 제어기에 접근 등, 다양한 것들이 있을 수 있다. 이러한 오동작은 결국 CPU가 프로그램, 즉 코드를 수행할 수 밖에 없기 때문에 벌어지는 건데, 그렇다면 코드 중, 커널이나 다른 프로그램의 오동작을 일으킬 소지가 있는 코드는 커널 내에서만 수행하도록 하면 될 것이다. 따라서, 커널의 그러한 코드들을 함수로 만들어 모아놓고, 응용 프로그램은 필요시에 그 함수를 불러서 쓰면 되는 것이다. 문제가 있을만한 코드는 커널내에 집어넣어놓고, 그것을 사용할 떄는 커널모드에서만 수행될 수 있도록 통제를 한다. 모아만 놓고 응용 프로그램들이 아무렇게 불러쓰도록 하면 서로 여전히 간섭이 생겨서 마찬가지로 문제가 되고, 이렇게 모아놓은 것은 별 소용이 없게 된다. 따라서 이러한 커널 내 함수는 CPU로 하여금 별도에 모드인 커널 모드에서만 수행되도록하고, 응용 프로그램이 그 함수를 호출할 필요가 생기면 커널 모드로의 진입을 허가받아서 수행을 하도록 한다. 그것이 바로 이중 모드(dual mode)를 두는 이유인 것이고, 문제가 될 만한 코드는 커널 내에다 놓고, 그것을 응용프로그램은 호출을 통해서, 여기서 호출은 시스템 콜이 되는 것이다. 트랩이라는 시스템 콜을 통해서 커널 모드로 진입해서야만 수행할 수 있도록 하겠다는 것이다.
이중 모드는 어떻게 실현시킬 수 있을까? 코드를 그렇게 모아놓고 커널모드에서만 실행시키는 것은 좋은 아이디어인데 어떻게 실현??? 이를 위해서 CPU내에 특수 레지스터라는 것들이 있는데, 그 특수 레지스터라는 것들 중에 상태 레지스터라는 것이 있다. 상태 레지스에서 1비트를 모드비트(mode bit)로 사용한다. 모드비트가 0이면 커널 모드이고, 1이면 사용자 모드인 것인데 CPU는 이 모드 비트를 보고 커널모드인 경우에만 소위 말하는 특권 명령어(priviledge Instruction)를 수행한다. 특권 명령어는 다양한데, 입출력 명령이라든지 interrupt관련 명령어, 특히 이 모드 비트 자체를 변경시키는 명령어 등이 특권 명령어에 속한다.
시스템 콜이 호출되면 트랩과정을 거치게 되는데 이 과정에서 모드비트가 커널모드인 0으로 설정이 되는 것이다.(이 부분이 중요) 해당 시스템 콜에서 return을 할 때는 모드 비트를 다시 1로 두는 것이다. 그렇게 해서 return을 하고나면, 응용 프로그램에서는 다시 시스템 콜을 하지 않고는 특권 명령어를 사용할 수 없게 되는 것이다.
이러한 이중모드를 잘 사용하면 몇가지 보호 수단을 잘 사용할 수 있다.
Illegal I/O 차단 (불법 I/O 차단)
모든 I/O 관련 명령을 특권명령어로 함 -> 시스템 호출 즉, 트랩을 통해서만 I/O가 가능하도록 해놓으면 된다.
명령어만 방어해서는 안되고 메모리 영역도 방어해야 한다.
메모리의 커널 영역 보호 수단과 함께 사용
인터럽트 처리 루틴(ISR) 및 장치 구동기 영역
시스템 버퍼 영역
인터럽트 벡터 영역
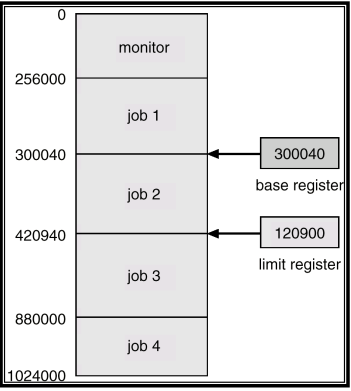
불법 메모리 접근 차단 : 이를 위해 특권 명령어로만 접근할 수 있는 2개의 레지스터를 사용하는 것이다. (Base register와 Limit register)
Base와 Limit 레지스터로 프로그램 공간 정의 - 레지스터의 적재 명령은 커널 모드 명령(특권명령어)
사용자 모드에서 주소 생성시에 범위를 확인, 벗어나면 커널로 트랩함
가상메모리의 경우 메모리 보호가 페이지 단위로 제공됨(맵에 정의된 주소공간 초과 여부를 하드웨어가 차단) ex> UNIX나 LINUX의 경우 "Segmentation Fault"
job2가 메모리 어딘가를 접근하려고 할 때마다 그 대상주소가 이 범위를 벗어나는지를 메모리 관리 유닛이라는 것이 이 두 레지스터를 활용해서 항상 체크하도록 하는 것이다. 그래서 거기서 벗어나게 되면 오류가 발생했고 그 오류가 발생해도 트랩이 걸리는데 오류 발생에 의한 트랩이 걸림으로써 그 오류를 커널이 처리하도록 그렇게 하는 것이다.
가상 메모리의 경우 메모리 보호가 페이지 단위가 되고 이를 보호하기 위한 메커니즘이 하드웨어적으로도 지원이 된다.
Segmentation Fault는 코드에서 포인터를 잘못 사용할 경우, 해당 프로세스에 할당된 메모리 영역을 벗어날 때 발생하는 오류 메시지
Infinite Loop 방지(CPU 보호)
시분할에서는 타이머 인터럽트를 이용하여 타임슬라이스를 구현함으로써 CPU 공유 실형
타이머 또는 클럭으로 하여금 고정된 빈도로 인터럽트를 발생토록 함(예: 1/100초)
타임 슬라이스 실현을 위해 필요한 최고 우선순위 인터럽트 설정, 인터럽트 인터벌 설정 등 모드 특권 명령어로만 수행하도록 함 -> 응용프로그램이 타임슬라이스 인터벌을 악의적으로 수정할 수 없게 되고, 결국 매 타임슬라이스마다 스케쥴링이 이루어짐으로써 무한 루프도는 프로그램만 도는것을 방지
프로그램의 실행 시간을 제야함으로써 한 프로그램의 무한루프 수행(CPU 독점)을 방지
기타 : 몇가지 주제를 두서없이 집고 가겠다
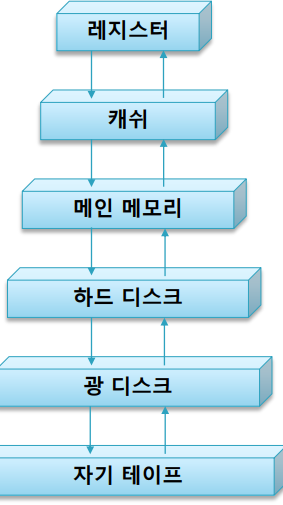
캐시(Cache) : 캐시와 레지스터는 CPU 내에 있고 특히 레지스터는 Core내에 있다. 이 둘은 용량이나 속도면에서 반비례적인 특징이 있다. 레지스터가 가장빠르지만 용량은 제일 적다. 메인 메모리는 용량은 크지만 속도는 느리다. 두 가지 장점을 절충해서 속도도 레지스터에 버금가도록 빠르고 용량도 메인메모리처럼 큰 장치가 있는것같은 착각을 줄 수 있는 방법 -> 캐시가 이것을 위해서 고안됨.
캐시
레지스터와 메모리 사이에 접근시간 또는 데이터 이동속도의 심한 격차가 있을 때에 이의 완화를 위하여 사용
CPU에서 메인메모리에 접근 시에 그 자료를 메모리보다 속도가 빠른 캐시에 복사해놓고 다음번 접근시에 캐시를 방문하여 찾는 자료가 다행히 거기에 있으면 캐시로부터 바로 갖고 가고, 없으면 그때서야 메인메모리에서 가져온다.
CPU가 갖고있는 값이 항상 캐시에 복사되어 있다면 메인메모리의 속도가 캐시만큼 빨라지게 되는 것이고, 용량은 메인메모리의 용량과 다름없어진다.
알고리즘 여부에 따라서는 캐시에서 데이터를 갖고 있을 확률(Hit Ratio)을 90%이상 개선 가능
Hit Ratio가 높아서 100%에 근접할수록 사용하는 효과 극대화 : 가격이 비싸고 용량은 적지만 빠른 속도로 메인메모리의 용량을 사용할 수 있는 효과를 만들어 냄.
캐시 - 메모리 계층구조
-> 개념을 확장하면 시스템 전체의 기억 장치의 성능이 획기적으로 개선될 것이다. 이러한 발상으로 고안된 거시 메모리 계층구조이다. 맨 위에 레지스터, 그리고 메인 메모리 사이에 캐쉬, 그러면 캐쉬와 하드디스크 사이에서 메인 메모리는 캐쉬의 역할을 하지 않을까? 이러한 관점을 확대하서 운영하면 전체적으로 용량은 최하위 기억장치의 용량으로 확대가 되고, 접근 속도는 최상위 기억장치 속도처럼 제공될 수 있다. 그래서 컴퓨터 시스템은 메모리 계층 구조를 갖게 되는 것이다.
부트스트래핑(bootstrapping) : 흔히 부르는 부팅의 풀네임
Bootstrap의 어원적 의미 : 장화 뒤에 고리인데 장화를 신을때 부트스트랩을 혼자 신을 수 있도록 도와주는 것으로 나중에 개념이 확장되어 남의 도움 없이 자기가 스스로 수행한다는 의미. 장화에 달려있다는 점이 중요한데 이래서 운영체제의 관점에서 볼 때 운영체제의 시동을 운영체제 일부 기능이 스스로 수행한다는 과정을 뜻하는 용도.
부팅 시퀀스 - 시스템에 따라 차이가 크겠지만 원론적에서 아래와 같다. : "process of chain loading"
전원이 처음들어오면 메인 메모리에는 아무것도 없다.(volatile memory이기 때문에) 부팅을 시작시키는 조그마한 프로그램이라도 어딘가에 있어야 그것으로부터 부팅과정을 시작할 수 있게 된다. 그 조그마한 프로그램은 volatile 메모리에 있으면 안되고, 비휘발성 메모리에 있어야 한다. 그것의 예가 ROM이다. ROM에 들어있는 20~30바이트의 간단한 프로그램(롬 로더)를 제일 먼저 수행한다.
롬 로더는 DMA를 이용해서 하드디스크 0번 섹터(부트섹터)에 존재하는 마스터 부트 레코드로부터 부트스트랩 로더의 첫번째 블록을 읽어, 메인 메모리에 적재한 후 이 첫번째 블록으로 점프(첫번째 블록의 시작주소)하여 역할을 끝냄 -> 롬로더의 역할은 끝남 -> 부트스트랩 로더의 첫번째 블록이 시작됨.
첫번째 블록이 수행되면 그 첫번째 블록은 부트스트랩 로더의 나머지 부분을 순차적으로 끌어서 적재하게 된다.
그렇게 나머지 부분의 적재가 끝나면 자신을 메모리의 상위 장소로 옮긴 후 전체를 실행한다. 그렇게되면 커널 프로그램을 읽어들여서 하위 기억장소에 다시 적재하게 되는 것이다. 부트스트랩의 역할은 커널 프로그램을 하위장소로 읽어들여서 적재하는 것이다.
부트스트랩은 이제 커널 적재가 끝나면 약속된 장소로 점프하여 커널을 시작시킨다. ---> chain loading 방식(아주 작은 프로그램에서 실행하여 다음 것을 로딩하고 그리고 그리로 점프하는 과정을 연쇄적으로 실행해서 운영체제 전체를 실행하게 되는 것이다.)으로 이루어진다.
모노리틱 커널 vs 마이크로 커널 : 커널의 구성상의 특징을 지칭하는 것이다.
모노리틱 커널 : 커널이 하나로 되어있다.
프로세스 관리, 메모리 관리, 파일시스템, 입출력 관리 및 네트워크 관리 등 모든 기능을 커널 내부에 포함 - 효율성을 높임
다른 플랫폼으로의 이식성이나 확장성의 한계를 하드웨어나 환경에 종속적인 부분을 따로 분리한 계층구조로 극복
예 : 리눅스 - 모듈 사용으로 확장성 문제 해결 // 새로운 장치 모듈을 사용해서 장치 하나만 컴파일하면 됨.
장점 : 일반적으로 시스템 호출 서비스가 빠름
단점
전체적으로 볼 때 새로운 하드웨어 플랫폼에 대한 이식성은 떨어짐
한 부분에서 발생한 문제가 시스템 전체에 영향을 줄 수있음
구성요소들 간의 의존성이 높아져 디버깅이 어려워짐
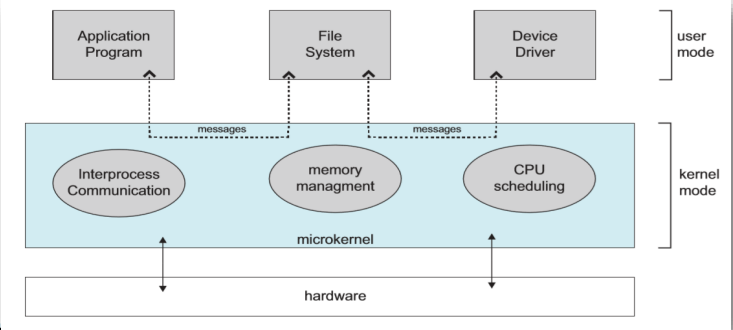
마이크로 커널
프로세스간 통신, 메모리 관리, 클럭 인터럽트 처리와 CPU 스캐쥴링 등 아주 핵심기능만을 커널에 포함시키고 나머지는 서버 형태로 두어 사용자 모드의 프로세스로 수행
시스템 콜이 들어오면 file system이나 device driver로 메시지를 전달하는 구조이다. 전달하고 결과를 받아서 다시 전달하고 하다보니까 user와 kernel 모드를 스위칭하는 것이 빈번해짐.
통신 프로토콜, 디바이스 드라이버 등의 수행은 사용자 프로세스로 존재한다
파일 시스템도 일종의 서버 프로세스로 수행한다
인터럽트도 인터럽트 서비스 프로세스에 메시지를 보내 처리한다
예 : CMU의 Mach, Windows-NT(마이크로 커널과 계층구조를 겸비한 독특한 구조)
장점
유연성이 좋다 : 커널의 핵심부분을 제외하고 나머지 User Application으로 실행하기 때문에
- cf> (상주) 모니터의 등장 : 다중 프로그래밍 기법을 고안하다 보니 작업관리 프로그램을 메모리에 상주시켜야 했고 입력장치와 비동기적 교신을 위해서 interrupt 처리를 위한 ISR도 메모리에 상주시켜야 했는데 이런 것들이 모여서 상주 모니터가 되었다. => 커널은 상주 모니터의 연장선
- 운영체제의 핵심 부분으로서 부팅 이후 메모리에 상주하는 부분 (부팅자체가 커널을 메모리에 탑재하는 과정)
- 상주모니터보다 발전해서 시분할 시스템을 제대로 지원하고 메모리와 CPU, 입출력 장치들을 관리하게 된다.
- 즉, 주로 자원 관리 및 자원 사용에 관한 서비스를 제공함
- 응용 프로그램과 커널은 하드웨어 지원을 받아 원천적으로 분리되게 되어있다. 즉, 응용프로그램하고 커널은 공간이 분리되어있다.
- 커널은 응용프로그램에게 시스템 호출이라는 것을 제공한다. 즉, 운영프로그램으로 하여금 입출력 등 커널 기능이 필요할 경우 이 시스템 호출을 호출하도록 한다. 그렇게 함으로써 커널은 스스로의 코드를 보호하고 응용프로그램은 시스템 호출을 통해서 커널 기능을 사용할 수 있게 된다.
시스템 프로그램 (커널과 혼동가능)
- 커널 이외의 프로그램으로써 운영체제 개발자가 기본적으로 제공하는 라이브러리나 운영체제 사용 도구
- ex> 편집기(vi 등), 컴파일러(gcc 등), 디버거(gdb), 쉘(ssh 등), 쉘 명령어(ls, cd, ps, grep 등)
- 쉘은 윈도우의 명령 프롬프트 또는 dos창, 우분투의 터미널 창 -> 명령어를 통해 사용자와 대화를 나누는 프로그램
- 쉘은 윈도우 형태의 유저인터페이스(GUI)가 보편화되면서 윈도우매니저가 그 역할을 대신한다. 윈도우 매니저의 전신이 쉘이다.
cf > 윈도우 매니저 : GUI 환경에서 각 프로그램들이 뜨는 창을 다루는 프로그램. MS 윈도나 애플 Mac에는 기본 시스템에 포함되어 있음.
커널의 구성요소
- 기능적 측면 의 구성요소
부팅 단계의 기능
하드웨어 진단 및 초기화 기능 - 커널 수행 이전에 하드웨어들을 진단하고 초기화하는 기능(커널이 수행되기에 적합하도록 하드웨어가 오류 없이 잘 준비되었는지를 진단하고 필요에 맞춰서 설정하는 기능)
디스크 상의 커널 프로그램을 메모리에 적재하는 기능 ( 커널 프로그램을 탑재할 때는 한꺼번에 탑재하지 않고 하드디스크 상의 마스터 부트 레코드로부터 순차적으로 chain식으로 탑재하게 된다)
부팅 후 기능 -> 각종 경영 기능
자원 경영(프로세스 경영, 중앙처리장치 경영, 주기억 장치 경영, 파일 시스템과 보조 기억장치 경영, 시스템 클럭 경영, 네트워크 경영, 입출력 장치 경영)
보안 및 정보보호 기능
- 형태적 측면 의 구성요소 -> 커널을 각종 기능을 수행하는 함수들이 어떻게 모아져 있느냐를 뜻한다
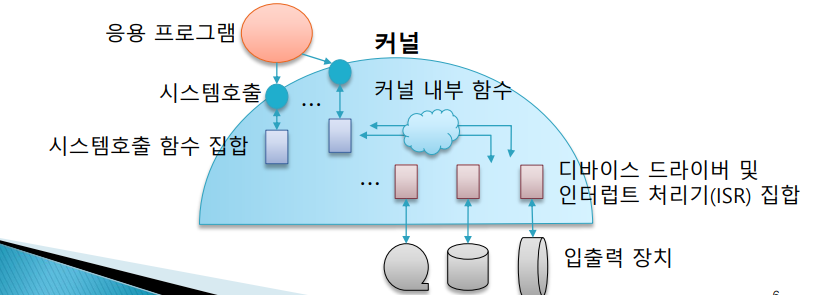
그림 : 커널 중심으로 맨 위에 응용 프로그램이 있고 맨 아래에 입출력 장치가 있다. 응용 프로그램은 위에서 커널이 제공하는 시스템 호출을 통해 커널 내의 함수 서비스를 받게 되어있다. 반면, 입출력 장치는 인터럽트를 통해서 커널의 ISR, 디바이스 내의 ISR을 작동시켜서 커널의 서비스를 받게 되어있다.
이렇게 시스템 호출, ISR 둘밖에 없는 것은 아니고 둘 사이에는 커널 내부의 작동을 담당하는 많은 함수들, 커널 내부 함수가 존재한다.
경우에 따라서는 시스템 호출 함수와 디바이스 드라이브 내의 함수들이 커널 내부의 함수들과 연결이 되게 되어있다.
인터럽트 처리기의 집합 - 시스템 클럭 및 대부분의 입출력 장치와 관계된 장치 드라이브의 핵심들이 된다.
커널 내부 함수의 예로는 [스케쥴러]가 있다. 스케쥴러는 중요한 기능이지만 형태적으로는 시스템 호출 함수나 인터럽트 처리기에 의하여 필요에 따라 호출되는 커널 내부 함수이다. 스케쥴링이 필요할 때 내부적으로 호출된다.
시스템 호출(system call)
- 응용 프로그램과 커널이 만나는 곳에 시스템 호출이 있다.
- 응용 프로그램 개발자에게는 함수 호출하는 것과 큰 차이가 없다. 예를 들어 printf, open, read, write -> 이런 것들이 라이브러리 내의 함수를 호출하듯이 사용하지만 알고 보면 시스템 호출이 이루어져서 커널의 함수가 내부적으로 작동하는 것들이 된다.
- 사용자 모드로 돌아가는 응용 프로그램이 open() 함수를 호출하게 된 것이고, 이것이 시스템 호출로 전환되어서 커널 내의 시스템 콜 테이블에서 해당 함수가 i번 함수인 것을 알아내서 처리가 이루어지고 처리가 끝나면 다시 사용자 모드로 가서 open() 함수의 다음 부분을 실행하는 그림.
시스템 호출이 이루어지는 과정
- 두 가지를 통해서 이루어진다
1. 파라미터 전달 방법(시스템 호출도 함수 호출과 비슷하기 때문에 파라미터를 전달함)
- Linux나 Solaris 같은 경우 : 파라미터를 레지스터를 통해 주소를 전달하는 방식
- X라는 곳에 전달하고자 하는 파라미터를 기록한 다음에 X의 주소를 특정 레지스터에 로드를 해놓는다. 즉, 메모리 상의 블록이나 테이블에 파라미터 값을 기록하고 시작 주소(X)를 레지스터에 기록하면 커널에서 레지스터 상의 주소를 얻어 파라미터 값들을 접근
- 다른 방식 : 레지스터가 아니라 스택을 사용
- 스택에 파라미터 값을 Push 하면 커널에서 pop해가는 방식
- 커널에 시스템 호출 사실은 어떻게 알릴까? : CPU의 명령을 실행
2. 특정 CPU 명령 실행
커널상에서 어떻게 대응되는지 정해져 있음
- open을 예시로 들면 open의 system call 고유번호가 13(시스템 호출 번호)이라는 숫자라고 볼 때, X를 담았던 레지스터와는 다른 CPU 내의 또 다른 레지스터에 담아서 interrupt를 거는(소프트웨어적인 인터럽트인 트랩) CPU 명령어를 실행하는 것이다. 즉 13을 다른 레지스터에 담고 interrupt명령어를 수행시켜 준다.
- interrupt를 거는 CPU 명령어 -> 소프트웨어 interrupt명령어(트랩 명령어)
- 트랩 명령어 : X86 계열의 경우 int라는 명령어, ARM 계열의 CPU인 경우 swi
- 이러한 interrupt는 하드웨어 interrupt와는 다르고, 단지 시스템 호출을 위해서 소프트웨어적으로 거는 것이라서 trap이라고 부른다.
- 리눅스의 경우의 예(리눅스 커널 2.4)
: 왼쪽에서는 응용프로그램이 사용자 공간에서 현재 수행 중에 있다. main을 수행하다가 read()를 만났을 경우이다. read함수 호출이 일어났다고 실질적인 내용이 막바로 실행되는 것이 아니다. 시스템 라이브러리인 libc 안에 있는 read함수가 호출된다. 이 응용프로그램이 컴파일되고 나서 링크될 때 read함수가 바로 libc함수로 링크되었기 때문에 libc내의 read함수가 호출되게 되는 것이다.
libc내의 read함수는 read라는 함수 번호가 3번으로 약속되어있다는 것을 커널 프로그래머가 지정해서 알고 있고 3번을 범용 레지스터인 eax 레지스터(명령어 주소를 담았던 레지스터와는 다른 레지스터)에 기록하고 (movl 3, % eax) trap명령어인 int를 수행하게 되는 것이다. 시스템 내에는 수없이 많은 interrupt가 존재하기 때문에 커널에게 trap임을 인지시키기 위해서 trap의 고유번호인 0x80을 int instruction의 operand에 담아서 실행시킨다(결국 int $0x80이 하나의 명령어로 실행되는 것)
이렇게 되면 커널로 0x80번의 interrupt가 걸리게 되는 것이다. 이에 따라서 IDT(Interrupt Descriptor Table)에서 0x80 interrupt의 ISR의 주소를 알아내서 노란색 저기로 점프를 하게 된다. ISR에서는 eax 레지스터의 4byte 값, int 수행 전인 3번을 읽어내서 call ~~~(% eax,4))-> 3
sys_call_table이라는 곳으로 가게 된다. sys_call_table은 system call table이다. sys_call_table에서 3번째 항으로 간다. 3번 항에 기록된 주소로 다시 한번 jump를 하게 된다. 이런 과정을 거쳐서 드디어 응용 프로그램이 read함수를 호출한 종착점인 sys_read() 함수로 도달하게 된다. (이 부분은 디바이스 드라이브 내부에 있을 공산이 크다..?) -> a와 b는 이후에 나올 내용과 연관. a는 커널 쪽을 얘기하고 b는 디바이스 드라이브 쪽.
- 시스템 콜의 실질적인 mechanism은 trap mechanism이다.
- 시스템이 다르면 맞지 않는 경우가 생긴다(ex. 파라미터의 순서, 시스템 콜의 번호) -> 호환성에 치명적인 문제 -> POSIX사용 (일관성)
- 국제 표준 - POSIX(시스템 콜의 표준)
- POSIX에서는 시스템 호출을 6개의 경우로 나누고 있다.
1. 프로세스 제어 ex. kill
2. 파일 조작 ex. open, close, read, write
3. 주변장치 조작
4. 정보관리
5. 통신 ex. send, receive(TCP socket)
6. 프로텍션(보호)
시스템 콜을 응용프로그램 개발자가 이용할 때 알아두어야 할 것
- 시스템 호출에는 2가지 유형이 있다.
1. 동기식(blocking call) : 입출력을 시작시키고 끝날 때까지 대기
- read() 같은 시스템 콜을 하고 결괏값이 넘어오기를 기다린다. 넘어오기까지 기다린 후에 넘어오면 read 다음 라인으로 계속해서 수행해가는 것. 그것이 blocking call이다. read가 실행되는 동안에는 진행을 멈추고 있다. 대부분의 시스템 콜은 이런 방식으로 지원된다. 기다리는 동안 CPU는 아무 일도 하지 않을까? ㄴㄴ -> 시분할 시스템에서는 그사이 다른 프로세스를 실행시키게 되어있다. 대기하는 동안 CPU를 다른 프로세스가 사용
2. 비동기식(non-blocking call) : 입출력을 시작시키고 바로 다음 연산을 수행, 입출력이 이루어지는 동안 자식도 CPU를 사용할 수 있음
- 시스템 콜이 이루어지면 커널에 요청만 해놓고 바로 리턴 그러고 나서 다음 라인을 바로 진행. 요청한 시스템 콜이 종료가 될 때 event가 전달된다. event가 처리할 함수를 인자로 알려주게 되어있다. --> callback함수. 이벤트가 온다는 것은 callback함수가 불린다는 것이다. callback함수는 전달되어온 데이터를 응용프로그램에 일종 자료구조에 저장하거나 직접 처리를 하게 되는 것이다. 이런 비동기식 시스템 콜은 사용하는 장치가 그러한 기능을 제공할 뿐만 아니라 디바이스 드라이브에서 비동기식에 필요한 기능을 잘 구현해놓은 경우에만 가능하다.
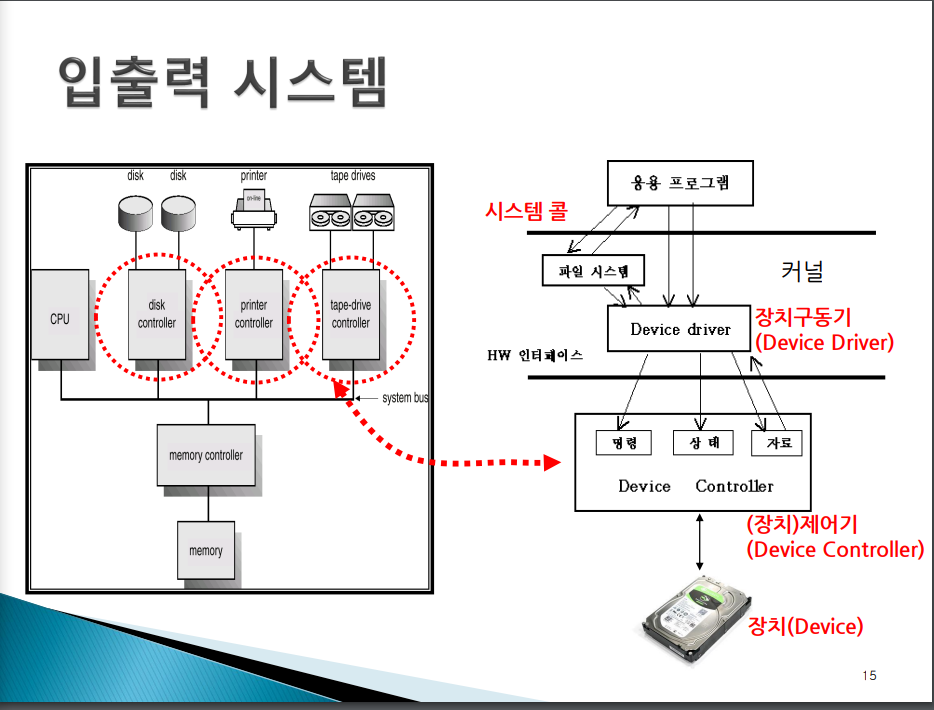
입출력 시스템 : 커널과 입출력 장치와의 인터페이스
물리적인 입출력 장치가 바로 시스템 버스에 접촉되어있는게 아니라 장치 제어기를 통해 연결되어 있다. 굳이 비유하자면 지상의 2층, 지하의 1층 건물과 같다. 2층은 응용프로그램, 1층은 커널이다. 지하 1층에는 하드웨어가 있다.
하드웨어는 제어장치와 장치로 이루어진다. 제어하기 위해 커널에는 Device driver가 있다. 층과 층 사이에는 인터페이스가 있다. 2층과 1층 사이에의 인터페이스는 시스템 콜이 되고, 1층과 지하 1층 사이의 인터페이스는 버스가 된다. (ex> PCI 버스)
Device driver는 하드웨어인 장치 제어기와 약속된 바에 따라서 명령과 정보를 주고 받는다. 그것의 실체가 무엇일까?
그것은 장치제어기 내에 있는 레지스터에(명령, 상태, 자료 레지스터들) 정해진 값을 쓰거나 읽어오는것이 된다. 장치 제어기의 레지스터들은 메인메모리 상의 주소에 mapping되어 있다. 따라서 Device driver는 이 주소에 값을 쓰거나 읽으면 바로 해당 레지스터의 값을 쓰고 읽게 되는 것이다. 그렇게 하드웨어가 만들어져 있다.
- 레지스터
명령 레지스터 : 장치가동을 위한 명령 코드 적재
상태 레지스터 : busy/done플래그, 오류코드 표현
자료 레지스터 : 장치 내의 하드웨어 버퍼
Device Controller(장치 제어기) 내에는 어떤 레지스터들이 있을까? 적어도 3종류의 레지스터들이 있다. 즉, 명령, 상태, 자료 레지스터. 명령 레지스터는 장치의 쓰기나 읽기 동작을 명령하기 위해서 명령 코드를 적재하기 위한 레지스터. 상태 레지스터는 현재 해당 장치에 오류가 있는지 또는 작업이 진행중에 있는지 작업을 끝내고 쉬고 있는지 등의 장치의 상태를 체크해보는 용도로 사용된다. 자료 레지스터는 명령 레지스터의 명령 오고갈 데이터를 읽고 쓰기위한 버퍼같은 용도로 사용된다.
층과 층사이의 인터페이스를 자세히 설명하자면 3가지로 봐야 한다. 두가지는 시스템 콜, HW인터페이스(버스).
장치들을 커널의 코드들을 바꾸지 않고 플러그 앤 플레이 식으로 install할 수 있도록 해야한다. 이 경우 커널과 디바이스 간의 인터페이스를 매우 잘 디자인해서 공개해주어야 한다. 그렇게 공개된 커널(1층)과 디바이스 간의 인터페이스가 3번째 인터페이스이다.
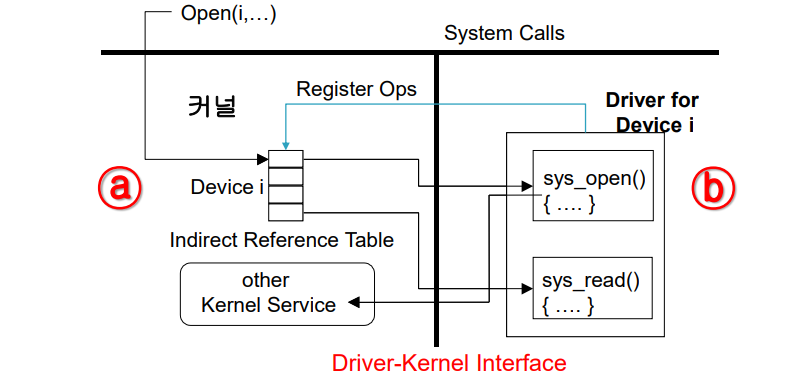
- 커널과 디바이스 간의 인터페이스(장치구동기- 커널 인터페이스)
: 왼편이 커널, 오른편이 디바이스 드라이브이다. 그 사이에 커널과 디바이스 간의 인터페이스(Driver-Kernel Interface)가 있다. 커널안에는 디바이스 드라이브가 등록되면 디바이스 드라이브의 번호가 생김, 여기서는 번호가 i 이다.
그 디바이스 드라이브가 제공하는 함수들이 등록되는 table같은 구조가 있다. 앞서 설명한 시스템 콜 테이블이 일례이다. 이후, 응용 프로그램에서 장치 i를 사용하고자 open이라는 시스템콜을 호출하면 트랩을 통해 진입. 그런 후 i를 위한 커널 내의 테이블에서 open함수의 실제 구현함수인 디바이스 드라이브 내의 sys_open이라는 함수 포인터를 얻어서 그 함수로 점프를 하게 된다.
이러한 과정을 통해서 커널과 디바이스 드라이브 간의 인터페이스가 동작하게 되는 것이다. 디바이스 드라이브는 커널 모드에서 커널과 함께 동작하기 때문에 디바이스 드라이브가 커널 내의 커널 함수를 직접 호출하거나 커널 내의 변수를 직접 접근할수도 있다. 커널의 기능을 효과적으로 이용하는 디바이스를 만들 수 있을것이다.
하지만 커널 내의 함수와 커널 내의 전역변수들을 바로 접근할 수 있기 때문에 디바이스 드라이브를 만들때 상당히 조심해서 만들어야한다.
디바이스 드라이브와 장치제어기 사이에 명령이나 정보가 오고가는 그것의 실체가 뭐냐라는 것을 얘기할때 레지스터를 접근하는 것이다 이렇게 설명함. --> 파고들어가면 방법이 다양함.
전반적으로 HW 인터페이스와 관련된 것이다. 먼저 HW 인터페이스 운영체제 관점에서 중요한 점들. (디바이스 드라이브를 설계하는데 있어서 결정적인 영향을 미치는 중요한 요소들) (장치와 장치제어기를 만드는 menufactoror들이 커널 안의 디바이스 드라이브를 짜는 software또는 개발자들에게 반드시 정확히 설명해주어야 할 부분이 있는 것이다. 그것을 장치 메뉴얼로 전달한다) 3가지 포인트가 있다.
장치제어기와 장치를 만드는 사람들이 디바이스 드라이브를 짜는 사람들에게 반드시 알려주어야 할 사항들
1. 접근 방식에 의한 분류 (레지스터 접근 방식) 어떤 방식이 있느냐
- 격리형(isolated I/O)
- 메모리 사상형(memory-mapped I/O)
2. 자료이동 방식에 따른 분류(디바이스 드라이브가 장치 제어기 내의 준비된 자료를 가져오는 방식)
- 직접 입출력 방식
- DMA 방식
3. 제어 방법에 의한 분류(장치 제어기 내에서 벌어진 상태변화를 디바이스 드라이브에게 알리는 방식)
- 폴링(polling)
- 인터럽트
아래에서 설명
1. 레지스터 접근 방식
격리형(Isolated I/O 또는 I/O mapped I/O) 입출력
입출력 장치가 메모리와는 별도의 주소공간 사용(하드웨어 구조상 주변장치를 위하여)
이 방식은 메모리 주소 지정을 위해 사용하는 주소 버스와는 별도로 I/O 장치를 위한 주소 라인을 따로 사용하기 때문에 주소값이 메모리 주소인지 입출력 장치 주소인지 구별하는 제어라인을 따로 사용하는 하드웨어 구조를 전제하는 방식이다.
결국 이러한 하드웨어적 특성을 이용하기 때문에 특수한 입출력 명령어를 사용해야 한다. (제어기 레지스터 접근을 위하여 하드웨어에 특화된 특수한 입출력 명령어)
장점 : 입출력이 메모리 주소 공간의 크기나 할당에 영향을 주지 않음
단점 : 메모리 접근 명령어와는 별도의 입출력 명령어를 사용하게 되어 프로그래밍의 일관성이나 이식성이 떨어짐
메모리 사상형(Memory-Mapped IO) 입출력
장치를 위한 별도의 주소 공간과 명령어를 정의하지 않고 메모리의 논리적 주소 공간에 제어기의 레지스터를 사상(mapping)
메모리 주소 지정을 위해서 주소 버스와 입출력 제어 라인을 공유를 하고 주소 버스에 실린 값으로 메모리 주소와 입출력 주소를 구분하는 하드웨어 특징을 전제로 한다. 메모리 주소냐 입출력 주소냐를 구분하는 별도의 라인을 두지 않고 주소 자체로 판단한다.
따라서 메모리에 할당된 주소의 일부를 장치 제어기의 레지스터를 접근하는 주소로 사용할 수 있게 되는 그런 방식이다.
별도의 주소 공간과 입출력 명령어가 필요 없고 기존의 메모리 접근을 위한 명령어를 사용
예를 들어서 CPU가 제공하는 LOAD명령과 STORE명령으로 수행(모든 입출력에 관한 명령은 해당 메모리에 대한 LOAD와 STORE 명령으로 수행)
장점 : 명령어 개수를 줄일 수 있어 프로그래밍이 용이하고, 일관성과 이식성이 좋다
단점 : 입출력을 위하여 메모리의 일부를 사용하므로 메모리 영역이 감소된다.(최근은 메모리가 커져서 큰 손해는 아님 -> 메모리 사상형 입출력이 보편화되었다)
2. 자료 이동 방식 : 장치제어기 내의 자료 레지스터하고 메인 메모리 사이의 데이터가 어떤 방식으로 이동하는 것인가에 관한 것. 직접 입출력 방식과 DMA 방식이 있다.
직접 입출력
CPU가 장치 제어기 내의 레지스터하고 메모리 자료 이동을 매번 직접 관장
CPU는 기본적으로 입출력 장치가 입출력을 하는 도중에도 프로세스 수행을 계속 할 수 있도록 되어있다. 하지만 이 방법 사용시 매 입출력 마다 인터럽트가 들어오기 때문에 CPU에게 상당한 부담이 될 수 있다.
따라서 이 방식은 입출력발생의 시간간격이 비교적 큰 장치들(ex> 문자 장치(chararcter device)) 캐릭터 단위로 입출력(ex> 키보드) Serial 입출력 방식이 여기에 해당한다.
반면, 대용량의 입출력 장치를 블록 장치라고 하는데(block device) (가장 대표적으로 하드디스크) 이런 장치에 직접 입출력 방식을 사용하는 것은 문제가 크다.
이걸 극복하는 방식이 DMA 방식이다.
DMA(Direct Memory Access)
입출력장치가 CPU 도움 없이 독자적으로 메모리(시스템 버퍼)에 Direct로 접근하여 한 입출력 명령으로 많은 자료(블록)을 입출력/전송
한 가지 문제가 있을 수 있는데 메모리 입장에서 CPU도 독립적으로 접근할 것이고, DMA도 독립적으로 접근을 하게 되어서 서로 간에 충돌이 일어날 수 있다.
해결 : Cycle Stealing -> CPU와 DMA가 동시에 메모리 접근을 요구한다면 DMA에 우선권을 주고, CPU는 한 사이클을 쉬게 됨.
Cycle : CPU가 instruction을 수행하는데 있어서 한번에 instruction 수행하는 것이 아니라, CPU수행을 위해서는 몇번의 cycle을 돌게 되어 있다.
CPU 입장에서 보면 I/O는 가끔 일어나는 셈이 된다. I/O가 일어나는 interval이 길기 때문에 우선권을 한 사이클정도는 DMA에 줘도 괜찮음
DMA의 주체는 하드웨어이다.
한 블록의 입출력 완료시 한번만 인터럽트 발생시켜 빈도수를 줄인다.
3. 장치제어기 상태를 CPU로 하여금 알게 하는 방식(CPU가 장치제어기 상태를 알아내는 방식)
폴링(Polling) 방식 vs 인터럽트 방식
폴링(Polling) 방식 : 상대방의 상태를 내가 주도적으로 체킹한다 -> CPU가 레지스터를 반복적으로 체크하면서 목표한 상태로 바뀌었는지 체크한다. 따라서 상태변화가 있을때까지는 CPU가 계속 대기하면서 체크하고 있다. 폴링을 위해서 디바이스 드라이브가 동작하는 내용을 순서적으로 본다면
응용 프로세스로부터 입력이 요청됨
장치구동기가 장치제어기의 명령 레지스터에 명령어 적재(장치제어기는 하드웨어이기 때문에 즉시 장치 가동) -> 장치 가동
상태 레지스터가 busy 상태에서 done으로 바뀔 때까지 대기(그 명령어로 인해 장치가 끝날때까지 기다림)
done이 되면 제어기의 자료레지스터 내용을 응용 프로세스 공간으로 복제
단점 : 루프를 사용하여(busy waiting 방식) 제어기의 상태를 체크하는 것은 CPU를 낭비하게 됨
그러나, 인터럽트가 제공되지 않는 장치의 경우 일정시간 주기적으로 제어기 상태 조사
폴링 방식을 사용하면 busy waiting으로 인하여 CPU에 부담이 가중된다. 할 수 없이 폴링 방식을 사용해야 되는 경우도 있지만 좋은 방법은 아니다. 대안은 인터럽트 방식이다.
인터럽트 방식 : (폴링이 대기 방식이였다면 인터럽트는 알림 방식이다.)
CPU가 디바이스 드라이브의 코드를 실행함으로써 결국 입출력 명령을 장치 제어기에 전송을 한다. 그리고는 CPU는 다른 프로세스를 수행하고 있으면 그 요청에 뜬 입출력 작업이 다 끝났다는 것을 장치제어기가 CPU에게 알리는 것이다. 여기서 알리는 것을 인터럽트라고 부른다. 즉, 인터럽트는 장치제어기가 보내는 것이고 인터럽트는 CPU가 받는 것이다. 그래서 장치제어기가 입출력 작업이 끝나면 다 끝났다고 CPU에게 알리는 것, 그것이 interrupt라는 것이다.
인터럽트 방식은 하드웨어가 인터럽트 처리 체계를 갖고 있다는 것을 전제로 하고 있는 것이다.
인터럽트가 발생하면..
1. (중단) 현재 진행중인 프로세스 또는 하위의 ISR(Interrupt Service Routine) 수행을 즉시 중단
2. (문맥보존) 프로그램 카운터 (PC) 및 CPU 레지스터 값들을 보존(문맥에 해당)
3. (마스크설정) 현재의 인터럽트에 해당하는 마스크를 설정하여 자신보다 하위 인터럽트가 먼저 처리되지 않도록 함(상위 하위 이런것들 판단하기 위해 마스크 설정)
4. (ISR 진입) 현재의 인터럽트에 해당하는 ISR으로 제어를 넘김(즉, 프로그램 카운터를 해당 ISR의 첫주소로 셋팅) (ISR 시작주소 알아야함)
인터럽트 백터 테이블에 장치번호 순서대로 ISR의 시작주소가 기록되어 있음.
인터럽트 처리가 끝나면 인터럽트 당한 프로세스 또는 수행중이던 하위 ISR을 계속 실행하기 위해 보존된 레지스터 내용을 복구 <- 운영체제의 결정이 필요
어떤걸 복구하냐 -> 프로세스이면 여러개 중에 운영체제의 결정이 필요하다(스케쥴링에서 필요)
여러 종류의 인터럽트 간의 경쟁 조정을 위해 인터럽트 priority level을 결정할 필요가 있다
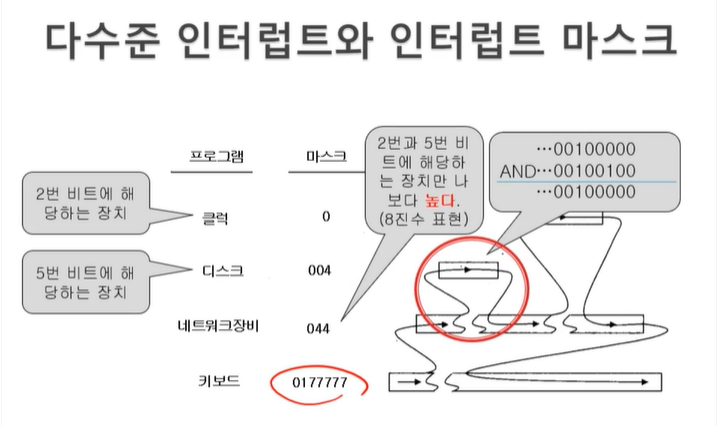
다수준 인터럽트와 인터럽트 마스크
시스템의 모든 장치에 대해 비트(또는 비트번호)를 지정
예를 들어서 시스템에 접속될 수 있는 장치 최대 장치 개수가 16개라 한다면 인터럽트 종류도 16개가 된다. 그렇게 하기 위해서면 2byte면 된다. 2byte라 하고 각 비트마다 하나의 인터럽트를 지정해주는 것이다. 예를 들어 디스크는 5번, 클럭은 2번 이렇게 지정. 8진수면 디스크는 040 클럭은 004
인터럽트 마스크를 통해 수준(Interrupt priority level) 적용
인터럽트 마스크도 2byte를 사용하겠고 그것도 장치마다 지정했던 비트를 사용한다. 인터럽트 마스크는 우선순위 비교용인데 우선순위 비교를 어떻게 하냐.
예를 들어 방금 전에 interrupt가 들어와서 이에 해당하는 ISR을 처리중인데 그 ISR에 들어가기 전에 interrupt mask를 044로 설정했다고 하자.
044면 2번이랑 5번 bit에 1이 표시되어있다. 2번이랑 5번이 아까 클럭과 디스크라 함. 무슨 뜻이냐하면 현재 ISR이 뭔가 처리중에 있는데 ISR을 위해 처리하기 바로 전에 뭐라고 마스크를 설정했냐 하면은 2번이랑 5번은 나보다 쎈 놈입니다. 그놈들이 들어오면 나를 잠시 중지시키세요하고 설정을 하고 들어갔다는 의미이다. 그게 바로 클럭하고 디스크이다. 현재 진행하고 있는 인터럽트 처리보다 클럭이나 인스턴스의 우선순위가 높으니 그것들로부터 인터럽트가 들어오면 나를 잠시 중지시켜달라. 그게 인터럽트 마스크를 설정했다는 의미이다.
그러한 상황에서 새로 인터럽트 들어왔는데 디스크 인터럽트가 떴으면 그러면 그 인터럽트는 어떻게 표현이 되냐하면 5번 비트가 1로 표현이 된다. 그래서 현재 새로 들어온 인터럽트는 00100000으로 표현이 된다. 그럼 새로 들어온 인터럽트가 더 쎈놈이냐 판단을 해야 하는데 그래서 두개사이에 AND operation을 취한다. 이게 결국에 masking을 해보는 것이다. masking을 했더니 한 bit가 맞아서 1이 되었다. 그래서 전체 값이 양수가 나왔다. 양수가 나왔다는 것은 0이 아니라는 것이고 0이 아니면 False가 아니라는 뜻이므로 새로 들어온 인터럽트가 쎄다라는 것을 판단할 수 있다. 그래서 지금 들어온 디스크 인터럽트부터 처리한다. 그게 인터럽트 마스크의 역할이다.
인터럽트 마스크를 통해 수준(Interrupt priority level) 적용
임의 인터럽트가 들어오면 해당 인터럽트와 현재의 마스크를 비교하여(마스킹) 우선순위 판단
그래서 인터럽트 마스크를 항상 설정해주어야 한다. 언제 설정하냐 -> 인터럽트의 ISR시작에 앞서서 인터럽트 마스크를 재설정하고, ISR 종료시 원상복구 해준다. -> 디바이스 드라이브 만드는 사람의 책임이다.
Q> 가장 순위가 낮은 인터럽트(아마도 키보드 인터럽트), 키보드 인터럽트의 ISR을 처리하는 동안에는 인터럽트 마스크는 어떻게 설정되어 있을까? 당연히 모든 비트가 1로 setting된 0177777이 될것이다.
이 말은 어떠한 interrupt가 와도 새로운 인터럽트를 처리해도 된다는 뜻이다.
만약 키보드 인터럽트를 처리중에 있다가 네트워크 장비로부터 인터럽트가 들어오면 키보드 인터럽트보다는 네트워크 인터럽트가 우선순위가 높으니까 당연히 현재 처리중인 것은 중단이 되고 네트워크 인터럽트를 처리하러 들어간다. 네트워크 장비에 해당하는 마스크를 044로 설정하고 들어갔다 하자. 즉, 2번과 5번, 클럭과 디스크에 해당하는 장치만 나보다 높다라는 뜻. 그렇게 해서 네트워크 인터럽트를 처리하는 도중에 디스크 인터럽트가 떴다. 그럼 다시 마스크를 004로 설정하고 디스크 인터럽트에 들어간다. 그래서 클럭이라는 것은 2번비트에 표현하고 디스크 인터럽트 ISR 처리하기 위해 들어간다. 즉 자신보다 인터럽트 높은건 지금 클럭밖에 없기때문에. 누가 우선순위 높은지는 빠르게 판단하기 위하여 하드웨어 기준으로 이루어져야 한다. 즉, 마스킹 오퍼레이션은 하드웨어적으로 이루어진다. 이를 위해 AND 연산을 한번만 사용하면 masking operation이 되도록. 즉 디스크로부터 인터럽트가 들어왔다는 것은 004, 네트워크장비는 044, 두개를 AND연산하면 0이 아니므로 더 쎈 인터럽트가 들어왔다는 의미가 됨. 그래서 바로 디스크 인터럽트 처리를 위한 ISR이 된다.
Fast interrupt Handler(FIQ) => 지엽적인 내용이긴함
Fast Interrupt : 특별히 빠른 처리 혹은 빠른 반응을 위해 ISR에서 다른 인터럽트 처리를 disable 시키고 짧은 시간에 처리를 마무리하는 것을 의미한다. 시스템에서는 clock 같은 것들이 중요한데 clock interrupt같은 것들은 fast interrupt로 처리한다.
다중 프로그래밍은 더이상의 대화성 증진에는 한계가 있었다. 입출력이 일어날 때에만 스케쥴링이 일어나기 때문에
- 한 프로그램의 입출력 빈도와 시간이 다른 프로그램의 수행에 영향을 준다.
- 한 프로그램의 수행시간이 다른 프로그램의 수행시간에도 영향을 준다.
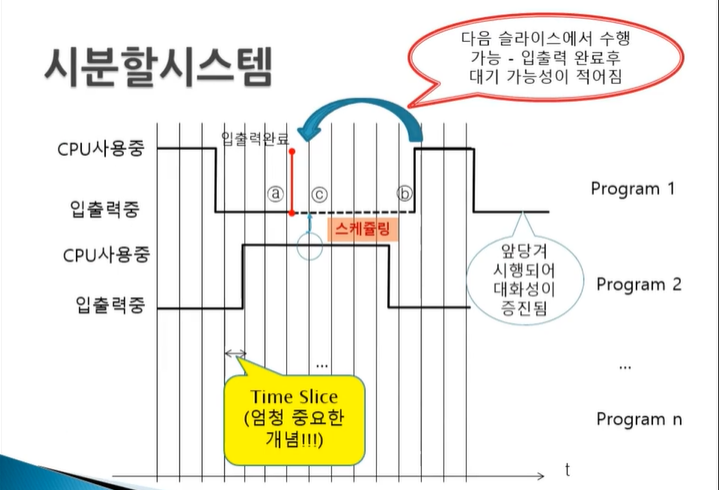
시분할 시스템
다음처럼 a시점 이후 b까지의 대기시간이 있다 -> Program2가 Program1에 영향을 준다.
- 따라서, 사용자와의 빈번한 대화성(편리성) 증진에는 한계가 있다.
시분할 시스템의 핵심은 타임슬라이스
- 입출력 발생이 일어났을 경우에도 스케쥴링이 일어나지만 타임슬라이스가 도래하면 무조건 스케쥴링을 시행한다.
- 프로그램의 간섭을 없애고 대화성도 증진시킬 수 있었다
- 시분할 시스템은 1960년 CTSS가 시초인데 하드웨어 여건 부족으로 안되다가 현재에 운영체제의 기본적인 체계로 자리잡았다
시분할 시스템의 원리
다중 프로그래밍과 비슷하지만 한가지가 바뀌었다. 세로줄들이 여러개 추가되었다.
이 세로줄이 타임슬라이스(Time Slice)이다. Time Slice가 끝날때마다 스케쥴링을 실행한다. 이렇게 되면 입출력이 되었을때도 스케쥴링이 일어나겠지만 그 외에도 Time Slice 도래했을때도 반드시 스케쥴링 일어나서 서로간의 간섭을 최소화할 수 있다.
Program1이 입출력을 완료한 시점인 a 바로 다음 시점에 타임슬라이스 일어났을때 속개될 수 있는 가능성이 생기는 것이다. 여기서 b-c만큼 앞당겨질 수 있는 가능성이 생긴 것이다. 단, 여기서 우선순위가 개입된다. C 시점에서 스케쥴링을 하는데 이 때 우선순위가 2가 더 높다면 c에서 1이 실행되지는 않는다.
궁금한 점은 Time Slice는 그럼 컴퓨터 상에서 어떻게 실현할까? Time Slice는 기본적으로 Timer Interrupt를 통해 구현한다고 생각하면 된다. 보통 10msec로 interrupt를 설정해서 그 interrupt가 들어올때마다 스케쥴링을 하는 것이다.
- 시분할 시스템이 대두되었을때는 컴퓨터의 수요도 늘고 있었을뿐만 아니라 대화형 편집기의 인기가 높아졌을때.
이에 따라서 빈번한 대화, 즉 입출력 요구가 수행시간의 대부분을 차지하는 프로그램이 보편화되었고 그럼에 따라서 시분할 시스템이 좋은 해결책이 되었다.
- 대화성이 증진되다보니 사용자 입장에서는 시스템 전체를 혼자서 사용하고 있다는 착각이 가능했다. 여러 사용자가 개인용 모니터를 통하여 한 시스템에 동시에 연결하여 동시 사용이 가능해졌다. 즉, 운영체제가 각 사용자들 프로그램 사이를 재빠르게 전환함으로써 혼자 컴퓨터 독점했다는 착각. 각 사용자에게 각자의 모니터를 통해 접속하도록 해서 혼자 사용한다는 느낌.
- 터미널이라고 부름(키보드와 브라운관으로 이루어짐)
- RS232라는 시리얼 통신표준 사용
- 시리얼 라인을 통해서 전산센터의 중앙컴퓨터의 각 포트에 원격으로 연결
- 각자의 방에서 vi같은 편집기를 통해 작업할 수 있다
- CPU의 효율성 증대, 빠른 응답시간을 제공함으로써 편의성도 증대
- 타임 슬라이스 이외에도 다양한 연구주제들을 파생시킴
- 가상 메모리 : CPU 활용의 효율성이 높아짐에 따라서 더 많은 프로그램을 동시에 적재하고자 하는 요청이 들어온다. 이는 결과적으로 메모리 부족을 야기하게 되었다. 그래서 한정된 메모리로서 여러 프로그램을 실행시킬 수 있도록 했어야 했는데 이를 위해서 탄생한것이 가상메모리 기법이다.
- CPU 스케쥴링, 동기화 및 교착상태 같은 이슈 대두
실시간 시스템
- 특수한 분야를 위해 발전시킨 기술. 프로그램의 동작에 실시간성, 즉, 엄격한 마감시간(deadline)이 요구되는 분야가 있으며, 이러한 요구를 만족하는 시스템을 실시간 시스템이라 함.
- 예를 들어, 공장 생산 라인, 과학실험 제어, 산업제어, 항공기/미사일 제어, 로봇, 동영상 처리
- 실시간성은 두가지 부류로 나누어진다.
1. 경성 실시간성(hard real-time)
- 데드라인 위반사건 발생시 재앙적 사건이 발생 - 무기 제어, 원자력 발전소.
- 데드라인 100% 준수한다는것을 수학적, 실험적으로 증명해야 함
- 경성실시간 운영체제는 아주 크기가 작다. 코딩량이 많을수록 증명하기 어렵기 때문
2. 연성 실시간성(soft real-time)
- 데드라인은 존재하지만 위반시 재앙까지는 야기하지는 않음 - 동영상 플레이어
- 만족여부는 주로 확률적으로 제시되며 보통 실시간 작업과 일반 작업 간의 우선순위 제어로 해결한다
- 실시간과 관련해서 스케쥴링 알고리즘에서 실시간 스케쥴링 알고리즘 다룰 예정
실시간 시스템을 시분할 시스템과 굳이 구분하여 얘기하자면 실시간 시스템 경우 deadline의 b시점일 경우 그에 앞서서 반드시 실행시켜야 할 작업을 수행하는데 걸리는 최대소요예측시간(WCET)이 주어졌다고 하자. (안주어질 경우도 있다)
b라는 마감시간을 놓치지 않으려면 아무리 늦더라도 c시점까지는 스케쥴링이 마무리 되어서 프로그램1이 속개되도록 해야될것이다. 프로그램2가 c에서 스케쥴링을 당해야한다.
트랩은 커널공간과 사용자공간을 나누어서 접근할 수 있는 권한설정에서 매우 중요한 역할을 한다.
-> CPU는 CPU나름 입출력장치는 입출력장치 나름대로 데이터를 출력하고 메모리 어느 곳에 데이터를 얹어놓는데 이곳이 버퍼이다. 양쪽이 분리되어 동작하고 서로 소통은 CPU를 통해 진행한다.
- 문제는 주컴퓨터 CPU가 부하가 걸린다(operator가 있을땐 나눌 수 있었는데 operator를 없애다 보니까 CPU가 과부하)
-> 해결 : 입출력장치와 CPU가 각자의 간섭없이 작업을 하도록 하고, 그동안 입출력장치가 컴퓨터 메모리상의 약속된 장소를 직접 접근하면서 입출력을 끝내도록 하고, 그 작업이 끝나면 CPU에 알리도록 해서 CPU가 다음 입출력 작업을 지시하도록 한다.
일괄처리시스템에서 모니터의 태동 : operator 자동화를 위해서는 메모리에 상주하는 프로그램이 필요하다
-> operator 대신 프로그램이 메모리에 올라가 있어야 되기 때문( ex> ISR, 적재기, JOB Sequencer, 제어카드 번역기)
상주모니터(Resident Monitor)
- 컴퓨터가 시동되는 시점부터 메모리에 탑재되어서 영구적으로 상주해야되는 것들
- 인터럽트 처리기 또는 입출력 관리자를 메모리에 영구적으로 상주시켜야 할 필요성 대두
- 작업 제어 명령어, 적재기, 작업 순서 제어기를 상주시켜 컴퓨터의 운영을 좀더 자동화 시킴
보호 이슈 >>
- 모니터가 메모리에 상주하는데 메모리에는 모니터도 있지만 채널을 통해서 버퍼에 들어오는 것이 프로그램이 탑재되어 들어올 수도 있다.
-> 다른 프로그램이 메모리 한 부분에 위치하게 되어서 CPU에 의해서 수행될 수도 있다. (ex> 사용자 프로그램들)
-> 이 프로그램을 수행하다가 모니터의 영역을 침범하는 경우가 생긴다 (즉, 덮어쓰는 경우가 생겨서 상주 모니터 보호의 필요성 대두된다)
특히 입출력할 때 자주 발생해서 이를 방지하기 위해 모든 사용자 프로그램은 입출력을 직접 하지 않고 반드시 모니터가 제공하는 입출력 함수를 호출해서 입출력하도록 했다 (-> 시스템 콜의 태동) ex> fork() 함수
(시스템 콜 : 커널 내의 함수를 응용 프로그램이 불러 쓰는 것)
-> 미리 작성된 테이블에 기록된 메모리 접근 허용치(사용자 프로그램이 접근할 수 있는 메모리 영역 허용치) 참조하여 각 연산 수행 시 메모리 접근 범위를 제한한다.
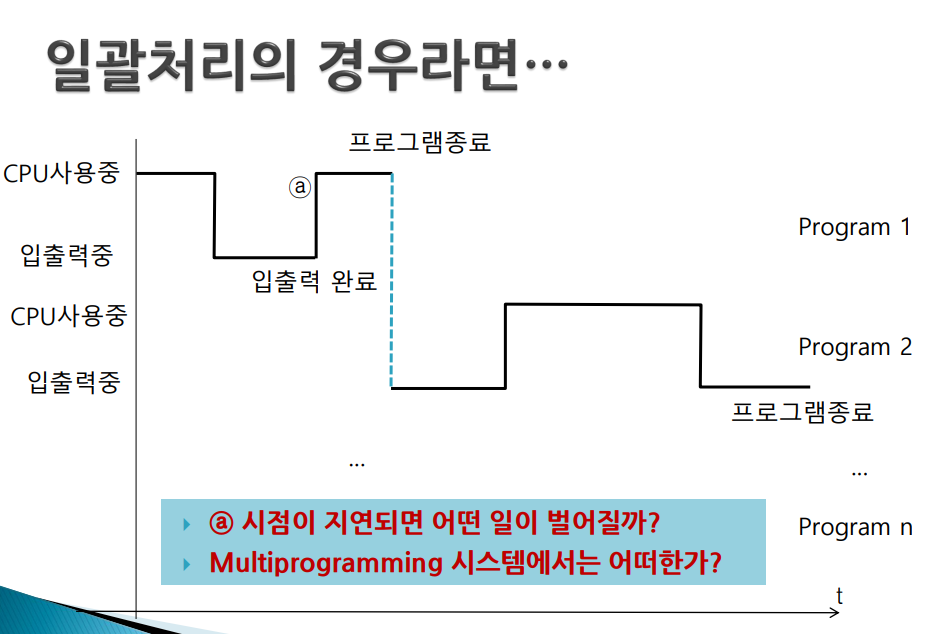
일괄처리시스템의 장점
- 초기 일괄처리 시스템에 비하여 효율성 개선됨(효율성 높이는데 큰역할)
- 하나의 작업이 CPU를 독점하므로 해당 작업으로 볼 때는 처리 속도가 가장 빠르다 (프로그램이 자원 독점)
- 사용자와의 대화가 필요하지 않은 CPU-bound 응용 프로그램 수행에 적합하다 (수치 계산, 대용량 데이터 처리 등)
단점
- 사용자와의 대화가 필요한 요구들이 많을때(ex> 편집기 ) 이것을 수행하기에는 부족하다
- 일괄 처리 시스템은 한 작업, 한 작업을 순차적으로 처리 -> 한 프로그램이 입출력을 위해 소모한 시간은 다음 프로그램에게는 기다리는 시간(즉, 전체 처리량 저하)
--> 그렇다면 여러 프로그램을 동시에 실행시키면??
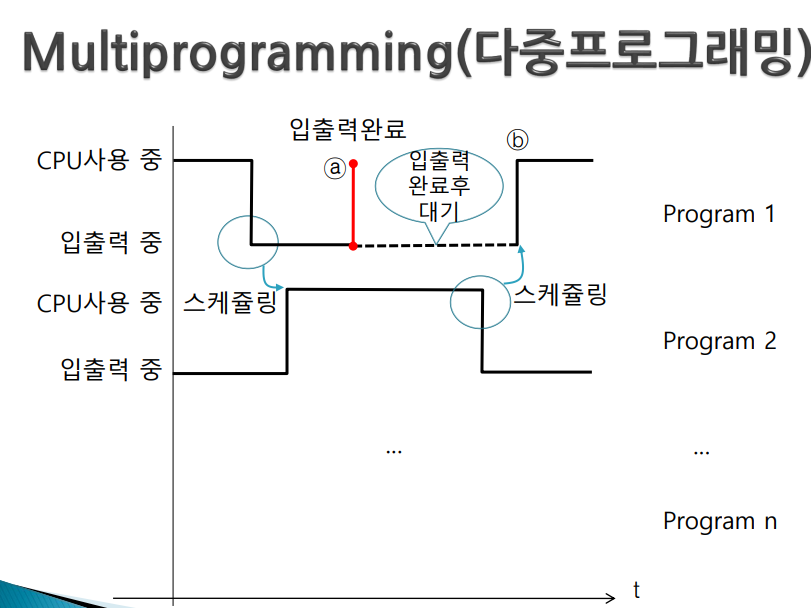
다중 프로그래밍(Multiprogramming)
다중 프로그래밍은 일괄처리시스템과 달리 프로그램을 번갈아 수행한다
- 프로그램을 수행하다보면 어느 순간 입출력이 일어남(키보드 입력을 기다리거나 출력이 끝나기를 기다리는 상태에 도달)
-> 입력이 들어오기까지 마냥 기다리는 것이 아니라 입력이 들어오면 interrupt를 걸도록 해놓고 그 사이 다른 프로그램 선택해 수행 (이걸 모든 프로그램에 적용하면 번갈아가며 수행시킬 수 있게 된다)
- 한 시점에 여러 프로그램을 사용자 영역에 탑재
-- 시스템에 들어오는 모든 작업은 일단 작업 풀(디스크 사용)에 적재됨
--작업풀 내의 작업은 운영체제의 정책에 따라 선택되어 메모리에 탑재
- 탑재된 작업 중 하나를 선택하여 실행한다
- 한 프로그램이 입출력을 하는 동안 다른 프로그램을 선정하여 CPU가 실행한다(이것이 스케쥴링, 어떤것 선정이 좋을지 정책 필요)
- 스케쥴링이 언제 일어나냐 -> 다중 프로그래밍인 경우 수행중이던 프로그램에서 입출력이 일어날 경우에만 스케쥴링이 일어난다.
(- 시분할 시스템에서도 스케쥴링 일어나는데 차이 구분하면??)
- 만약 program2에 문제가 있어 무한 loop 돈다(program1은 cpu 받기를 기다리고 있다) -> 스케쥴링은 입출력 변할때만 이루어지니까 program2가 무한루프를 돌면 입출력을 하는 순간은 오지 않는다. 즉, 입출력 요구하는 상황이 벌어지지 않는다 -> 스케쥴링도 일어나지 않는다 -> program1 영원히 대기
- 그래서 다중 프로그래밍인 경우 프로그램 간섭이 일어날 수 있다
1. 스케쥴링은 입출력이 일어났을때만 된다 2. 프로그램 간의 간섭이 일어날 수 있다
-> 대부분 프로그램의 실행 시간에서 CPU의 사용 시간은 극히 일부분이고 나머지는 입출력 시간이다.
-> N개의 프로그램이 실행된 시간이 각각 t1, t2, ... ,tn이라 할 때,
- 일괄처리 또는 uniprogramming : t1+t2+t3+... +tN
- 다중프로그래밍인 경우 대략 : max(t1,t2,,,,tN)
- 한 프로세스의 입출력 시에 다른 프로세스를 처리할 수 있게 되므로, CPU가 항상 일을 하고 있게 됨
- 또한, 디스크를 이용한 Buffering과 Spooling으로 입출력과 CPU수행의 중복 정도를 높일 수 있게됨
- Input Spooling은 Job Scheduling에 사용
- Output Spooling은 산발적인 프린트 출력을 모아서 프로세스가 끝난 후에 출력
- 새롭게 대두되는 이슈
- Job Scheduling : 최적의 스케쥴링 방법
- 메모리 경영 - 여러 작업이 메모리 상에 존재, 한정된 메모리 공간에 n개의 프로그램 탑재해야 되기 때문에 어떤 것들을 탑재하느냐에 대한 알고리즘
POSIX semaphore을 이용하려면 semaphore 객체를 초기화하거나 새로 생성하는 작업이 필요하다. Semaphore가 2가지 종류가 있다. 하나는 이름이 없는 unnamed semaphore, 다른 하나는 named semaphore.
Example)
1. process chain을 만든다. (process chain은 부모 프로세스가 자식 프로세스를 만들고 부모 프로세스는 빠져나가고 자식 프로세스가 계속 loop안에 남아서 자식 프로세스를 만드는 과정으로 진행) argument로 생성할 프로세스 개수를 추가적인 command라인으로 제공한다. 각각의 프로세스는 화면에 string을 출력하는데 process의 id와 child,parent id를 출력한다. 바로 출력을 하는 것이 아니라 process는 문자열을 buffer에다가 넣고 character buffer에 있는 내용을 loop을 돌면서 character 하나씩 출력한다. 한 character를 출력하고 다음 character 출력할때까지 delay를 줄 수 있다. delay를 주는 이유는 쉬는 사이에 context switch가 일어날 가능성이 많아진다. 그럼 다른 process가 선택이 되어서 다음 process가 진행이 된다. delay가 크면 buffer에 있는 것을 다 출력하기 전에 context switch가 일어나면 화면에서 섞이게 된다. 섞여서 출력이 된다. delay가 작으면 정상적으로 나온다. 하나의 process가 출력할 때 critical section이 아니기 때문에 다른 process가 침범해서 벌어지는 문제이다.
chaincritical.c
#include<stdio.h>#include<stdlib.h>#include<string.h>#include<unistd.h>#include<sys/wait.h>#include"restart.h"#define BUFSIZE 1024intmain(int argc, char *argv[]){
char buffer[BUFSIZE];
char *c;
pid_t childpid = 0;
int delay;
volatileint dummy = 0;
int i, n;
if (argc != 3){ /* check for valid number of command-line arguments */fprintf (stderr, "Usage: %s processes delay\n", argv[0]);
return1;
}
n = atoi(argv[1]);
delay = atoi(argv[2]);
for (i = 1; i < n; i++)
if (childpid = fork())
break;
snprintf(buffer, BUFSIZE,
"i:%d process ID:%ld parent ID:%ld child ID:%ld\n",
i, (long)getpid(), (long)getppid(), (long)childpid);
c = buffer;
/********************** start of critical section **********************/while (*c != '\0') {
fputc(*c, stderr);
c++;
for (i = 0; i < delay; i++)
dummy++;
}
/********************** end of critical section ************************/if (r_wait(NULL) == -1)
return1;
return0;
}
n이 2라면 loop는 1번만 돌린다.(이미 돌아가고 있는 process있기 때문에) argv[2]는 delay값. (atoi로 integer로 변경해준다.) snprintf로 buffer에 char값을 적는다. snprintf는 다쓴 다음에 자동으로 끝에 null값을 추가해준다. 모든 프로세스들은 buffer에 자기가 출력할 것을 저장해 놓는다. c에 buffer의 시작값을 저장한다. c의 값을 하나씩 증가하면서 c에 있는 buffer의 값을 출력시킬 것이다. for loop을 빠져나온 것은 화면에 출력할것을 먼저 쓴다. 그리고 while문에 들어가서 buffer에 character를 하나씩 출력한다. c가 가리키는 buffer값이 null값이 아닐동안 while문안에서 fputc를 호출해서 특정 file pointer에서 출력한다. 현재 c가 가리키는 buffer안에 있는 값을 출력을 하겠다. stderr장치에다가 출력을 하겠다. 계속 다음 것을 출력하는게 아니고 delay값만큼 dummy integer변수를 iteration을 돈다. 자식 프로세스도 이 부분에 진입할 수 있다. r_wait는 중요하게 안봐도 된다.
critical section은 코드의 특정부분을 의미한다. 특정 부분을 critical section으로 만들겠다. 한번에 하나의 process만 진행을 해야 한다. critical section과 관련된 코드 파트를 4가지 파트로 구분해서 이야기 한다. (운영체제에서 얘기하는것과 동일)
critical section을 빠져나온다음에 exit section으로 진입한다. exit section에서 lock을 release해야 한다. lock을 release하는 routine이 진행이 되어야 한다. unlock을 호출하는 부분이 exit section이 될 것이다.
Solution to Critical-Section Problem
3가지 조건을 만족해야 critical section 문제를 해결할 수 있는 mechanism이 될 수 있다. 조건은 1. mutual exclusion(코드에는 한번에 하나의 process만 진입할 수 있다), 2. Progress (진행이 된다, 만약에 어떤 process도 critical sectino에 있지 않으면 process가 critical section에 진입하기 원하는 process가 있다면 그러한 process들 중에서 다음 process를 선택해서 다음 process가 critical section으로 진입할 수 있어야한다, 빠져나간 process가 아닌 대기중에 process가 계속 critical section에 진입할 수 있어야한다.)
1번을 만족하는데 2번을 만족 안하는 경우. lock을 요청한 첫번째 process만 들어가는데 이 process가 unlock을 하고 나가야되는데 unlock을 안하고 나갔으면 다음 process는 계속 기다려야 한다. 그래서 2번 조건을 만족하지 않는다(unlock을 해서 다음 process가 들어가도록 해야한다) 3번 조건은 Bounded Waiting(기다리는 process에 대한 조건인데, 기다리는 시간이 한정적이어야 한다. 마냥 계속 기다려서는 안되고 제한된 시간 안에는 process안에 진입할 수 있어야한다. bound가 존재해야 한다. 특정 bound안에는 critical section안에는 진입할 수 있어야 한다. 모든 process에게 fair한 조건을 줘야한다. 특정 process는 대기하고 있는데 계속 다른 process에게 밀려서 진입하지 못하는 case가 생길 수도 있기 때문이다.)
Semaphores
semaphore객체는 OS에서 관리하는 resource중 하나이고 process들이 다양한 방식으로 동기화를 할때 사용할 수 있는 동기화 mechanism이다. integer variable이다. 이것이 수행할 수 있는 operation이 2가지가 있다. atomic operation이라 하는것은 더이상 쪼갤 수 없는 operation. 중간에 다른 operation이 끼어들어올 수 없는 operation이다. 수행하는 부분이 그 자체로 critical section이 되어야 한다. 개발자 입장에서 할 수 있는것이 아니고, 커널(OS)영역에서 지원을 해주어야 한다. Semaphore의 함수는 kernel에서 지원을 해준다는 말이고 하나는 wait operation, 하나는 signal operation이다. 2개의 operation을 진행할 수 있는 정수형 변수다. wait는 정수값을 줄일려고 하는 oepration, signal은 정수값을 증가시키는 operation이구나 라고 생각하면 된다.
wait operation은 semaphore operation의 정수값을 줄이는데 항상 줄이는 것이 아니고 semaphore값이 0보다 크면 semaphore값을 감소시키고, 만약에 0이면 더이상 못줄이니까 wait 함수를 호출한 caller의 실행을 block시킨다. 즉, 대기를 하게 된다. wait함수를 호출해서 semaphore값이 0이면 대기. waiting queue로 들어가서 block된다. 그게 아니라 10이였다 그러면 wait를 호출한 것은 9로 줄이고 지나가는 것이다. 0인데 wait를 호출하면 그 process는 waiting queue로 들어가서 대기한다. 0보다 큰 경우에만 줄인다. signal함수는 반대로 semaphore를 증가시키는 함수이다. semaphore를 증가시키기 전에 마냥 증가시키는 것이 아니고 block된 process가 있으면 그 process를 깨워주는 역할도 한다. 먼저 thread나 process가 blcok되어있으면 signal함수는 semaphore값을 0인상태로 두고 하나를 unblock시킨다. signal 함수를 호출하면 하나를 깨운다. 만약에 아무 thread도 block되어있지 않으면 그때 semaphore를 증가시킨다.
pseudo code. wait의 과정은 automic하게 진행해야 한다.
void wait(semaphore_t *sp){ if(sp->value > 0) sp -> value--; else{ <add this thread to sp-> list> <block> } } void signal(semaphore_t *sp){ if(sp->list!=NULL) <remove a thread from sp->list> else{ sp->value++; } }
Semaphore examples
다양한 방식의 동기화 방식을 해야 하는데 다양한 방식은 초기값이 중요하다. 거기서 동기화 방식이 결정된다. s라는 semaphore가 있다고 가정하고 보호하고 싶은 critical section이 있다고 하면 그 전에 entry section에서 허가를 먼저 받아야 한다. 허가를 받기 위해 wait operation을 사용한다.
wait를 진행하면 첫번째 process는 semaphore값을 0으로 줄이고 critical section으로 진입한다. 그 사이에 다음 process가 와서 진입할려고 한다 하면 wait를 호출했더니 semaphore의 값이 이미 0이다. 그래서 나는 semaphore를 줄이지 못하고 이 process는 waiting queue에 들어가서 대기해야 한다.(block) critical section에 들어간 process가 다 진행하면 exit section에 들어가서 signal 함수를 사용해서 반환해 준다.
semaphore값을 1로 초기화하는것이 중요하다. 만약에 semaphore 초기값을 0으로 초기화했으면 어떻게 동작할까. 모든 wait가 block하고 deadlock 결과를 도출할 것이다. 마냥 기다리면 deadlock이 된다. 만약에 8로 선언하면, critical section에 여러개 process가 들어가서 critical section이 깨진다.(총 8개의 process가 진입하게 된다) 9번째가 진행하면 들어가지 못하고 대기하게 된다. 이 case는 critical section은 깨졌는데 다른 방식으로 동기화가 된다. 한번에 최대 8개가 진입할 수 있다는 동기화가 진행하게 된 것이다.
semaphore의 2개의 operation을 잘 숙지하자. entry section에 쓸 수 있는 허가를 얻기 위한 것이 wait, signal은 허가를 반환하는 허가를 반환한다는 것은 semaphore값을 증가시키는 것. 또다른 방식으로 동기화하는 방식을 얘기하고 있다. 두 process가 수행하는 operation의 수행 순서를 어느정도 제한을 두고자 한다. 어떤 식이냐면 process 1번의 statement, process2는 b를 진행시킬려고 하는 것이다. a와 b 2 statement는 어떤 순서로 진행이 될지 모른다. semaphore을 사용하면 순서를 제어할 수 있다. 1번이 a를 실행을 하는데 2번이 하는 b보다 a가 먼저 항상 실행이 되도록 항상 a라는 statement가 b보다 먼저 실행이 되게끔 해야겠다. 그렇게 하기 위해서 sync라는 semaphore를 사용하게 된다. 초기값을 0으로 초기화하고 정상적으로 process 1이 먼저 진행했다라고 하면 a를 실행하고 signal을 호출해서 1로 증가시키고 끝났다. process 2는 wait를 해서 semaphore를 0으로 줄이고 b를 실행한다. a다음에 b실행된다.
만약 process2가 먼저 실행이되면 semaphore는 이미 0이라 process2가 대기하게 된다. 그다음에 process1이 나중에 실행하더라도 대기하는 process(process2)가 있으니까 깨우면 a가 실행되고 b가 실행된다. a가 실행되는 도중에 b가 실행되는경우? wait함수가 먼저 호출되면 2가 대기상태에 들어가게 된다. 어떤 순서로 실행되건 상관없이 a가 먼저 실행되고 b가 실행되게 제어를 한 것이다. semaphore는 0으로 초기화 했기때문에 이게 가능해진 것이다.
둘다 무한 loop를 돌고 있다. Process1은 a statement를 실행하려고 하고 Process2는 b를 반복적으로 실행하려고 한다. 두 프로세스는 concurrent하게 실행이 되고, 어떤 순서로 번갈아가면서 실행이 될지 알 수 없다. concurrent한 실행에서는 그 실행 순서를 제어할 수 없다. 두 프로세스 모두 실행하려는 statement전에 wait를 호출하여 semaphore를 감소시킨다. 원하는 statement를 실행한 다음에는 signal 함수를 써서 semaphore값을 증가시키던지, 대기하던 process를 깨우는 operation을 반복하고 있다. 여기서 2개의 semaphore를 사용하고 있다. Semaphore를 여러개 사용할 수 있는 예시이다. 초기값을 어떻게 주느냐에 따라서 a와 b statement를 진행하는 방식이 달라진다.
- S and Q = 1 : a와 b의 실행횟수 차이가 1보다 클 수 없다.
S와 Q semaphore의 초기값을 둘 다 1로 초기화하게 되면, a와 b 두 프로세스의 반복실행 방식이 어떻게 되는가. 어떤 프로세스가 먼저 진행될지는 모른다. for loop을 한바퀴 돌때마다 iteration이 추가가 된다. 이게 마냥 반복해서 실행할 수 있는게 아니라 자신의 iteration 횟수가 다른 iteration process의 횟수보다 하나 이상 더 앞서갈 수는 없는 방식으로 동기화가 된다. 만약 P1이 다 끝나고 P2가 실행된다고 가정하면, P1이 실행되면 S는 1에서 0, Q는 1에서 2로 바뀐다. 그리고 for loop을 다시 실행하면 S는 0이라서 멈춘다. 이 때 iteration차이가 1번이다. 결국 P1은 P2가 실행되지 않은경우 한번밖에 실행이 안되므로, iteration 횟수의 차이가 1보다 크게 날 수는 없다고 할 수 있는 것이다.
- one semaphore is 1 and the otehr 0
예를 들어 S = 1, Q = 0 으로 초기화 했다. 이런 경우는 다른 식으로 동기화가 된다. process들이 strict alternation으로 진행을 한다. a와 b가 번갈아가면서 concurrent 실행이 되도록 제약을 걸 수 있다. Semaphore를 1로 초기화한 process가 먼저 실행을 하고 서로 번갈아가면서 실행된다. 예시에서는 a,b,a,b, ... 이렇게 반복이 된다.
: 상황에 따라 다르다. 어떤 process가 먼저 cpu가지냐에 따라 deadlock에 빠지거나 실행이 잘될 수도 있다. 이런 경우가 debugging 하기가 힘들다. CPU가 어떤 process를 진행하냐에 따라 동기화가 잘 진행될 수도 있고, deadlock에 빠질 수도 있다. 만약 process 1이 wait(&Q)를 하고 cpu를 잃어버려 process 2가 진행하게 되면 deadlock에 빠질 수 있다. 두 process모두 첫번쨰 wait만 실행하고 deadlock이 벌어지는 것이다.
POSIX:SEM Unnamed Semaphores
: POSIX에서 제공하는 semaphore는 2가지가 있다. 먼저 unnamed semaphore. 둘 중에 하나 편의에 따라서 쓰면 되는 것이고 두 semaphore가 사용하는 system call 함수가 다르다. semaphore type에 변수를 지정해서 사용한다. semaphore type이 정의되어 있다. semaphore type은 sem_t. named 와 unnamed semaphore 모두 sem_t를 사용한다. 정수값을 갖는다.
#include <semaphore.h> 헤더파일에 존재한다. 객체를 생성하고 초기화작업이 필요하다.
#include <semaphore.h> int sem_init(sem_t *sem, int pshared, unsigned value); int sem_destroy(sem_t *sem);
sem_init()함수를 보면 파라미터 3개가 필요하다. 초기화할때 초기값이 필요하다. 초기값을 마지막 파라미터로 지정한다. semaphore은 양수값만 되기때문에 unsigned. pshared는 indicator인데, semaphore를 공유할지 안할지 결정한다. 0또는 1로 지정한다. 0으로 지정했다면 false니까 share하지 않겠다는 뜻이다. 이렇게 되면 이 semaphore를 초기화한 process의 thread들 끼리만 사용할 수 있다. 그럼 다른 process의 thread와 공유하지 않겠다는 뜻. true면 공유하겠다(nonzero) semaphore에 access할수만 있다면 다 사용할 수 있다. 초기화를 성공하면 0이 반환, 아니면 -1이 반환된다.
다 쓴 semaphore 시스템에 반환하려면 sem_destroy 사용하면 된다.
POSIX:SEM Semaphore Operations
#include <semaphore.h> int sem_post(sem_t *sem); int sem_trywait(sem_t *sem); int sem_wait(sem_t *sem); int sem_getvalue(sem_t *restrict sem, int *restrict sval);
- sem_post() : semaphore의 signal operation을 수행하는 함수이다. 이 함수는 signal-safe해서 signal handler내부에서 사용할 수 있다.
- sem_wait()
- sem_trywait() : systemcall함수에 try가 들어가면 함수의 동작을 실행할 수 있는지 try해보는것. wait를 할 수 있는지 test해보는 것. (semaphore가 0이면 못줄이니까 -> block이 되는게 아니라 바로 -1을 리턴함) 줄일 수 있는지 확인만 하고 다른 task 실행하고 싶을 때 사용.
- sem_getvalue() : 현재 semaphore의 값을 확인하고자 할 때 사용하는 함수. 어디로 반환하냐 하면 2번째 파라미터로 반환한다. 성공적으로 알아왔으면 0, 아니면 -1 리턴이 되는 것이다. sval이 output parameter가 되는 것.
*주의해서 사용해야함 : 현재 semaphore값이 어느 시점에 semaphore값인지 확인할 방법은 없다. 막 변경되고 있는 상황이였다면 호출한 순간에 semaphore값이 반환되지vcdd는 않는다. unspecified time에 반환된다.
semshared.c
#include<errno.h>#include<semaphore.h>staticint shared = 0;
staticsem_t sharedsem;
intinitshared(int val){
if (sem_init(&sharedsem, 0, 1) == -1)
return-1;
shared = val;
return0;
}
intgetshared(int *sval){
while (sem_wait(&sharedsem) == -1)
if (errno != EINTR)
return-1;
*sval = shared;
returnsem_post(&sharedsem);
}
intincshared(){
while (sem_wait(&sharedsem) == -1)
if (errno != EINTR)
return-1;
shared++;
returnsem_post(&sharedsem);
}
#include<pthread.h>#include<stdio.h>#include<string.h>#define NUMTHREADS 10intinitshared(int val);
intincshared();
intgetshared(int *sval);
/* ARGSUSED */staticvoid *increment(void *args){
int i;
for (i=0;i<100;i++)
incshared();
returnNULL;
}
intmain(void){
int error;
int i;
pthread_t tid[NUMTHREADS];
int val;
if (initshared(0)) {
perror("Could not initialize shared variable");
return1;
}
getshared(&val);
printf("Shared variable initialized to %d\n", val);
for (i = 0; i < NUMTHREADS; i++)
if (error = pthread_create(tid+i, NULL, increment, NULL))
fprintf(stderr, "Failed to create thread: %s\n", strerror(error));
printf("Number of threads created: %d\n", NUMTHREADS);
for (i = 0; i < NUMTHREADS; i++)
if (error = pthread_join(tid[i], NULL))
fprintf(stderr, "Failed to join thread: %s\n", strerror(error));
printf("All threads done\n");
getshared(&val);
printf("Shared variable now has value %d\n", val);
return0;
}
POSIX:SEM Named Semaphores
- 이름과 semaphore객체에 access할 권한만 가지고있으면 동기화를 할 수 있다. file처럼 다룰 수가 있는 것이다. 이름을 지정을 할 수 있는데, 이름은 slash로 시작을해야 한다. /로 시작하지 않는 경우 어떻게 실행될지 모른다.
#include <semaphore.h> sem_t *sem_open(const char *name, int oflag, ...);
named semaphore를 생성하거나 이미 만들어진 semaphore를 access하고자 할 때 사용하는 system call 함수가 sem_open()함수이다. 마치 file을 open할때 썼던것처럼 file을 다루는 것과 비슷하게 사용. parameter는 기본 parameter가 2개이고 oflag에 따라서 부가적인 parameter가 따라 올수도 있다. named semaphore를 생성할꺼냐, open할꺼냐 -> oflag는 0을 주면 있는것을 open하고 named semaphore를 새로 만들려고 하면 oflag에 O_CREATE flag을 주면 된다. 파일을 새로 만들어서 open 하겠다고 하는 것처럼, 이름이 미리 존재하면 이때는 그 파일이 그냥 open이 된다. (O_CREATE가 무시가 된다) semaphore도 동일하다. O_EXCL와 같이 사용할 수 있다. 이 경우에 이미 이름이 존재하면 error를 리턴한다. SEM_FAILED값이 리턴이 된다. semaphore 권한에서 실행권한은 따로 줄 수 없다. 읽기 쓰기 권한만 줄 수있다. access permission, 초기값 같이 지정해주는 것이다.
예제>
getnamed() function : named semaphore를 open하든지 생성하는 함수를 따로 정의함.
getnamed.c
#include<errno.h>#include<fcntl.h>#include<semaphore.h>#include<sys/stat.h>#define PERMS (mode_t)(S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH) //644권한#define FLAGS (O_CREAT | O_EXCL)intgetnamed(char *name, sem_t **sem, int val){
while (((*sem = sem_open(name, FLAGS , PERMS, val)) == SEM_FAILED) &&
(errno == EINTR)) ;
if (*sem != SEM_FAILED) //에러가 아니면return0;
if (errno != EEXIST) //exist(같은 이름이 존재한다)에러가 아니면return-1;
while (((*sem = sem_open(name, 0)) == SEM_FAILED) && (errno == EINTR)) ;
if (*sem != SEM_FAILED) //failed가 아니면(성공했다면)return0;
return-1;
}
//getnamed 2번째 파라미터가 output parameter임
14장의 젤 처음 critical section을 named로 해결한것.
#include<errno.h>#include<semaphore.h>#include<stdio.h>#include<stdlib.h>#include<unistd.h>#include<sys/wait.h>#include"restart.h"#define BUFSIZE 1024intgetnamed(char *name, sem_t **sem, int val);
intmain(int argc, char *argv[]){
char buffer[BUFSIZE];
char *c;
pid_t childpid = 0;
int delay;
volatileint dummy = 0;
int i, n;
sem_t *semlockp;
if (argc != 4){ /* check for valid number of command-line arguments */fprintf (stderr, "Usage: %s processes delay semaphorename\n", argv[0]);
return1;
}
n = atoi(argv[1]);
delay = atoi(argv[2]);
for (i = 1; i < n; i++)
if (childpid = fork())
break;
snprintf(buffer, BUFSIZE,
"i:%d process ID:%ld parent ID:%ld child ID:%ld\n",
i, (long)getpid(), (long)getppid(), (long)childpid);
c = buffer;
if (getnamed(argv[3], &semlockp, 1) == -1) {
perror("Failed to create named semaphore");
return1;
}
while (sem_wait(semlockp) == -1) /* entry section */if (errno != EINTR) {
perror("Failed to lock semlock");
return1;
}
//이부분이 critical section이어야 함. critical section으로 만들어줌.//critical section으로 만들기 위에서 sem_wait로 초기화되서 생성되었을거다.//맨처음 만드는것은 그 위에 getnamed(semaphore이름, ~~, ~~)while (*c != '\0') { /* critical section */fputc(*c, stderr);
c++;
for (i = 0; i < delay; i++)
dummy++;
}
if (sem_post(semlockp) == -1) { /* exit section */perror("Failed to unlock semlock");
return1;
}
if (r_wait(NULL) == -1) /* remainder section */return1;
return0;
}
-> argv[0] : 파일명 argv[1]: 프로세스 개수 argv[2]: 얼마나 쉴건지 argv[3]: named semaphore이름
성공하면 semaphore 포인터값으로 반환을 해주겠다. semaphore로 critical section을 만들기 위해서는 초기값을 1로 설정을 해야 한다. 새로 만들고 getnamed로 open해서 반환해주겠다. 처음 호출한 process가 semaphore 만들것이고 그 이후는 semaphore사용할 것이다. semaphore의 waiting queue로 대기하게 된다. process가 빌때까지. delay가 얼마나 됐건 process에서 빠져나가고 exit section에서 반환할 것이다. sem_post함수를 사용함. 대기중인 process가 있는지 보고 있으면 깨워준다. named semaphore는 ls밑에 디렉토리 구조에서 보이지는 않는다.
Closing and unlinking
#include <semaphore.h> int sem_close(sem_t *sem); int sem_unlink(const char* name);
named semaphore는 프로그램이 종료되더라도 남아있다. 그래서 named semaphore인 경우 system call함수를 사용해서 close함수, unlink함수를 사용해야 한다. close는 사용을 더 이상하지 않겠다는 뜻이지 semaphore가 삭제되는 것은 아니다. sem_unlink함수를 사용해서 삭제를 해야 한다. sem_unlink함수는 비동기식으로 작동한다. 요청이 성공적으로 전달되면 바로 전달하고 삭제는 나중에 할수있다.
destroynamed()
#include<errno.h>#include<semaphore.h>intdestroynamed(char *name, sem_t *sem){
int error = 0;
if (sem_close(sem) == -1)
error = errno;
if ((sem_unlink(name) != -1) && !error)
return0;
if (error) /* set errno to first error that occurred */
errno = error;
return-1;
}
sem_close로 close하고 unlink로 삭제한다. 에러는 sem_close 또는 sem_unlink에서 발생할 수 있다. error 코드는 첫번째 발생한 error를 errcode에 넣는걸로 되어있다. 둘 다 에러가 발생했다면 첫번째 발생한 것을 심었다.
#include<semaphore.h>#include<stdio.h>intdestroynamed(char *name, sem_t *sem);
intgetnamed(char *name, sem_t ** sem, int val);
intmain(int argc, char *argv[]){
sem_t *mysem;
if (argc != 2) {
fprintf(stderr, "Usage %s semname\n", argv[0]);
return1;
}
if (getnamed(argv[1], &mysem, 0) == -1) {
perror("getnamed");
return1;
}
if (destroynamed(argv[1], mysem) == -1) {
perror("first destroy failed");
return1;
}
fprintf(stderr,"Semaphore %s destroyed\n", argv[1]);
if (destroynamed(argv[1], mysem) == -1) {
perror("second destroy should have failed and did");
return0;
}
fprintf(stderr, "Destroy successful\n");
return1;
}
signal은 process의 event의 소프트웨어적인 notification이다. 그래서 signal의 타겟은 process이다. event가 발생했다라고 하는 사실을 target process에게 알려주기 위한 수단으로 signal이 사용된다.
signal이 생성되는 시점은 해당 event가 발생했을때 발생한 target process에게 전달되서 process가 받아들이면 'delivery되었다' 라고 하고 받으면 수신한 signal에대한 처리를 하도록 되어있다. 처리를 하면 해당 signal이 삭제된다.
즉, signal의 lifetime은 생성되고 전달되는 과정까지이다. signal이 target process가 있다고 해서 무조건 전달되는게 아니고 막히는 경우가 있는데 이런 경우 pending signal이라고 한다. 즉, signal이 생성되었는데 deliver되지 못한 경우이다.
예를 들면, 해당 target process가 받지 않겠다고 제어하는 경우이다. signal이 pending 되었다고 해서 pending 된 signal이 삭제되는게 아니고 list에 들어가 대기하게 된다. 나중에라도 process가 받아들일 상태가 되면 다시 list에서 빠져나와서 process에 전달되는 경우도 있다.
Signal을 받았을때 따로 처리 코드가 없다면 default로 정의된 signal handler를 사용한다. siganl이 도착했을 때에 수행해야 할 task를 정의해놓은 것을 signal handler라고 한다.
따로 정의 안했는데 signal 받으면 default signal handler가 실행하게 된다. catch 할 수도 있고 pending할 수도 있다. signal을 받았을때 program에서 나는 어떤 signal이 오면 signal이 왔을때 다른 task를 수행하고 싶다 할때 signal handler 함수를 따로 정의해서 이 signal handler가 호출되게끔 등록할 수 있다.
signal에서 중요한 2개의 함수는 sigaction function과 sigprocmask이다.
process가 signal을 받았을때 어떤 사용자가 정의한 다른 특정한 액션을 수행하게끔 할때 signal handler 함수를 등록해주는 함수이다. signal handler를 등록할 수 있고 signal handler는 사용자가 user-written function(정의 할 수 있다) Sigaction은 handler 대신에 SIG_DFL, SIG_IGN를 사용할 수 있다.
SIG_DFL : signal이 도착했을때 default action을 취해라
SIG_IGN : signal을 ignore해라(signal을 버려달라)
sigprocmask :
pending signal에서 '벽'같은 signal mask를 가진다. signal mask에 signal 번호를 등록할 수 있는데 등록된 signal이 오면 막히는 거다. 말그대로 masking을 하는 것이다. signal mask를 control 해야 될 필요가 있을때 signal mask제어를 sigpromask로 한다. signal을 받았을 때 어떤 action을 취할 것이냐를 나타내고 등록은 sigaction function으로 한다.
signal 수신할때 제어를 2개의 함수로 할 수 있는 것이다.
process signal mask :
현재 block된 signal들의 list를 포함하고 있다. (contain a list of currently blocked signals) 여기서 block시키고 싶은 signal 목록을 등록시키고 뺄 수 있다. block된 signal은 ignore처럼 버려지는 것은 아니다. block되면 pending signal이라고 얘기하고 pending 된것은 list에 대기. 나중에라도 process로 전달 되기도 한다.
signal mask에서 등록된 것을 삭제할 수도 있다. sigprocmaks를 통해서 signal mask에 signal을 넣거나 뺄 수 있다. 해당 operation을 sigprocmask에 parameter로 등록하게 되어있다.
Generating signals
모든 signal은 symbolic name과 unique한 ide값을 가지고 있다. signal의 이름은 SIG라는 prefix(접두어)를 가지고 있다. SIG로 시작하는 것은 signal.h를 보면 정의가 되어있다.
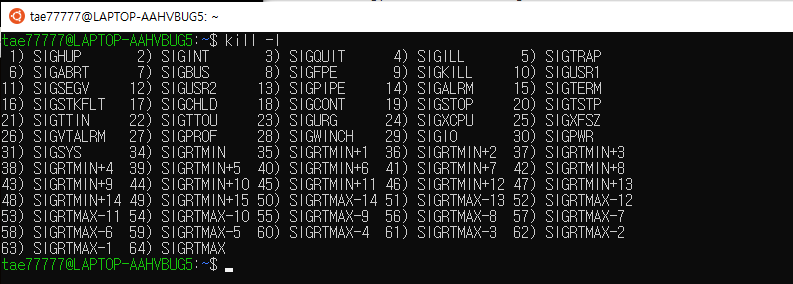
signal을 생성하는 것은 프로그램상에서 sytstem call이나 shell에서 linux 명령어로 할 수 있다. 보통은 명령어 이름과 시스템 콜 함수 이름이 똑같다. 예시로는 kill 명령어가 있다.
kill -9 명령은 돌고있는 process를 강제 종료할 때 사용한다. kill 이름때매 오해할 수 있는데 kill명령어는 기본적으로 signal을 전송하는 명령어다. kill함수를 통해서 특정 프로세스에게 signal을 보낼수가 있다. kill명령어를 보면 뒤에 2개의 parameter가 온다. 몇번 signal을 보낼건지, 누구에게 보낼건지. 타겟은 process id로 지정하면 된다. signal name으로 signal이름을 지정할 때는 앞에 SIG를 뺀 나머지 부분을 지정하면 된다.
ex> kill -s USR1 3423
ex> kill -9 3423 // (9번 signal을 보내겠다)
(9번은 SIGKILL, 2번은 SIGINT(interrrupt signal)_
-s : symbolic name의 s USR1 signal name 3423은 target process
-l option을 보면 available한 signal 보여준다.
많이 사용하는 signal에 대해서만 집중적으로 살펴볼 예정이다.
강제 종료시키는 명령
kill 함수를 통해서도 signal을 보낼 수 있다. 첫번째 파라미터는 target process id, 두번째는 전송하려는 signal id이다.
#include <signal.h> int kill(pid_t pid, int sig);
pid 파라미터에는 target process ID인데,
0이 오게 되면 caller's 의 process group의 memeber를 send하고
-1이면 permission이 있는 모든 process에게 send한다(모든 프로세스에게 이 signal을 다 전달해주는 효과를 낼 수 있다)
-10이라고 주면 절댓값 취한게 proces group의 id이다. 10이라는 group에 속한 거에 id를 주는것이다.
같은 방식으로 target process를 지정할 수 있다.
성공하면 0값이 return되고, 실패하면 -1이 return된다.
signal을 만들 때, 특정 목적을 가진 함수가 2가지 함수가 있는데
#include <signal.h> int raise(int sig);
int raise는 signal을 파라미터로 지정한 signal을 보낸 함수인데 target process는 나 자신이다.
alarm 함수는 timer의 역할을 수행하는 함수이다. 파라미터로 초단위의 숫자값을 입력하면 내부적으로 타이머가 돌고 타이머가 expire되면 alram이 다되었다고 alarm signal을 보낸다. 이것도 나 자신에게 signal을 보내는 함수인 것이다. parameter로는 초단위의 timer값을 몇 초 뒤에 alarm이 울릴것인지 정한다. 0으로 파라미터를 주면 alarm을 취소시킨다. 프로세스는 알람 signal을 받게됬을때 process는 default로 종료한다. process를 생성해서 process에게 interrupt signal이 도착하고 default 액션은 process 종료하는 것이다.
alarm함수의 리턴값은 unsigned integer -> 남아있는 초값이 return이 된다. 남아있는 시간값이 리턴이 된다. 정상적으로 완료되어 알람이 울리는 거였다면 남아있는 시간이 없으므로 0을 리턴된다. alarm함수는 error를 따로 리턴하지 않는다. unistd.h를 include하고 사용을 하면 된다.
main함수 안에서 alarm하고 10 -> 알람함수를 호출하면 sleep함수처럼 멈추는게 아니고 alarm이 설정되면 바로 return되는 것이다. alarm이 리셋되기전에 return이 되는것이고 밑으로 내려오면 타이머는 10초 돌고 있고 for로 무한 돌려서 alarm 작동하는 것을 test한다.
simplealarm.c
#include<unistd.h>intmain(void){
alarm(10);
for ( ; ; ) ;
}
Signal sets
#include <signal.h> int sigaddset(sigset_t* set, int signo); int sigdelset(sigset_t* set, int signo); int sigemptyset(sigset_t* set); int sigfillset(sigset_t* set); int sigismember(const sigset_t* set, int signo);
signal을 수신했을때 처리되는 함수들을 살펴보기 전에 sigprocmask 함수에서는 signal mask에 등록하거나 뺄 signal을 하나만 등록하는게 아니라 여러개를 사용할 수 있다. Signal sets이라는 data structure을 사용해서 할 수 있다. siganal set data structure에 여러 개를 등록할 수 있다. sigaction 함수에서도 signal set을 파라미터로 넘겨주게 된다. signal set을 어떻게 다루는지 알아볼 필요가 있다. 5개의 함수 제공하고 그 의미를 알면 된다.
1. sigaddset 함수 : sigset type의 변수에다가 signal set에 signal 추가하고 싶을때 사용한다. 두번째 파라미터는 넣고자 하는 signal번호. 그 변수에다가 숫자로 정의가 되어있고 특정 signal추가해 준다.
2. sigdelset 함수 : sigaddset 처럼 이번에는 빼고 싶은 signal이 있을때 사용.
3. sigemptyset 함수 : setset_t라는 집합에서 모든 signal을 제거하고 싶을때 사용한다.
4. sigfillset 함수 : setset_t라는 집합에서 모든 signal을 추가한다.
5. sigismember 함수 : 해당 signal이 있는지 확인할 때 사용한다. 성공하면 0을 리턴하고 실패하면 -1을 리턴한다.
signal mask의 의미 : block시킬려고 하는 signal의 목록을 가지는 것이 signal mask이고 sigset_t 타입으로 관리가 된다. signal mask를 변경하기 위해서 sigprocmask() 를 호출하면 된다.
sigprocmask()에는 3개의 파라미터가 있고 첫번째는 how, signal mask를 어떻게 수정할지 operation지정한다. signal mask에서 추가할 수도 있고 뺄 수도 있다. how에는 이미 constanat값으로 이미 정의된 것이 있다. (SIG_BLOCK, SIG_UNBLOCK,SIG_SETMAKS) 여기서 'set'은 2번째 파라미터를 의미한다.
SIG_BLOCK : 'set' signal을 add한다
SIG_UNBLOCK : 'set' signal을 delete한다
SIG_SETMASK : 'set' signal을 set한다.
add와 set은 다른 부분이 있다. 다른 signa들이 이미 등록이 된경우 add는 기존의 것을 나두고 추가하는 거고, set은 기존 무시하고 zerobase에서 다시시작하는 것을 의미한다.
여기서 3번째 파라미터도 sigset_t 타입이고 oset은 old set을 의미한다. 이 함수의 output parameter이다. 만약 oset이 NULL이 아니라면, *oset으로 바뀌기전으로 돌린다. sigset으로 수정한 다음에 변경되기전에 원래의 signal mask에 등록된 signal이 있었을건데 이전 Signal의 것을 반환해주는것이다.
sig action에서도 똑같이 사용한다. 변경되기 이전 반환하는 파라미터를 이용하는 경우는 보통 프로세스가 signal mask를 변경해야하는 경우는 중요한 작업을 처리하는 동안만 막아놓고 싶은 경우. 계속 바꾸고 있는것이 아니라. 잠깐 signal mask변경 했다가 원래 signal mask로 돌아가야 하는 경우가 생기니까 원래 signal mask값을 알고있어야한다.
원래의 값으로 다시 돌아갈려면, 다시 sigprocmask를 호출하면서 원래의 signal들로 다시 설정하면 된다. sigprocmaks(SIG_SETMASK,oset,NULL) 이런식으로 호출하면 된다.
sigprocmask()의 성공의 의미는 0, 에러가 나면 -1을 리턴한다. single thread process에만 사용해야 한다. single thread process레벨에서는 sigprocmask함수를 사용하고 만약 다중 thread 프로세스를 실행한다고 하면 pthread_sigmaks()가 사용되어야 한다.
SIGSTOP, SIGKILL과 같은 signal은 signalmask로 막을 수 없다.
Signal masks and sets example
sigset_t newsigset;
if((sigemptyset(&newsigset) == -1 || (sigaddset(&newsigset, SIGINT) == -1)) perror("Failed to initialize the signal set"); else if(sigprocmask(SIG_BLOCK, &newsigset, NULL) == -1) perror("Falied to block SIGINT");
sigemptyset으로 signal set을 비우고 SIGINT을 추가해주고 싶다. sigset_t 변수를 먼저 준비해야한다. 초기화부터 하기위해서 sigemptyset으로 비우고 sigaddset으로 sigset변수에 SIGINT변수를 추가하겠다.
else if문 안에서 sigprocmask를 호출한다. 현재 signalmask에 두번째 파라미터로 newsigset을 넘기면 interrupt signal이 추가가 된것이다. interrupt signal(SIGINT)은 pending이 된다.
struct sigaction{ void (*sa_handler)(int); // SIG_DFL, SIG_IGN or pointer to function sigset_t sa_mask; //additional signals to be blocked during execution of handler int sa_flags; //special flags and options void (*sa_sigaction) (int, siginfo_t *, void *); // realtime handler }
sigaction function은 process가 signal받았을때 어떻게 할것이냐. 내가 수행할 task를 signal handler함수로 정의하고 signal을 받았을 때 수행할 action을 등록하는 함수다. sigaction은 파라미터 3개이다.
1) target signal : action할 signal number
2) act : sigaction이라는 구조체 타입으로 어떤 action을 취할지 명시
3) oact : old action 등록된 action 이전의 정보를 반환해주는 output parameter
각 필드값을 설정하고 sigaction을 호출해야 한다. 각 필드를 알고있어야 한다. sigaction에서는 첫번째만 사용할 것이다!
void(*sa_handler)(int); void 리턴타입에 integer 타입에 signal 번호가 전달이 된다.
signal handler는 void를 return하고 하나의 integer parameter를 가진다. sa_handler에는 SIG_DFL(signal의 default action 회복), SIG_IGN(signal을 ignore)를 줄 수 있다.
반복문을 돌면서 0과 1사이의 interval에 있는 값인 x에 sin값의 평균을 계속 계산하는 프로그램이다.
뭘 계산하는지는 중요하지 않음. 반복해서 계산을 수행한다는 것이 중요하다. 프로그램이 돌다가 사용자가 Interrupt signal을 ctrl+c를 눌러서 보낸다. Interrupt signal의 default action은 프로그램을 종료하는 것이다. 원래라면 종료가 되버린다. 그런데 이 예제는 중간에 interrupt signal을 받으면 반복문을 돌고있는중에 어느 시점에서 signal이 올지 알 수 없다. Signal handler를 등록해서 flag값을 변경한다.
signal을 받는다는 것은 프로그램에서 asynchronous한 이벤트이다. (언제 발생할지 모른다.) 여기서는 좀더 gracefully terminatie 하도록 수정을 한 예제이다. interrupt signal이 도착하면 signal handler를 등록하는 것이다. signal handler에서는 flag변수를 선언해서 flag변수값을 변경하는 signal handler이다. while문 조건식이 거짓이 되도록 살짝 바꾸고 signal handler에서 return 한것이다. while문을 빠져나가서 정상적으로 종료가 되도록한다.
반복문 돌다가 signal 도착하면 멈추고 signal handler routine이 실행되고 나면 다시 돌아와서 중단되었던 시점 진행한다.
signalterminate.c
#include<math.h>#include<signal.h>#include<stdio.h>#include<stdlib.h>staticvolatilesig_atomic_t doneflag = 0;
/* ARGSUSED */staticvoidsetdoneflag(int signo){ //signal받았을때 while문을 빠져나오겠다
doneflag = 1;
}
intmain(void){
structsigactionact;int count = 0;
double sum = 0;
double x;
act.sa_handler = setdoneflag; /* set up signal handler */
act.sa_flags = 0; //별다른 옵션 없다if ((sigemptyset(&act.sa_mask) == -1) ||
(sigaction(SIGINT, &act, NULL) == -1)) { //target signal은 SIGINTperror("Failed to set SIGINT handler");
return1;
}
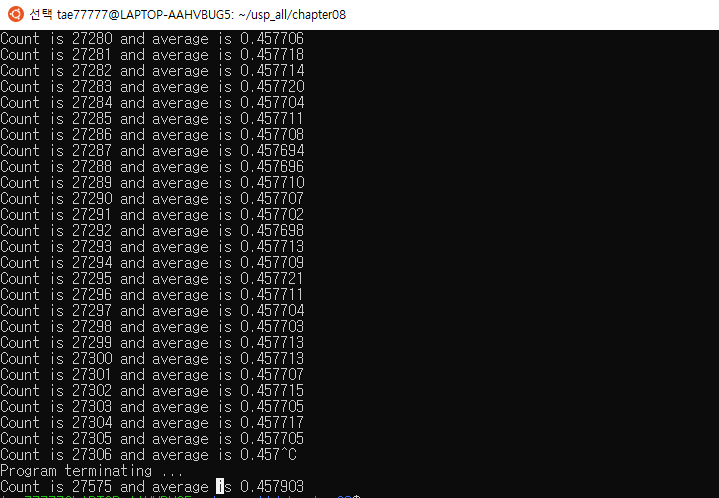
while (!doneflag) {
x = (rand() + 0.5)/(RAND_MAX + 1.0);
sum += sin(x);
count++;
printf("Count is %d and average is %f\n", count, sum/count);
}
printf("Program terminating ...\n");
if (count == 0)
printf("No values calculated yet\n");
elseprintf("Count is %d and average is %f\n", count, sum/count);
return0;
}
setdoneflag는 void return 타입에 int를 갖는 함수로 doneflag값을 1로 설정하는 함수이다. doneflag는 while문에서 doneflag가 0일때 계속 계산하도록 한다.
계산을 signal 받았을때 doneflag를 1로 바꾸면 while문에서 다음조건식 검사할때 바뀌어있으므로 while문 빠져나가도록 조절한다. 그 signal 함수를 act.sa_handler에 등록한 것이다. sigaction을 이용해서 action을 등록한다. 타겟 시그널은 SIGINT가 된다. setdonefla를 &act로 등록하고 변경되기전은 NULL로 둔다. interrupt signal이 오면 setdoneflag함수를 호출해라. 계속 sin(x)값을 더해간다.
프로그램 실행이 순서대로 되지 않고 signal이 도착하면 점프해서 signal handler루틴이 진행하고 리턴되면 원래로 돌아온다. 고려해야되는 부분은 doneflag라는 변수는 critical section으로 처리해야 한다. 주로 다중 프로세스 또는 다중 스레드를 다룰때 사용한다. 어떤 변수가 있을때 변수를 여러 프로세스가 접근할 수 있다면 critical section으로 처리해야한다. 동시에 수정한다면 문제가 발생하기 때문이다(conflict)
여러 변수가 동시에 접근 못하도록 critical section으로 만들기 위해 mechanism을 제공한다. process간 동기화할 때 다시 얘기한다. 여러 프로세스, 여러 스레드 간에 동기화 하는 부분은 아니지만, 순서대로 access 하도록 제어를 해준다. 시스템 콜 함수 같은 것을 사용해야 한다. doneflag라는 변수는 메인 함수에서도 access 하고 signal handler에서도 access 할 수 있어야한다. signal handler와 main program이 access할 수 있는 변수이다. signal handler에 의해서 doneflag에 동시에 접근할 수 있기때문에. 여기서도 while문을 계속 반복해서 사용하는데 while문에서 doneflag를 읽을려 하는데 그때 signal이 도착을 했을때. -> 읽는 작업을 중단하고 signal 핸들러를 호출한다.
이 작업은 마치 양쪽에서 doneflag를 서로 다른 작업으로 access하는것과 같은 효과가 일어난다. 충돌문제가 똑같이 발생할 수 있다. doneflag를 critical section으로 만든다. 어떻게 critical section으로 만들었느냐? doneflag는 일반 int값이였는데 sig_atomic_t로 선언한게 critical section으로 만든것이다. 이 타입으로 선언하면 OS레벨에서 access하기 시작했으면 종료될때까지 OS가 막아준다. volatile 키워드로 변수를 사용하면 doneflag에 access할때 C compiler에 대해 항상 메모리에서 직접 참조를 해라 라고 선언한것이다. 최적화 과정중 register값을 그냥 참조한다. volatile로 선언하면 register에서 load하지말고 메모리에서 직접 읽어라. doneflag는 외부에서 변경될 여지가 있기 때문에. 외부는 signal handler를 의미한다. 매번 메모리에서 읽어라고 하는 것이다.
program 8.6
averagesin.c
반복문으로 수행하다가 10000번째 iteration마다 중간계산 결과를 buffer에다가 저장하고 그다음에 계속 반복하고 10000번째 계산 결과를 저장하고 이런식으로 반복작업을 수행. target signal에 SIGUSR1이 도착하면 signal handler에서는 buffer의 내용을 읽어서 화면에 출력해 준다. main 부분과 signal handler가 동시에 buffer에 접근할수도 있다. 그러므로 buffer access하는 부분을 critical section으로 바꿔야 한다.
#include<errno.h>#include<limits.h>#include<math.h>#include<signal.h>#include<stdio.h>#include<stdlib.h>#include<string.h>#include<unistd.h>#define BUFSIZE 100staticchar buf[BUFSIZE];
staticint buflen = 0;
/* ARGSUSED */staticvoidhandler(int signo){ /* handler outputs result string */int savederrno;
savederrno = errno;
write(STDOUT_FILENO, buf, buflen);
errno = savederrno;
}
staticvoidresults(int count, double sum){ /* set up result string */double average;
double calculated;
double err;
double errpercent;
sigset_t oset;
sigset_t sigset;
if ((sigemptyset(&sigset) == -1) ||
(sigaddset(&sigset, SIGUSR1) == -1) ||
(sigprocmask(SIG_BLOCK, &sigset, &oset) == -1) )
perror("Failed to block signal in results");
if (count == 0)
snprintf(buf, BUFSIZE, "No values calculated yet\n");
else {
calculated = 1.0 - cos(1.0);
average = sum/count;
err = average - calculated;
errpercent = 100.0*err/calculated;
snprintf(buf, BUFSIZE,
"Count = %d, sum = %f, average = %f, error = %f or %f%%\n",
count, sum, average, err, errpercent);
}
buflen = strlen(buf);
if (sigprocmask(SIG_SETMASK, &oset, NULL) == -1) //이전 상태로 되돌린다(USR1넣은거 되돌리기)perror("Failed to unblock signal in results");
}
intmain(void){
int count = 0;
double sum = 0;
double x;
structsigactionact;
act.sa_handler = handler;
act.sa_flags = 0;
if ((sigemptyset(&act.sa_mask) == -1) ||
(sigaction(SIGUSR1, &act, NULL) == -1) ) {
perror("Failed to set SIGUSR1 signal handler");
return1;
}
fprintf(stderr, "Process %ld starting calculation\n", (long)getpid());
for ( ; ; ) {
if ((count % 10000) == 0)
results(count, sum);
x = (rand() + 0.5)/(RAND_MAX + 1.0);
sum += sin(x);
count++;
if (count == INT_MAX)
break;
}
results(count, sum);
handler(0); /* call handler directly to write out the results */return0;
}
results함수는 10000번째마다 buffer에 쓰는 함수. handler는 화면에 출력해주는 signal handler. snprintf는 buffer에 print하는 함수다. String값을 출력한다. 제일 끝에 nulll을 추가해준다.(snprintf)
메인에서는 for문에서 무한으로 반복하다가 10000번째에 results함수를 호출하고 usr handler signal오면 handler함수로 뛰어서 write 함수를 사용한다.
USR1 signal이 오면 중간계산 결과를 읽어서 출력해준다. 화면에 지금까지 계산결과를 읽어서 출력해준다. buffer를 main과 signal handler가 동시 접속한다.
어떻게 buffer부분을 critical section으로 만들것이냐. signal에 의해서 방해받지 않으면 된다. result 함수 내에서 buffer를 다 쓰고 난다음에 signal 제어하기 위해서 signalmask를 사용했는데 sigprocmask를 사용해서 signal을 하나 막으면 된다. (USR1 signal을 block시키고 buffer를 access한다) 방해받지 않고 buf를 access할 수 있다. 다시 문을 열고 buffer를 access하는 동안 critical section이 될 수 있다. 방해받지 않고 buffer를 access 할 수 있다. USR1 signal이 도착할 것이고 완료된 버퍼의 내용을 읽고 화면에 출력한다.
마지막 if에서 sigprocmask를 다시 호출해서 &oset으로 다시 되돌린다. (이전 상태로 되돌린다)혹시나 pending되었던 USR1 signal있으면 다시 process에 되돌릴 수 있는것이다.
Waiting for signals
main을 진행하다가 특정 signal이 오면 그 다음 작업을 진행하고 싶을때 다음 작업이 시작되기 위해 특정 signal이 온다. system call함수로 signal을 기다리는 함수가 제공된다. -> pause(), sigsuspend(), sigwait()
user-defiend handler가 실행될 수 있는 시그널이 오면. pause를 이용해서 아무 시그널 오면 동작하는게 아니라 특정 시그널이 오면. 다른 시그널이 오면 다시 잠들고 하다가 원하는 signal이 오면 깨서 다음 작업을 수행하고 싶은것이다. pause함수는 항상 -1을 리턴하고 만약에 signal이 process에서 catch 되었으면 signal handler가 불린다. signal handler가 불려서 다 실행이 되고 단다음에 pause함수가 리턴이 된다. 원하는 signal이 올때까지 기다리도록 밑에 함수를 사용한 것이다. while문으로 원하는 signal 올때까지 기다림. -> sig_atomic_t 타입으로 sigreceived를 선언함. 0인 동안의 pause로 계속 suspend 하겠다. 다른 signal이 도착하면 signal handler가 불리고 같은지 비교하고 리턴한다. 그럼 pause함수도 리턴되고 sigreceived가 0이기 때문에 다시 pause함수 부르고 잠들겠다.
이 코드는 완벽한 코드가 아니다! (8.21)
문제 상황 :
타이밍의 문제 -> signal은 asynchronous이기 때문에 애매한 시점에 동작하게 되면 시스템이 오동작할 수 있다. while의 조건식을 검사해서 0이다라는 것을 확인하고 pause를 호출하려고 하는데 target signal이 이때 도착했다면 중단하고 signal handler가 불린다. sigreceived를 1로 바꾸고 리턴한다. pause함수를 부르고 thread는 suspend된다. on target signal을 알아차리지 못하고 잠들었다. 만약 target signal이 마지막이였다면 thread는 잠들 수 밖에 없다.
해결하기 위한 방법? -> signalmask를 제어해서 막은 다음에 진행하면 되지 않을까? while 위에서 막으면 언제 풀어줘야하나? 다시 풀고 pause함수를 부르면 되는건데 pause부르기 전에 unblock하면 되는데 이것도 문제이다. 문을 열어놓고 부르겠다 해도 두 함수호출은 automatic한 것이 아니라서 또 문제가 생길 수 있다. 동시에 수행하도록 해야 된다.
-> 시스템 콜 함수 sigsuspend를 사용한다.
Sigsuspend(pause는 불안하니까 이걸 사용해라)
#include <signal.h> int sugsuspend(const sigset_t* sigmask);
파라미터로 sigset_t 타입의 포인터를 넘겨준다. -> 두가지 작업 동시 진행해준다.
파라미터로 넘어온 sigmask를 signal mask로 설정하고 호출한 process를 suspend시키는 작업을 동시에 수행해준다. 이 함수도 언제 깨어나냐 하면 프로세스가 signal을 캐치하면 리턴된다. pause함수와 마찬가지로. sigmask block시켰던 target을 unblock하는 걸로 이용하면 사용을 할 수 있겠다. target signal을 막아놓고 풀면서 suspend하기 위해서 sigsuspend호출할때 target signal을 뺀 signal set을 넣어준다.(sigmask는 target signal을 뺀 sigset) process가 suspend 되면서 문을 열어줘야 target signal이 도달할 수 있다. sigsuspend가 리턴이 되면 변경되었던 부분이 원래 상태로 자동으로 복구가 된다. sigsuspend를 잘 이해해야 한다.
sigsuspend가 깨어날려면 target signal이 와야한다. 다른 signal은 도착하지도 않기 때문에. while문이 아니라 if문으로 바꼈다. signal set 변수를 3가지를 준비한다. maskall에는 모든 signal을 담을 것이다. maskmost에는 target signal만 빼놓은 것. 다른 signal은 도착도 못한다. maskold는 이전 signal 저장을 위해서. 모든 signal로 다 채우고 다 채운다음에 sigdelset에서 targetsignal만 뺀것이다. amskmost signalset은 target signal만 빠짐. 아무 시그널이나 도착해도 pending이 된다. sigsuspend(&maskmost); targetsignal만 문을 통과할 수 있다.
int signum = SIGUSR1; //target signal sigfillset(&maskall); //모든 signal sigfillset(&maskmost); //target signal제외 모든 signal(일단 여기서는 fillset으로 다 채워줌) sigdelset(&maskmost,signum); sigprocmask(SIG_SETMASK,&maskall,&maskold); if(sigreceived ==0 ) sigsuspend(&maskmost); // target signal 도착했을때만 깨어난다. -> while문 굳이 필요없다. sigprocmask(SIG_SETMAKS,&maskold,NULL);
이전에는 다른 signal까지 모두 막았지만 여기서는 다른 signal도 통과했을때도 깨어날 수 있게 -> while문으로 변경됨. signalset_t 이 3가지 사용. maskblocked, maskold, maskunblocked, 2개의 signalset을 준비. 처음에 sigprocmask를 써서 &maskblocked의 현재 시그널 번호들을 가지고 와서 양쪽에 모두 maskunblocked도 기존의 original set 정보를 가지고 온다. 새로 설정되는게 아니라 변경되기전 signalmask값을 얻어오기 위해서 maskblocked에는 target signal 추가한 것. maskblocked는 original에서 target signal만 추가한것.
maskunblocked는 original에서 target signal 뺀 버전.
다른 버전 - target signal 말고 다른 signal은 허용
static volatile sig_atomic_t sigreceived =0; sigset_t maskblocked, maskold, maskunblocked; int signum = SIGUSR1; //원래 signal set 정보를 다 가져옴(변경되기전을 가져오기 위함) sigprocmask(SIG_SETMAKS, NULL, &maskblocked); sigprocmask(SIG_SETMAKS, NULL, &maskunblocked); sigaddset(&maskblocked, signum); //target signal을 더한다(original + target signal) sigdelset(&maskunblocked, signum); //target signal을 뺸다 (original - target signal) sigprocmask(SIG_BLOCK, &maskblocked, &maskold); while(sigreceived ==0) sigsuspend(&maskunblocked); sigprocmask(SIG_SETMASK, &maskold, NULL);
target signal이 오면 막고 나머지는 while문을 실행하겠다. 막는게 중요하다. 다른 signal은 도착하도록 두겠다. process를 suspend시킴과 동시에 targetsignal에서 빼고 프로세스가 잠든것이다. targetsignal도 도착할 수 있고 아닌 signal도 도착하는것. target signal이 도착하면 1로 변경하고 return하면 위로 올라가서 1로 변경된것을 알고 while문을 빠져나가서 signal mask를 원래대로 돌려놓고 수행한다. sigsuspend 리턴될때 원복된다. 원래로 되돌리기 위해서 sigprocmask를 호출함.
Sigwait
#include <signal.h> int sigwait(const sigset_t *restrict sigmask, int *restrict signo);
int* restrict signo 는 output parameter라고 생각하면 된다.
sigmask에 있는 signal이 오기전에 계속 block된다.
sigwait함수의 작동방식 :
호출하게 되면 프로세스는 block이 된다. 첫번째 파라미터(sigmask)에서 지정한 signal들 중에 아무거나 pending이 되면, (pending이 되었다는 것은 signal들이 signalmask에 의해 막혔다는 얘기) sigwait함수는 peding된 signal을 pending list에서 삭제한다. 그리고 그냥 return을 한다. (sigset_t에는 signal들을 담을 수 있다) return을 하면서 삭제한 signal번호를 signo(두번째 파라미터)로 반환을 해준다. (즉, 원하는 signal을 받으면 signo에 담아서 return 해주겠다는 의미)
sigwait함수를 가지고 어떻게 내가 원하는 signal이 올때까지 기다릴 수 있겠느냐 :
(sigsuspend와는 동작이 조금 다르다 -> sigsuspend함수는 signalset type의 parameter가 있었는데 이 signalset parameter에 우리가 기다리는 target signal을 뺀 signalset을 넣었었다.)
sigwait에서는 우리가 원하는 signal을 sigset에 넣어놓고 호출하게 된다. sigwait에서도 sigsupsend와 마찬가지로 sigprocmask로 target 하는 signal을 일단 막고 시작하는 것은 동일하다. 그래서 우리가 원하는 signal이 pending이 되야 sigwait함수가 pending된 것을 삭제하고 return을 해주는것, sigsuspend함수는 signal mask를 직접 건드렸었다. 그런데 sigwait함수는 signal mask를 전혀 건드리지 않는다)
ex>
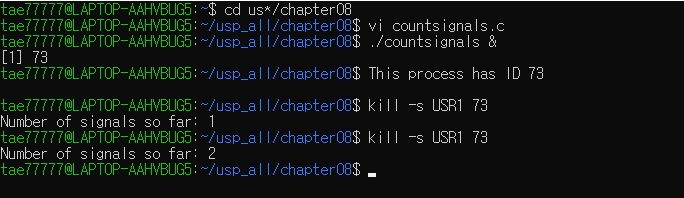
1#include<signal.h>2#include<stdio.h>3#include<unistd.h>45intmain(void){
6int signalcount = 0;
7int signo;
8int signum = SIGUSR1; //target signal9sigset_t sigset;
1011if ((sigemptyset(&sigset) == -1) || //일단 비우고12 (sigaddset(&sigset, signum) == -1) || // target signal13 (sigprocmask(SIG_BLOCK, &sigset, NULL) == -1)) //target signal을 sigmask에서 block14perror("Failed to block signals before sigwait");
15fprintf(stderr, "This process has ID %ld\n", (long)getpid());
16for ( ; ; ) {
17if (sigwait(&sigset, &signo) == -1) { //USR1이 pending되길 기다린다18perror("Failed to wait using sigwait");
19return1;
20 }
21 signalcount++;
22fprintf(stderr, "Number of signals so far: %d\n", signalcount);
23 }
24 }
countsignals.c를 background에서 돌려보기.
Errors and Async-signal safety
process의 실행흐름이라는 것이 언제든 signal이 도착하면 하던 작업을 멈추고 signal handler가 호출이 되어야 하기 때문에 실행에 점프가 생긴다. 그럼에 따라서 발생하는 문제들이 있을 수 있다. 그래서 고려해야 하는 상황들이 있다.
1. signal에 의해서 interrupt된 POSIX functions(시스템 콜 함수) -> 함수를 호출했는데 그 시스템 콜 함수가 -1(에러)를 리턴하고 에러 코드가 interrupt인 경우.
: 다시 시작을 해야 될건지 말건지를 한번 살펴봐야 한다. -> 메뉴얼 페이지 같은 것을 확인해서 그 함수가 signal에 의해서 interrupt되는지 확인해 볼 필요가 있다. EINTR로 설정된다면 중간에 자기 task를 수행 못하고 외부 요인에 의해서 -1을 리턴한 함수이다. 그렇지 않은 함수도 있다.
어떤지 한번 살펴보고 interrupt 될 수 있는 함수라면 다시 호출을 해서 explicit하게 호출하던지 r_~함수로 개선한것처럼 다시 호출하던지. 아니면 직접 -1을 에러를 리턴한 경우 다시 호출하도록 다시 호출하던지. 먼저 내가 사용하는 함수가 interrupt될수있는지 아닌지 man page로 확인!
2. signal handler를 사용할 떄 signal handler가 nonreentrant 함수를 호출하는 경우 위험할 수 있다. signal handler안에서 signal handler함수를 구현할 때, 그 안에서 호출하는 다른 함수는 nonreentrant 함수를 호출하는 것을 피하는게 좋겠다. reentrant함수라는게 어떤 함수를 호출했는데 그 함수의 동작이 끝나지 않았는데 다시 누군가에 의해서 함수가 다시 호출이 되어도 문제없이 실행이 되는 함수이다. func()라는 함수가 있는데 이 함수를 호출하면 함수안에 있는 내용이 차례로 실행이 되다가 중단이 되고, 다른 thread가 func()를 호출하는 것이다. 그럼 실행하던 구문이 있는데 새로 func()가 호출되는데 문제없이 task가 수행되면 reentrant, task에 수행이 있어서 문제가 발생하면 nonreentrant함수라고 얘기를 한다.
결론은 signal handler함수 작성할때 함수안에서 호출하는 함수는 reentrant한 함수를 호출해라. signal 함수 안에서 호출해도 안전한 함수 -> async-signal safe한 함수이다. POSIX library에서 제공하는 많은 system call 함수 중에 많은 함수들이 async-signal safe한 함수가 아니다. 목록은 table 8.2에 나온다. table에 있는 것은 안전.
---> averagesin.c
#include<errno.h>#include<limits.h>#include<math.h>#include<signal.h>#include<stdio.h>#include<stdlib.h>#include<string.h>#include<unistd.h>#define BUFSIZE 100staticchar buf[BUFSIZE];
staticint buflen = 0;
/* ARGSUSED */staticvoidhandler(int signo){ /* handler outputs result string */int savederrno;
savederrno = errno;
write(STDOUT_FILENO, buf, buflen);
errno = savederrno;
}
staticvoidresults(int count, double sum){ /* set up result string */double average;
double calculated;
double err;
double errpercent;
sigset_t oset;
sigset_t sigset;
if ((sigemptyset(&sigset) == -1) ||
(sigaddset(&sigset, SIGUSR1) == -1) ||
(sigprocmask(SIG_BLOCK, &sigset, &oset) == -1) )
perror("Failed to block signal in results");
if (count == 0)
snprintf(buf, BUFSIZE, "No values calculated yet\n");
else {
calculated = 1.0 - cos(1.0);
average = sum/count;
err = average - calculated;
errpercent = 100.0*err/calculated;
snprintf(buf, BUFSIZE,
"Count = %d, sum = %f, average = %f, error = %f or %f%%\n",
count, sum, average, err, errpercent);
}
buflen = strlen(buf);
if (sigprocmask(SIG_SETMASK, &oset, NULL) == -1)
perror("Failed to unblock signal in results");
}
intmain(void){
int count = 0;
double sum = 0;
double x;
structsigactionact;
act.sa_handler = handler;
act.sa_flags = 0;
if ((sigemptyset(&act.sa_mask) == -1) ||
(sigaction(SIGUSR1, &act, NULL) == -1) ) {
perror("Failed to set SIGUSR1 signal handler");
return1;
}
fprintf(stderr, "Process %ld starting calculation\n", (long)getpid());
for ( ; ; ) {
if ((count % 10000) == 0)
results(count, sum);
x = (rand() + 0.5)/(RAND_MAX + 1.0);
sum += sin(x);
count++;
if (count == INT_MAX)
break;
}
results(count, sum);
handler(0); /* call handler directly to write out the results */return0;
}
--> signal handler함수 내에서 printf함수는 async signal safe한 함수가 아니다. 대신 write함수는 async-safe한 함수이다. (그래서 위에서 printf함수 대신에 write함수를 사용하였다)
3. errno변수를 다룰때
- main()이 있고 signal handler()함수가 있다고 가정할때 main()에서 a()라는 systemcall을 호출하고 -1이 리턴되었을때 errno=ERROR코드가 설정되었을때, error handling을 실행하는 와중에 signal이 와서 작업을 중단하고 signal handler가 호출되었는데 signal handler에서 진행하면서 이 안에서 또 시스템 콜 함수b()를 호출했는데 이 함수도 error가 리턴이 되었다(error코드 설정되는 함수) 이 errornumber함수에 새로운 것이 덮어씌워지게 된다. error코드가 main에서 설정되었던것이 덮어씌워진다. main에서 볼려고 했던 error 코드가 없어졌다. main에서 중단되었던 부분에서 error코드를봤는데 main에서 원래 error코드가 아니라 signal handler에서의 error코드를 보게 되는 문제점이다. 피할려면 signal handler함수에 진입했을때 혹시나 main에서 errorcode를 사용하려 했을때 errornumber를 임의의 temp =errno에 저장해두고 사용해라. 그다음에 b()함수를 호출하면 원래의 errornumber가 다른 함수에 있기 때문에 저장해놓은 값을 b()호출한뒤 되돌리면 이런 문제를 해결할 수 있다.
: program 실행 sequence를 jump 할 수 있는 system call함수의 동작에 대해서.
실행 구문을 점프하는 것이 필요한 경우
1. 프로그램들이 siganl을 이용해서 error handling할때 사용할 수 있다.
2. 긴계산 작업이였는데 ctrl+c 로 프로세스가 종료되는 대신에 처음부분으로 가서 돌아가는 경우.
Ex)
sequence를 변경하기 위해서는 indirect한 방법으로도 할 수 있는데 ctrl+c 로 interrupt signal이 왔을 때 응답으로 flag변수를 하나 설정해서 뭐냐에 따라서 어떤 구문을 실행하게 프로그램 짜기(복잡함)
-> signal이 왔을때 실행 sequence를 변경하기 위한 POSIX에서 제공하는 sigsetjmp , siglongjmp 를 사용할 수 있다.
jump 할 지점 설정하기, 실제 설정했던 지점으로 jump시키는 함수.
Sigsetjmp and siglongjmp
#include <setjmp.h> void siglongjmp(sigjmp_buf env, int val); int sigsetjmp(sigjmp_buf env, int savemask);
sigsetjmp()
- 점프할 지점 설정 -> 성공하면 0이 리턴. 리턴되는 case가 2가지이다. (fork()에서 자식,부모 다르게 리턴되는 것처럼)
---> 직접 sigsetjmp를 호출하면서 jump할 지점 설정했을때 0 리턴. 나중에 다시 점프해서 돌아왔을때 리턴값 받아왔을때 아래 실행. 이때는 longjmp 2번째 파라미터값이 이리로 리턴된다.
- 첫번째 파라미터 : sgjmp_buf env안에 현재 이시점에 실행 context를 저장해놓는 변수. 이 지점으로 점프할꺼다라는 것이 저장.
- 두번째 파라미터 : savemask -> 0이 아닌 값이면 정보를 저장할때 jump될때 실행했을 당시에 signalamsk도 저장한다.
0이면 저장하지 않고 현재 signal mask값을 저장할지 안할지 설정
sigsetjmp의 값이 0이면 jump할 위치를 설정한 것이다. 0이 아니면 다시 jump해서 돌아온것이다.
siglongjmp() -> 저장된 위치로 다시 제어를 전달
- 어디로 jump 할지 위치는 1번째 파라미터에 저장. 점프할 때 점프한 지점으로 리턴시킬 값이 2번째 파라미터. 첫번째 파라미터는 점프할때 여러지점에서 sigsetjmp 호출했으면 어디로 jump할건지 지정할때 첫번째 파라미터로 점프할 지점 구분할 수 있다.
ex>sigjmp.c
1#include<setjmp.h>2#include<signal.h>3#include<stdio.h>4#include<unistd.h>56static sigjmp_buf jmpbuf; //점프할 지점을 설정할 때 사용하는 변수7staticvolatilesig_atomic_t jumpok = 0; // flag 변수 역할 수행, jump해도 되느냐 1이되면 점프해도 된다.89/* ARGSUSED */10staticvoidchandler(int signo){
11if (jumpok == 0) return; //준비상황이 안됐으면 그냥 return12siglongjmp(jmpbuf, 1); //준비되었으면 jmpbuf에 설정된 곳으로 jump하고 return 1로 전달13 }
1415intmain(void){
16structsigactionact;1718 act.sa_flags = 0;
19 act.sa_handler = chandler;
20if ((sigemptyset(&act.sa_mask) == -1) ||
21 (sigaction(SIGINT, &act, NULL) == -1)) {//target signal을 SIGINT이다 ctrl+c누르면 jump를 하겠다22perror("Failed to set up SIGINT handler");
23return1;
24 }
25/* stuff goes here */26fprintf(stderr, "This is process %ld\n", (long)getpid());
27if (sigsetjmp(jmpbuf, 1)) //jmpbuf에 필요한 정보 저장, signalmask에 1저장-> 최초는 0-> 출력 x28fprintf(stderr, "Returned to main loop due to ^c\n"); //jump해서 돌아왔을때만 출력29 jumpok = 1; //점프할 준비가 되었음.30for ( ; ; ) //대기중-> 안그러면 process 끝나버림.이 상황에서 ctrl+c누르면 signalhandler호출.-> sigsetjmp로 jump하는 것이다.31 ; /* main loop goes here */32 }
Programming with asynchronous I/O
-Asynchronous I/O : 비동기 I/O 수행하는 것이 signal과 상관이 있음. 이때까지 호출했었던 system call 함수는 synchronous함수를 호출한다. read() write()는 synchronous한 I/O. 함수를 호출한 다음에 함수 task완료될때까지 기다리고 task완료되면 다음으로 하는. read나 write나 요청한 바이트만큼 못해도 1바이트라도 하면 자신의 일을 수행한것이다. asynchronous로 호출이 되었다 하면 지금 읽을 데이터가 10byte를 읽으라고 했는데 10byte가 안되었으면 read가 블럭되서 기다리지 않고, 읽을 수 없는 상황이면 바로 return하고 백그라운드에서 OS에 의해서 계속 진행을 하게 된다. 함수는 리턴을 한다. 요청한 I/O가 끝나지 않았지만 마냥 기다리지 않고 다른 task를 수행할 수 있게 되는것이다. 대신 문제는 다른 task를 수행 하다가 요청한 background 진행되는 I/O가 완료되었다면 다른 task수행하고 있는것에서 어떻게 알 수있게 되느냐? 요청된 I/O가 완료되었을 때 알 수 있는 방법을 제공해 준다. (백그라운드에서 진행되고 있는 작업이 종료되었다는 사실을 알려주는 것이다)
별도로 확인하고 I/O가 일어난 byte수가 제공이 되는 것이 aio_return() 과 aio_error()함수이다. 대신 async는 sync보다 프로그램 로직이 복잡해질 수 있다.
#include <aio.h> int aio_read(struct aiocb* aiocbp); int aio_write(struct_aiocb* aiocbp);
(함수의 역할만 살펴봄)
parameter타입이 aiocb라는 구조체 타입이다. aiocb라는 구조체 변수를 먼저 준비해야한다. 구조체 안에 field중에 기본 3가지(write,read에서 있었던 파라미터)가 들어가있다.
aio_read() : 읽기 작업을 위한 요청을 async하게. 요청이 queue에 들어가서 진행된다. 성공은 0, 아니면 -1
aio_write() : 쓰기 작업을 위한 요청 async.
aiocb 구조체 내용
- int aio_fildes;
- volatile void* aio_buf;
- size_t aio_nbytes;
- off_t aio_offset; --> I/O의 시작 지점을 알려준다.
- int aio_reqprio; --> 요청의 우선순위를 낮춘다
- struct sigevent aio_sigevent : sigevent type의 구조체를 사용해야될때가 있다. I/O가 끝났다는 사실을 통보받기. 함수를 직접 호출해서 완료가 되었는지 확인하는 방법. 또다른 방법은 field를 이용하는 방법. I/O가 완료되었을때 OS가 signal로 통보를 받을건지 말건지. 몇번 signal로 통보받을지 field에서 결정할 수 있다. 다른 것을 수행하다가 signal handler에서 수행하도록 코드를 짜면 된다. 완료되었다는 것을 통보받을 수도 있다. field안에 sigev_notify라는 field가 있고 NONE으로 설정하면 통지받지 않겠다는 뜻이고 몇번 signal로 할거냐면 signo field안에 통지받고자 하는 signal number를 설정해두면 된다.
aio_return()과 aio_error()에는 완료된 I/O의 return값을 받기 위한 위에서 따로 호출하는 함수. 완료된 I/O의 return값을 받아올 수있다. 먼저 비동기 I/O가 return되었는지 확인해야 한다. 아니면 수동으로 error()로 확인하면 된다. 진행상황을 monitor하는 함수이다. 만약에 0이면 완료되었다는 뜻이고 진행중이면 EINPROGRESS값이 반환된다. 아니면 error code값이 리턴된다.
aio_suspend : 호출한 프로세스를 기다린다. 파라미터로 지정한 asynchronous가 완료될때까지 기다릴때 호출할 수 있다. 완료가 되면 return을 하는 함수이다. 파라미터 1: 요청한 구조체의 array(여러개의 aiocb값) 2: array element의 개수 3: timeout값 마냥 기다리는 것이 아니고 timeout 완료되면 return을 하겠다.
aio_cancel : I/O를 중단시키고 싶다. cancel 시키고 싶다. 1: target fildes 2: control block을 지정. NULL이면 모든 요청 취소해 달라. fildes만 지정하면 된다. AIO_CANCELED이면 성공. AIO_ALLDONE이면 이미 완료가 되었다.
Thraed 간에 동기화 시키는 mechanism에 대해서 알아보고 OS에서 제공하는 system call 함수를 살펴보면서 동기화 문제와 해결방안, 그에 대한 idea에 대해서 얘기하겠다. Multi thread를 활용할 때 프로그램 성능은 향상되지만 thread들 간에 충돌문제가 발생할 수 있으니 thread간에 충돌이 생기지 않도록 관리하는 방법도 알아보겠다.
Mutex
: Mutex라고 하는 것은 mutual exclusion의 약자이다. mutual exclusion은 번역을 하면 상호배제. 즉, 서로 배제를 하겠다는 뜻이다. 어떤 이유 때문에 이런 조건이 필요하냐 하면 thread간에 발생할 수 있는 충돌문제 때문이다.
예를 들어 프로그램에서 어떤 Resource가 있는데 (ex. 전역변수) 어느 시점에 A라는 thread와 B라는 thread가 이 변수에 서로 다른 값을 입력을 할려고 하는 것이다. 즉, 동시에 update 할려고 하는 것이다. 이 때, 충돌문제가 발생한다. 문제를 막기 위해서는 solution을 구현하기가 어려운데, 생각으로는 동시에 access하는 것을 막으면 될 것이라는 생각이 든다. Thread가 한번에 한 thread씩 공유변수를 access하게끔, 동시에 access 하는 부분을 OS level에서 막을 수 있는 mechanism을 제공하자. 먼저 요청한 thread가 resource를 access 했다면 다른 thread는 기다려야 한다.
Mutual exclusion을 만족하는 영역을 critical section이라고 한다. Thread 하나가 critical section에 들어오면 다른 Thread는 못들어오는 것이다. 이 영역에는 하나의 Thread만 들어올 수 있다. Mutex 실행하는 변수를 사용해서 기본적인 thread간의 동기화 mechanism을 사용할 수 있는 수단으로 사용할 수 있다. 그걸 통해서 공유 data를 보호하고 동시에 access하는 것을 막을 수 있다. 즉, 순서대로 data를 access하면 충돌문제를 피할 수 있다.
그래서 Mutex variable이라는 객체가 lock의 개념으로 작동한다. 공유 변수에 access하고싶으면 lock을 먼저 호출하고 양쪽 thread가 lock을 호출하면 먼저 호출한 thread에게 lock을 풀어주고 그 thread가 열쇠를 갖고 임계영역에 들어오고 들어오지 못한것은 lock에 대한 waiting queue에 들어가서 대기하게 된다. (lock에 대한 waiting queue가 또 따로 있다) lock을 걸고 해제하는 작동은 Mutex variable을 통해서 할 수 있다. Mutex variable은 Mutex lock mechanism에 해당하는 system call함수를 제공해 주는 것이다.
오직 하나의 thread만 Mutex variable을 소유할 수 있다(lock을 얻을 수 있다) lock을 가진 thread가 임계 영역에 들어가서 공유데이터를 access하고 다 사용하고 나면 반드시 자기가 가지고 있는 lock권한을 해제를 해야 한다. lock을 시스템에 반환하고 넘어가야 OS는 lock을 받아서 다음차례의 thread가 들어와서 data를 access할 수 있는 것이다.
OS는 프로그래머가 lock을 요청하고 lock을 해제할 수 있는 서비스만 mechanism으로 제공하는 것이고 개발자가 thread를 잘 분석해서 충돌영역이 있는 부분을 lock, unlock을 잘 사용해야 한다. Lock을 요청한 thread가 여러개가 있을 때 나머지 thread들이 waiting queeue에 대기하고 있는데 대기중인 thread가 계속 대기하면 문제가 생기고 critical section의 요구사항에도 맞지가 않는다. Mutex라고 하는 기본 mechanism을 이용해서 "race" condition(충돌 문제로 생기는 문제, 서로 업데이트 할려고 하는 상황)을 막아야 한다.
Race condition은 여러 thread가 동시에 공유 데이터를 access할려고 해서 발생하는 문제이다. Race condition을 실제 상황에 적용해보자. 예를 들어, 은행에 계좌가 있는데 한 은행 계좌에 여러 군데서 그 계좌에 돈을 집어넣는 서로 다른 thread에서 집어넣을려고 하는 상황이 발생하는 것이다. 계좌 소유자가 ATM기에 가서 200달러를 집어넣을려고 한다. 그런데 그것과 거의 동시에 다른 은행 쪽 지점에서 뭔가 수익이 생겨서 어떤 식으로든 이 계좌로 200달러를 입금을 할려고 요구하면 transaction이 같은 계좌에 동시에 발생한 것이다. 두 thread는 계좌의 잔액을 동시에 update하려고 하는 것이다. 1번 thread는 200달러를 더할려고 하는 것이고 2번 thread도 계좌에 업데이트 할려고 하는 것이다. 정상적으로 수행이 되었다면 task가 끝나고 나서 잔액을 1400달러가 되어야 하는데 동시에 제어없이 access하게 되면 1400달러가 아닌 결과가 발생할 수도 있게 된다. 현재 잔액 정보를 읽어서 update한 값에 계산을 수행하고 다시 write하는 과정을 거쳐야 한다.
이 문제를 막기 위해 동시에 접근하는 부분을 critical section으로 막아서 access하는 것을 먼저 요청한 thread에게 권한을 주는 것으로. update 다 끝내고 나오면 가지고 있었던 lock을 release하고 OS가 반환된 것을 다음 thread에게. 한
thread가 끝난 다음에 다음 thread 실행하도록 해서 consistent한 결과를 내게 한다.
pthread_mutex_t mutex를 사용을 하려면 mutex에 대한 lock을 요청하기 전에 먼저 mutex type의 변수를 선언하고 초기화를 진행해야 한다. 보통은 mutex 타입이 구조체 형태로 구현이 된다. mutex lock을 표현할 수 있는 변수가 되는 것이다.
Initialization of static variable (초기화 하는 방식이 2가지가 제공이 된다) static으로 변수를 선언했을 경우에 선언과 동시에 초기화 할 수 있는 default 방식으로 초기화 할 수 있는 pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; 방법. 이 방법은 주로 static 변수로 선언된 mutex type의 변수를 선언과 동시에 초기화 하기 위한 방법이다.
Initialization of dynamically allocated variable mutex type의 변수를 dynamic allocated로 선언했을 경우 초기화 함수를 호출하는 방식이 있다. pthread_mutex_init이라는 함수를 호출해서 mutex 변수를 초기화하는 방식도 있다. 첫번째 파라미터가 바로 초기화 할려고 하는 mutex pointer변수의 포인터를 넘겨주고 두번째 파라미터는 mutex변수도 속성을 가지고 있고 원하는 속성으로 하고 싶을 경우 여기에 넘겨준다. 속성을 줄 수 있다는 차이점이 있다.
Initialization of a mutex that has been already initialized 이미 초기화된 mutex 변수를 다시 초기화 한다. 예를 들어 init 함수를 호출했었는데 다시 한번 호출을 한다던지. 이런 결과에 대해서는 따로 define 되지 않아서 어떤 일이 생길지 모른다.
Destroy
#include <pthread.h> int pthread_mutex_destroy(phread_mutex_t *mutex);
초기화하고 난 다음에 lock을 하고 lock을 해제할 수 있는데 이러한 작업이 끝나고 mutex 변수를 다 사용하고 난 다음에는 destroy함수를 호출해서 관련 mutex 변수에 할당됐던 resource를 해제하는 작업을 OS에게 요청해서 resource를 효율적으로 활용해야 한다.
Return values 성공적으로 destroy되면 0이 return이 되고, 에러가 나면 error code값이 return이 된다.
Undefined behaviors (destory할 때도 조심해야 한다) - destroy 된 다음에 이 mutex 변수를 참조하는 thread가 있었는 경우. destroy 된 mutex 변수를 reference 할려고 하면 당연히 안된다. (확인하고 destroy 해라) - 어떤 thread가 destroy를 호출했는데 다른 thread가 mutex lock을 가지고 있는 경우. Mutex 변수를 사용하는 thread가 있는 경우.
Locking / unlocking
#include <pthread.h> int pthread_mutex_lock(pthread_mutex_t *mutex); int pthread_mutex_trylock(pthread_mutex_t *mutex); int pthread_mutex_unlock(pthread_mutex_t *mutex);
pthread_mutex_lock() - OS에게 lock을 요청하는 함수. 함수를 호출하기 전에 이 함수를 호출해서 변수를 넘겨준다. 예를 들어서 pthread_mutex_lock(&m); 을 호출할려면 m은 이미 초기화가 되어있다고 가정하고 호출한다. 그러면 모든 thread들은 함수를 호출하기 전에 mutex_lock을 호출하게 될것이고 여러 개의 thread가 동시에 lock을 호출하게 되면 lock한 함수를 block 시킨다. mutex가 available할 때까지. 성공적인 경우(lock을 얻은 경우)에만 return을 한다. lock을 놓으면(unlock이 되면) block에 있는것이 실행.
pthread_mutex_trylock() -> nonblocking 버전으로 호출해보는 함수. - Always returns immediately : lock을 얻을 수 있는 체크해 본다. lock을 얻으면 ok이고 그렇지 않아도 return한다. 호출했을때 성공하면 0, lock을 얻지 못했을 경우(이미 할당이 된경우) return이 된다. lock을 얻을때까지 trylock쓰면 된다. lock을 얻지 못하면 다른 task 수행하겠다 이런 경우 사용할 수 있다.
At-Most-Once excution의 semantic을 알아야 한다. At-Most-Once의 의미는 기껏해야 한번 실행하는 함수라는 의미이다. 예를 들어, func( )라는 함수가 있는데 한번만 실행해야 하는 함수이다. (아까 얘기한 초기화 함수같은) 개발자가 사람이다 보니 한번만 실행해야 되는 함수를 다중 스레드로 짜다 보니 또 호출하는 실수를 할 수가 있다. 그런 상황 하에서도 실제 실행되는건 젤 처음 한번만 실행되게 하기 위해서 pthread_once라는 함수를 사용한다.
pthread_once() 가 at most once를 보장해주는 함수이다. 이 함수를 사용하려면 변수를 먼저 초기화하고 어떤 변수에 대해서 초기화하고 첫번째 파라미터로 넘기고 두번째 파라미터는 at most once로 실행해야 하는 함수를 넘겨준다. 여러 스레드에 의해 호출된다 하더라도 여기 지정하면 한번만 실행된다. 이 함수를 실행하기 위해서는 pthread_once_t 타입을 초기화해서 사용해야 한다. mutex 변수와 다르게 static하게 초기화 하는 방법만 제공이 된다. 근데 두번째 파라미터의 타입을 보면 파라미터가 없고 void 리턴타입의 함수를 실행을 시킬 수 있는 제약상황이 존재한다. 결국 mutex init함수는 pthread_once로 호출할 수가 없다(parameter가 있기 때문에) 또다른 alternative한 방법을 사용해야 한다.
printinitonce.c
#include<pthread.h>#include<stdio.h>staticpthread_once_t initonce = PTHREAD_ONCE_INIT;
int var;
staticvoidinitialization(void){
var = 1;
printf("The variable was initialized to %d\n",var);
}
intprintinitonce(void)/* call initialization at most once */returnpthread_once(&initonce, initialization);
}
initialization함수를 한번만 실행하고 싶어서 printinitonce를 호출하게 되면 pthread_once 함수를 통해서 initialization을 간접적으로 호출한다. 여러 함수가 동시에 printinitonce를 호출해도 initialization은 한번만 실행이 되고 그 다음 스레드에 의해서 호출되도 실행이 안되도록 보장이된다. 즉, at most once execution이 보장이 된다.
#include<stdio.h>intprintinitonce(void);
externint var;
intmain(void){
printinitonce();
printf("var is %d\n",var);
printinitonce();
printf("var is %d\n",var);
printinitonce();
printf("var is %d\n",var);
return0;
}
printinitonce를 실행이 var=1로 초기화 되어서 출력이 되고 main 함수에 의해서 1이다 라고 표시가 되고 printinitonce를 또 호출해도 다시 실행이 되지는 않는다.(pthread_once 함수에 의해서)
parameter가 지금은 void로 와야만 되는데 parameter가 필요한 경우에는 어떻게 할까??
- Alternative example : printinitmutex 함수 사용한다. 초기값을 parameter로 넘겨준다.
printinitmutex.c
#include<pthread.h>#include<stdio.h>intprintinitmutex(int *var, int value){
staticint done = 0;
staticpthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
int error;
if (error = pthread_mutex_lock(&lock))
return error;
if (!done) {
*var = value;
printf("The variable was initialized to %d\n", value);
done = 1; // 끝냈다는 걸 보여준다.
}
returnpthread_mutex_unlock(&lock);
}
다시 printinitmutex를 호출해도 static으로 선언된 곳은 건너뛴다. done은 1로 이미 설정되어버려서 if문도 건너뛴다. if문 안에는 최초일때만 실행된다. 다시 실행이 되지 않는다. done 변수도 초기화가 한번만 되고 mutex변수도 lock이라는 변수가 또 초기화 되는것이 아니라 static변수라서 처음 한번만 초기화 되니까 조건이 만족하게 되는 것이다.
#include<stdio.h>intprintinitmutex(int *var, int value);
staticvoidprint_once_test(int *var){
int error;
error = printinitmutex(var,1);
if (error)
printf("Error initializing variable\n");
elseprintf("OK\n");
}
intmain(void){
int var;
print_once_test(&var);
print_once_test(&var);
print_once_test(&var);
return0;
}
static 변수의 초기화를 이용해서 한번만 실행되도록 구현을 한것이다.
At-Least-Once execution
: 적어도 한번 실행해야 한다. 한번 실행은 반드시 하고, 두 번 실행이 되어도 상관없다. 초기화를 반드시 해야 한다. At least Once 와 At most once의 교집합은 exactly once이다. 한번도 실행을 안해도 안되고 여러번 해도 안되고 정확히 한번만 해야 된다.
Conditino Variables : 또다른 동기화 mechanism
Mutex lock에 의한 동기화는 critical section을 구현하기 위한 동기화 mechanism으로 lock()과 unlock()이 있었다. 여러 thread가 달려들더라도 한 thread만 진입할 수 있도록 동기화가 된 것이다. locking mechanism을 사용하다 보니 또다른 동기화 요구가 생겼다.
Condition Variable을 사용하는것은 critical section 안에서 또다른 동기화가 필요할 때 사용하게 된다. Condition Variable은 critical section 내에서 사용하는 것이다.
Motivation
- 어떤 thread가 Mutex Lock을 써서 동기화를 써서 critical section에 들어왔다. 들어와서 어떤 task를 처리하려고 봤더니 지금 이 task는 특정조건을 만족해야만 수행할 수 있는 task였던 것이다. 그런데 지금 이 thread가 critical section안에 들어와서 봤더니 다음 task를 수행할 조건이 만족하지 않고 있는 상태였던 것이다. 그럼 thread는 다음 task를 수행하지 못하고 기다려야 하는 상황이 생기는 것이다.
예를 들어 조건중에 x라는 변수와 y라는 변수가 있는데 critical section에 들어온 thread가 다음에 수행할 task는 일단 x와 y가 같다라는 조건 하에서 수행해야 하는 task였던 것이다. 그런데 봤더니 x와 y가 값이 다른 것이다. 그러면 이 thread는 x와 y가 같아질때까지 기다려야 하는데 while(x!=y)를 써서 기다리면 의미없는 기다림(Busy waiting)이 된다. 근데 busy waiting은 굉장히 비효율적이다. 그냥 lock을 놓고 나갈 수는 없다. 그러면 별도의 또다른 wait를 할 수 있는 mechanism이 필요하다.
- Non-busy waiting solution : 여기서 나오게 된 것이 condition variable 즉, 조건 변수라는 mechanism이 필요하다. 일단 lock을 얻고 access 하자. x==y인 경우 unlock하고 loop를 빠져나가면 되는데, 만약 false인 경우, thread를 suspend 시키고 unlock한다. (thread를 suspend시키는 또다른 함수) 그냥 suspend 시키면 안되고 무조건 mutex를 unlock하고 suspend를 해야 한다. critical section안에서 대기해야 된다. 대기를 하기 위해서 condition variable이라 하는것에 대해서 wait를 한다. condition variable에 대해서도 waiting queue가 존재한다. suspend되는 것은 어딘가 waiting queue에 들어가서 대기하게 되는 것이다. Critical section은 잠시동안 비어있는 상태가 되는 것이다. 그러면 다른 thread가 들어올 수 있는 기회를 줘야된다. 그러니까 반드시 suspend시킬 때 내가 가진 mutex를 unlock시켜줘야 한다. 이제 다른 thread가 들어와서 waiting하고 있는 x와 y를 같게 해주는 thread가 존재하는 것이다. 아까 x와 y값이 달랐기 때문에 대기하고 있었던 thread는 깨워진다. 어떤 제어상황안에서 condition variable에 의해서 제어가 되는 것이다. 혹시나 x값이 변경이 되었으니까 check를 하도록 기다릴 수 있는 thread를 깨워줄 수 있는 thread를 호출 한다. 같은 condition variable에 대해서 signal이라는 함수를 호출하면 이 signal에 의해서 깨우게 된다. 깨워진 thread를 다시 검사를 하고 여전히 다르면 또 wait로 호출하고 대기한다. 이렇게 서로 다른 thread가 하나의 critical section인 것이다. 한 thread는 조건 검사를 하고 다른 critical section에 들어와서 깨워주고. 이러면 조건에 맞으면 조건 검사를 하고 조건이 맞으면 다음 section을 진행. 조건을 검사하고 깨워주고 wait하는 thread를 위해서 condition variable이 필요하다.
- pthread_cond_wait : condition variable이랑 mutex를 parameter로 받고 thread를 suspend시키고 mutex를 unlock하는 함수. mutexx를 가진 thread에 의해서 호출되어야 한다.
- pthread_cond_signal : condition variable을 parameter로 가지고 적어도 하나의 thread를 깨운다. condition variable에서 대기중인 thread를 mutex의 waiting queue로 이동시키는 역할을 한다. 그래서 wait에서 깨어나면 먼저 mutex를 다시 얻고 실행을 해야 한다.
-> 이걸 호출하게 되면 첫번째 파라미터에 대해서 호출한 thread가 suspend 되면서, 즉 첫번째 파라미터의 waiting queue로 들어가게 된다. 내가 잠들고 난 다음에 다른 thread가 들어올 기회를 줘야하기 때문에 두번째 파라미터를 unblock 시킨다.
timedwait도 parameter는 똑같은데 세번째 파라미터가 abstime이 들어가게 된다. 누군가가 나를 깨워주든지(signal) 아님 abstime시간이 만료되면 return이 된다.
Signal이 도착했을 경우에는 2가지 가능성이 있다. 첫번째는 signal handler가 불릴것이고 return 하고 난다음에 wait함수가 기다리는 상태가 계속되는 경우, 또는 sinal handler로 부터 return 한 다음에 wait도 0을 return해서 깨어나는 경우도 있다. (wait함수와 signal delivery 같이 사용하는 경우)
Signaling on condition variables : condition variable에 대해서 대기중인 thread를 깨워주는 함수
#include <pthread.h> int pthread_cond_broadcast(pthread_cond_t *cond); int pthread_cond_signal(pthread_cond_t *cond);
parameter는 깨울 condition variable을 유일한 파라미터로 취함.
일반적인 함수가 cond_signal함수이고 이 함수를 호출하게 되면 파라미터로 넘긴 condition variable의 waiting queue에 대기중인 thread들 중에서 적어도 하나의 thread를 깨운다. 깨운다는 얘기는 condition varaible의 waiting queue에서 꺼내서 unblock했던 mutex에 waiting queue로 다시 넣는다. condition variable에서 깨어난 thread는 일단 자기가 놨던 mutex를 먼저 다시 lock을 가진 상태에서 wait함수를 리턴할 수 있게된다.
broadcast라는 함수는 condition variable에 대기하는 모든 thread를 깨우겠다. 무조건 모든 waiting 하는 thread를 깨우겠다.
Signal handling and thread : 다중thread 프로그램에서 signal handling하기
Signal delivery in threads
- 멀티 thread에서 thread handling하는 것을 고려해보는 것이다. Thread가 여러개인것이 실행중인데 그 thread에게 signal이 도착했을 경우 어떤 일이 벌어질 것인가. Process안의 모든 thread들은 process의 signal handler들을 공유한다. 각각의 thread들은 thread들마다 signal mask를 가질 수 있다. Signal mask를 얘기할 때 사전조건이 이 process는 signle threaded process다 라고 가정하고 그 process의 signal maks를 sigprocmask라는 함수를 통해서 제어를 할 수 있었다. 만약에 다중 thread기반의 process에서 signal mask를 제어하고 싶을때는 sigprocmask말고 다른 POSIX libraray에서 제공하는 thread별로 mask를 조절할 수 있는 함수가 있다. Thread별 signal mask를 제어할 수 있는 함수는 뒤에서 설명하겠다.
다중thraed기반의 process에게 signal이 왔을 때 이 signal은 어떤 thread가 받을 것인가 하는 것이 애매하게 된다. 그래서 그건 delivery mechanism에 따라서 3가지 타입의 signal이 전달되는 방식을 생각해볼 수 있다.
1. asynchronous : 그 signal을 unblock한(signalmask로 막지 않은) thread에게 signal이 전달되는 경우. 이 signal을 받고자 하는 thread가 여러개가 있다면 여러개의 thread에게 signal이 전달될 수 있다.
2. Synchronous : 여러 thread들 중에서 그 signal을 발생시킨 thread에게 delivery한다.
3. Directed : target signal을 지정했을때 thread를 target thread 목적 thread가 이미 지정되어있다.
Directing a signal
#include <signal.h> #include <pthread.h> int pthread_kill(pthread_t thread,int sig);
내가 이 signal을 전달시킬 thread를 지정한다. 첫번째 파라미터가 thread id가 된다. 두번째 파라미터로 몇번 signal을 보낼것인지.
how parameter : SET_MASK -> 기존의 signal mask에 등록되어있었던 signal들을 무시하고 새로 2번째 파라미터로 설정한 sigset으로 설정, SIG_BLOCK -> 현재 signal을 그대로 두고 2번째 파라미터 sigset 추가, SIG_UNBLOCK -> 현재 signalmask에 있는 것중, 2번쨰 파라미터 sigset을 빼는 것.
oset은 변경되기전 signal mask 저장.
Dedicating threads for signal handling
signal handling을 전담하는 thread를 지정하는 방식 -> signal이 오면 전담 thread 지정하는 방식으로. 이 예제를 통해서 다중 thread가 존재하는 process에서 signal handling 필요 있을때 이렇게 처리해라.
signal handling을 처리하는 특정 thread를 지정을 해라. 어떤 식으로 만들거냐. 일단 main thread가 일단 모든 signal을 block을 시키고 dedicated할 thread 만들고 전담 thread가 signal이 도착하기 기다리는 sigwait()를 전담 thread가 호출하고 sigwait함수의 target signal을 sigset안에 기다리는 것을 넣어서 호출하면 sigwait는 와서 block이 되면 sigwait가 return이 되고 pending list에서 삭제하고 return이 된다. 모든 thread block해서 다 wait되고 전담 thread가 sigwait 밑에 작업을 수행하면 되는 것이다. 이 전담 thread는 target signal이 와서 pending이 되면 수행할 task.
pthread_sigmask를 통해 unblock하는 방법을 사용할수도 있을거다.
#include<errno.h>#include<pthread.h>#include<signal.h>#include<stdio.h>#include"doneflag.h"#include"globalerror.h"staticint signalnum = 0;
/* ARGSUSED */staticvoid *signalthread(void *arg){ /* dedicated to handling signalnum *///signalhandling 전담 thread가 수행할 함수int error;
sigset_t intmask;
structsched_paramparam;int policy;
int sig;
if (error = pthread_getschedparam(pthread_self(), &policy, ¶m)) {
seterror(error);
returnNULL;
}
fprintf(stderr, "Signal thread entered with policy %d and priority %d\n",
policy, param.sched_priority);
if ((sigemptyset(&intmask) == -1) ||
(sigaddset(&intmask, signalnum) == -1) ||
(sigwait(&intmask, &sig) == -1))
seterror(errno);
elseseterror(setdone());
returnNULL;
}
intsignalthreadinit(int signo){ //signo -> target signalint error;
pthread_attr_t highprio;
structsched_paramparam;int policy;
sigset_t set;
pthread_t sighandid;
signalnum = signo; //target signal은 전역변수로 저장 /* block the signal */if ((sigemptyset(&set) == -1) || (sigaddset(&set, signalnum) == -1) ||
(sigprocmask(SIG_BLOCK, &set, NULL) == -1))
return errno;
if ( (error = pthread_attr_init(&highprio)) || /* with higher priority */
(error = pthread_attr_getschedparam(&highprio, ¶m)) ||
(error = pthread_attr_getschedpolicy(&highprio, &policy)) )
return error;
if (param.sched_priority < sched_get_priority_max(policy)) {
param.sched_priority++;
if (error = pthread_attr_setschedparam(&highprio, ¶m))
return error;
} elsefprintf(stderr, "Warning, cannot increase priority of signal thread.\n");
if (error = pthread_create(&sighandid, &highprio, signalthread, NULL))
return error;
return0;
}
pending되면 sigwait리턴되고 아래쪽 실행하게 된다 -> setdone()함수 수행. 그 프로세스에게 작업을 모두 끝내라는 작업이다. 이 예제에서 보고자 하는 것은 다중 thread기반의 프로세스에서 signal왔을때 전담 thread를 만들어서 그 thread가 target signal을 받아들이도록 하면 되겠다. 전담 thread는 sigwait함수 호출해서 target signal올때까지 기다림. targetsignal오면 pending 되고 setdone() 수행. 별도의 sinal handler함수가 사용되지 않음. target thread가 전달되지 않는다.
Readers and writers : 조금 더 세분화해서 lock을 걸 수 있는 reader and writers lock.
이것도 동기화 mechanism 중 하나
Reader-writer problem
- mutex lock의 목적은 특정 code영역중 여러 thread가 동시에 접근하려고 하면 문제가 되기 때문에 한번에 하나의 thread만 access하도록 하기 위해서 사용했던 것. lock을 얻은 thread만 critical section으로 진입할 수 있게 된다.
- shared resource를 access 하는 것을 세부적으로 살펴보자. thread가 resource를 access한다 하는 것은 사실 2가지 중 하나의 operation을 진행한다는 것이다. 하나는 read. 이 resource로부터 뭔가를 읽는다. 다른 하나는 write. 이 resource에 어떤 값을 새로 쓰겠다. write operation인 경우에는 여러 thread가 접근하면 당연히 충돌 문제가 생기니까 이거는 exclusive하게 하나의 thread만 할 수 있게 한다.
그런데 read operation인 경우 달라진다. 만약에 여러 thread가 동시에 읽어가겠다라고 하면 사실 크게 문제가 될 것이 없다. 그래서 이 경우에는 critical section으로 막을 필요가 없다. (오히려 막는게 performance가 떨어질 수도 있다) operation에 따라서 lock을 주는 그런 mechanism을 reader-write mechanism이라고 한다. 조금 더 mutex lock보다 flexible하게 lock을 제공하는 mechanism. read 용으로 lock을 요청했을 경우 여러 thread에게 lock을 줄 수있는 mechanism. 요청하는 lock이 여러개가 있다보니 섞여있는 경우 누구에게 먼저 lock을 줄 것인가 하는 strategy가 생길 수 있다. -> Strong reader synchronization이나 strong writer synchronization이 생긴다. 만약에 섞여있으면 writer operation thread가 끼어드는 순간 thread들 중에 하나의 thread들만 진행할 수 있다.(Mutex Lock과 같음) 모든 thread들이 read요청했으면 mechanism이 모든 thread에게 권한을 준다. 그럴때 read용 lock을 먼저 할것이냐 write용 lock을 먼저할것이냐에따라 동기화 진행될 것이다.
reader synchronization은 reader에게 우선권을 주겠다는 소리이다. Reader에게 먼저 읽어라 라는 lock을 준다. Reader thread가 다 읽고 난 다음에 writer thread에게 write해라 라는 뜻. writer synchronization은 그 반대. 구현에 따라서 어떤 방식일지는 달라지는 것이다.
Initialization of read-write locks
#include <pthread.h> int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr);
반드시 초기화를 하고 난 다음에 사용해야 한다는 것은 동일하다.
pthread_rwlock_t가 read write lock 타입의 변수가 되는 것이다. 그 변수를 선언하고 rwlock 타입의 변수도 항상 초기화를 하고 사용해야 한다. 초기화 함수를 통해서 초기화 할 수 있다. 다른 pthread 함수와 동일하다. 또 초기화를 하게 되면 결과가 undefined되게 되어있다. read write lock에도 한번만 초기화 하라는 내용이 되어있는 것이다.
Destroying read-write locks
#include <pthread.h> int pthread_rwlock_destory(pthread_rwlock_t *rwlock);
다 사용한 read/write 객체는 destroy함수를 호출해서 시스템에 사용했던 resource를 반환한다. 이것도 주의해서 사용해야 한다. read /write lock을 잘못 destroy한 경우 결과는 undefined.
Locking / unlocking
#include <ptread.h> int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); int pthread_rwlock_wlock(pthread_rwlock_t *rwlock); int pthread_rwlock_trywlock(pthread_rwlock_t *rwlock); int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
lock을 걸때 read 용으로 걸것인지, write용으로 걸것이지가 존재하고 lock을 요청하는 함수도 blocking 모드 혹은 unblocking 모드로 걸것인지 다양하게 존재한다. read/write lock을 얻지 못한 thread는 waiting queue에 들어가서 대기하게 된다. 처음 2개 rdlock, tryrdlock은 read를 요청하는 함수이다. wrlock은 write 용 lock을 요청하는 함수이다. unlock함수는 하나 있다.
read/write lock도 dead lock이 발생하지 않게 조심해야 한다. lock을 가지고 있는데 또 lock을 요청하면 deadlock에 빠지게 된다.
read write lcok을 사용하는 예제
: list를 구현한 예제. 일반적 list가 아니라 key를 이용해서 list정보에 access 할려는 원래의 값만 참조를 할 수 있게끔. list의 값에 access하는 함수를 구현한 예제이다. 다중 thread 공유변수의 값을 읽어가는 함수. read용 operation 또는 write용 operation을 사용해서 다중 thread가 access해도 안전한 list를 구현한 예제가 될 것이다.
#include<errno.h>#include<pthread.h>staticpthread_rwlock_t listlock;
staticint lockiniterror = 0;
staticpthread_once_t lockisinitialized = PTHREAD_ONCE_INIT;
staticvoidilock(void){
lockiniterror = pthread_rwlock_init(&listlock, NULL);
}
intinitialize_r(void){ /* must be called at least once before using list */if (pthread_once(&lockisinitialized, ilock))
lockiniterror = EINVAL;
return lockiniterror;
}
intaccessdata_r(void){ /* get a nonnegative key if successful */int error;
int errorkey = 0;
int key;
if (error = pthread_rwlock_wrlock(&listlock)) { /* no write lock, give up */
errno = error;
return-1;
}
key = accessdata();
if (key == -1) {
errorkey = errno;
pthread_rwlock_unlock(&listlock);
errno = errorkey;
return-1;
}
if (error = pthread_rwlock_unlock(&listlock)) {
errno = error;
return-1;
}
return key;
}
intadddata_r(data_t data){ /* allocate a node on list to hold data */int error;
if (error = pthread_rwlock_wrlock(&listlock)) { /* no writer lock, give up */
errno = error;
return-1;
}
if (adddata(data) == -1) {
error = errno;
pthread_rwlock_unlock(&listlock);
errno = error;
return-1;
}
if (error = pthread_rwlock_unlock(&listlock)) {
errno = error;
return-1;
}
return0;
}
여러 thread가 getdata_r 호출하면 여러 thread가 동시에 read 호출할 수 있게 한다. 모든 thread가 getdata_r만 호출했다면 동시에 getdata 호출해서 access 할 수 있게 된다. 선택적으로 read, write lock을 할 수 있게 된다. read, write를 수행하는거냐에 따라서 구현한 것이다.
initialize_r()은 read,write를 초기화 시키는 것. mutex lock으로도 구현을 했던 것이 있었는데 read lock과 비교를 한다면 read write lock은 overhead가 있을 수 있다. read용이냐 write용 lock이냐에 따라 부가적인 처리가 필요해 overhead가 필요하다.
sterror()은 thread safe하지 않은 함수였고 concurrent 하게 호출하면 문제가 된다. 이 문제를 막으려면 mutex lock으로 보호할 수 있고 perror()도 thread safe 하지 않은데 여러 thread가 호출할 수 있는 함수로 만들 수 있다. thread safe하지 않고 async-signal safe하지도 않다. async signal safe하게 만들기 위해서 signal을 잠시 block 시킬 것이다. signal이 오더라도 pending 하기 위해서 sigprocmask를 사용한다.
mutex 변수 static하게 선언. sterror_r 함수에서는 결과적으로 original 함수 sterror를 호출하는 게 목적인데 호출하는 thread가 여러개가 있더라도 한번에 하나만 할 수 있도록 pthread_mutex_lock을 해서 호출할 수 있도록 했고 나가기 전에 unlock을 했고 이 사이를 thread safe하게 만든것이다. sigfillset에 모든 maskblcok을 해서 sigprocmask를 호출했다. 현재 process에 signalmask안에 모든 thread를 채운것이다.
perror_r 도 똑같은 idea로 sigprocmask를 써서 asyncsignal safe함수로 만든것이다.
Deadlocks
: 동기화 관련 mechanism을 잘 사용하지 못하면 deadlock에 빠질 수 있다. -> 개발자에게 책임을 넘김.
하드디스크 상의 program이 memory에 load되어서 process가 실행이 된다. process내에 thread가 실행이 되어서 실행되고 thread는 context 정보를 가지고 있다.
Thread가 여러 개인 process의 장점은 무엇일까? 다중 스레드가 좋은 점이 있다. 만약 task 하나를 수행하는 것이 하나의 함수이고 함수를 여러개 정의해 놓았는데 a()와 b()가 독립적인 함수다. 두 함수는 동시에 진행해도 상관이 없다고 하자. a()를 먼저 호출하고 b()호출할 수도 있지만 concurrent하게 실행할 수 있으면 cpu가 하나인 경우에도 process를 concurrent하게 실행할 수 있었다. (예를들어 fork()함수를 사용해서 하면 된다.)
a와 b라는 프로그램을 따로 만들어서 각각 실행시키면 두 프로세스가 concurrent하게 실행이 된다. 빠르게 switch해가면서 조금씩 실행해가면서 동시에 해가는 것처럼 보이는게 thread에도 적용이 된다. thread도 동시에 실행되면 서로 switch해가면서 동시에 진행된다. 다중 스레드는 concurrent한 task를 진행하기 위해서 사용한다.
thread 개념과 특징
thread는 실행 단위를 나타낸다(실행 흐름) 실행 흐름이라는 것은 thread가 가진 중요한 정보 중 program counter라는 것이 있는데, thread마다 가지고 있는데 실행해야 되는 instructor에 다음 실행해야할 정보를 가지고 있는것이다. 하나의 실행흐름이 thread 객체이다. tread마다 독립적인 실행 단위를 가지고 있는 것이다. 각각의 tread는 cpu state register같은 독립적 정보를 가지고 있다. thread들 마다 따로 사용하는 메모리 공간이 있지만 thread들이 공유하는 메모리 공간이 존재한다. code 부분, 전역변수 부분, heap공간 들을 공유를 한다. (장,단점 존재)
다중 스레드라 하는 것은 다중 프로세스와 비슷한 성질이다. 그런데 여러 프로세스들은 프로세스들끼리는 memory를 공유하진 않는다. 프로세스간에 데이터 주고받는 것을 하고 싶으면 OS 도움 받아야함. 다중 스레드는 공유하는 메모리를 이용해서 thread들끼리 쉽게 데이터 주고받는 communication을 할 수 있다.
스레드들은 독립적인 실행 단위. 사람눈으로 보기에는 동시에 실행되는것처럼 보인다. concurrent하게.
다중 스레드 : 여러 독립적 task를 concurrent하게 실행. thread들간의 동기화 문제를 고려해야 한다.
1. 다중 스레드를 사용하게 되면 asynchronous events를 효율적으로 사용할 수 있다. (언제 발생할지 모르는 event)
2. parallel performance를 사용할 수 있다.
Multitasking : 다중 프로세스, 다중 스레드로 가능하다.
single processor 에서는 time-division multiplexing. 실행시간 나눠서 task실행.
multi processor 는 실제로 동시에 실행되는 것이다.
Processes vs. threads
process들은 independent 하다. process가 사용하는 메모리 공간은 기존 process와 separate하게 os가 할당을 해준다. 한 프로세스 내에 있는 여러 개의 thread는 각자 사용하는 메모리 공간이 존재하고 공유하는 메모리도 존재한다. 서로 dependent한 부분이 있다. process는 thread에 비해 관리해야 하는 state information이 많다. context switch할 때 기존 상태를 저장하고 이전상태를 load해서 해야 하기 때문에 이 속도가 state양에 의해서 결정된다. 프로세스들은 separate한 address space를 가진다. process는 os의 도움을 받아야 process끼리 communication할 수 있다. (thread는 os도움없이 할 수 있다. 메모리를 공유하기 때문에)
다중 프로세스보다는 다중 스레드로 하는 것이 overhead가 적게 든다. thread간의 동기화 문제를 고려해야 한다. process는 커널이 스케쥴링 할 수 있는 heaviest unit이다. 프로세스는 os가 할당해주는 자체적인 resource를 가지고 있다. process는 기본적으로 address space와 file resoure를 공유하지 않는다. (예외적인 경우로 file handle을 상속받거나 공유 segment를 share할 때 공유할 수 있는 메모리를 할당받을 수 있다. 이런 부분들은 default가 아니고 추가적인 작업이 있는 경우 할 수 있다. ) 프로세스들은 preemptive하게 multitasking된다. 어떤 프로세스가 cpu를 가지고 실행중이였다가 더 높은 우선순위가 ready queue에 들어오면 os는 preemptively한 것이면 우선순위 높은 process가 context switch가 일어나 선점될 수 있다.(언제든 실행중이였다가 scheduling 될 수 있다)
반면에 thread인 경우. process들끼리 공유하는 information이 있을 수 있다. (code, global, static, heap) thread들 간의 context switch의 overhead가 더 적다 -> switch시간이 더 빠르다. thread는 kernel이 스케쥴링하는 lightest한 unit이다. 한 프로세스 안에서 다중 스레드가 존재할 수 있다. Thread도 preemptive하게 해서 concurrent하게 진행할 수 있다. thread는 그 자체로 resource를 소유하지는 않는다. thread마다 독립적으로 소유하는 resource도 있다.(stack, a copy of the registers including the program counter, thread-local storage)
cf> thread는 kernel thread와 user level thread로 나누어볼 수 있는데 리눅스에서는 지금 구분하지 않는다.
User space
: 사용자 application이 사용하는 메모리 공간. OS는 보통 kernel space와 user space로 나누어서 관리를 한다. kernel space는 kernel이 실행되는데 사용하는 공간, device driver에서 사용하는 공간이 있다. 대부분의 os에서 kernel memory는 disk에서 swapped out(교환)되지 않는다.
프로그램이 하드디스크에 있으면 메모리에 로드한다. 가상메모리는 프로세스 실행할때 전체를 메모리에 로드하는게 아니라 memory가 하드디스크에 비해 작기 때문에 다 로드를 하는게 아니라 필요한 부분만 로드하고 필요없는 부분은 다시 하드디스크로 나가기도 한다. 이렇게 왔다갔다 하는것을 swapping한다라고 한다. 메모리가 로드되는것을 swap in 디스크로 나가는것을 swap out이라 한다. 하드디스크에 I/O 동작이 일어나는건데 메모리에 access하는것보다 하드디스크에 I/O 일어나는게 스와핑 과정이 아무래도 느리다. 그래서 시스템 입장에서 swapping하는것이 적은게 오버헤드가 줄어서 좋다. 커널 메모리에서는 swap out이 되지 않는다. user space는 swap in, swap out 과정이 일어난다.
Pthreads
POSIX에 있는 thread library를 사용하면 된다. 줄여서 Pthread라고 얘기하고 POSIX 관련 시스템 콜 함수를 보면 함수의 이름도 다 pthread_ () 로 시작한다. 왜 pthread를 사용하느냐 -> 시간이 빠르다. 오버헤드가 더 적다.
Thread management
- pthread_create : thread 생성
- pthread_join : thread 완료될때까지 기다림.
signal mask를 제어하기 위해서 sigprocmask() 함수 사용. 다중 스레드 프로세스에서는 사용하지 마라. -> pthread 함수중에 signal mask 제어하는 것을 사용해라.
POSIX thread함수는 EINTR을 리턴하지는 않는다. -> interrupt되었을때 따로 재시작할 필요는 없다.
pthread_create 함수 : thread 만들어서 시작까지 해줌(thread에게 할당된 task를 실행해달라를 OS에 요청)
파라미터의 의미
1: pthread_t* thread : output parameter. 생성된 thread의 아이디가 반환된다.
2: pthread_attr_t* attr : process와 마찬가지로 다양한 thread의 특징을 나타내는 속성정보. default가 아닌 지정한 속성을 가진 thread를 만들겠다고 할 때 사용.(default로 만들고 싶으면 NULL로)
3: void*(*start_routine)(void*) : 함수 포인터. thread가 task하나를 담당한다. task는 함수로 정의한다. 새로 만들어진 thread가 기존 thread와 독립적으로 진행할 task를 설정한다. 아무 함수나 설정할 수 있는게 아니라 return 타입이 void*타입. 파라미터도 void* 타입.
4: void* restrict arg : 3번째와 연관. 3번째 함수 실행할 때 필요할 수 있는 파라미터를 여기에 지정. 3번째 함수가 실행될 때 넘겨줄 input parameter. void*타입임. 파라미터 필요없으면 NULL로 설정.
OS가 새로운 thread 생성하고 새로운 스레드로 정한 함수를 실행한다. 함수가 리턴이 되는 것은 스레드가 생성이 되고 지정된 함수의 동작을 실행하고 리턴하는게 아니고 0이 리턴이 되었으면 OS가 너의 요청을 성공적으로 받아들였다는 의미. 일단 요청을 성공적으로 받아들였다. task를 성공적으로 수행했다는 것은 함수를 수행했다해서 0을 리턴한게 아니고 지금 당장은 아니고 요청을 성공적으로 받아들였으니 OS가 thread 만들거다! 라는 것의 의미.
Detaching
#include <pthread.h> int pthread_detach(pthread_t thread);
thread는 detach <-> joinable.
detach한 스레드는 다른 스레드가 이 스레드의 종료를 기다릴 수 없는 스레드이다. detach상태 thread는 task완료해서 종료하면 스레드가 사용했었던 resource를 바로 release해버린다. detach스레드는 task를 완료한 다음에 resource를 바로 반환해 버린다.
detach가 아닌 joinable인 원래의 스레드는 바로 release하지 않는다. 왜냐하면 joinable한 스레드는 다른 스레드가 이 스레드를 기다릴 수 있다. 스레드도 다른 스레드가 나를 기다리고 있다면 종료값을 넘겨줄 수있다. 반환해야 되는 리소스 중에 포함되어있다. 다 release해버리면 나의 종료값을 나의 스레드에게 넘겨줄 수 없다. 보통 스레드를 바로 반환하는게 아니라 유지를 하고 있다. 유지된 스레드에게 종료값을 넘겨줄 수 있다. 그런데 detach된 스레드는 exit하면 바로 반환해버린다. 이 함수는 internal oprtion을 스레드가 사용했던 리소스들을 exit할때 바로 reclaim할 수 있도록 만드는 함수다. detach함수는 종료 상태정보를 report하지 않는다. resource를 바로 반환하기 때문에.
Joining
#include <pthread.h> int pthread_join(pthread_t thread, void **value_ptr);
Join 함수 : join 함수를 호출한 thread는 첫번째 파라미터로 지정한 id의 thread가 종료될 때까지 기다렸다가 target thread가 종료하면 리턴하고 기다리는 thread에게 리턴값 넘겨줄 수있고 결과값을 2번째 파라미터로 받는다. void**. 이중 포인터의 의미는 리턴값을 받기 위해서 void 포인터이기 때문에 integer를 받기 위해서 integer 포인터를 선언하고 가리키는 integer의 메모리는 기다리는 대상이 만들어서 리턴을 해줄거라고 생각하고 포인터 변수의 위치를 넘겨준다. 포인터의 위치니까 포인터의 포인터가 된다. 포인터값이 스레드에 의해서 변경될 수도 있으니까 포인터의 위치를 넘겨준다. (포인터도 변경될 수 있기 때문에) 두번째 파라미터는 output parameter라는 것. 데이터를 communication할 수 있는것. 데이터의 전달이 일어나는 것이다.
join 함수는 calling 함수를 suspend한다. nondetached thread의 리소스는 리소스를 release하지 않는다. 또는 전체 프로세스가 exit되기 전까지는 joinable한 리소스는 반환이 되지 않는다. 전체 프로세스가 exit되면 모든 리소스가 반환이 되는거기때문에 리소스가 반환이 된다.
첫번째 파라미터는 target thread의 아이디, 두번째 파라미터는 포인터의 위치. 리턴값 받을거 없으면 NULL로 설정하면 된다. 마지막 pthread_self()를 join함수의 파라미터로 넣으면 안된다. deadlock에 빠지게 되는 것이다. 이런 프로그램은 먹통이 되는것이다.
Example of creation/joining
pthread를 하나 생성해서 task 끝낼때까지 기다렸다가 자식이 끝나면 나도 끝나는 간단한 프로그램.
#include<pthread.h>#include<stdio.h>#include<stdlib.h>#include<string.h>void *processfdcancel(void *arg);
voidmonitorfdcancel(int fd[], int numfds){
int error;
int i;
pthread_t *tid;
if ((tid = (pthread_t *)calloc(numfds, sizeof(pthread_t))) == NULL) {
perror("Unable to allocate space for thread IDs");
return;
}
/* create a thread for each file descriptor */for (i = 0; i < numfds; i++)
if (error = pthread_create((tid + i), NULL, processfdcancel, (fd + i)))
fprintf(stderr, "Error creating thread %d: %s\n", i, strerror(error));
for (i = 0; i < numfds; i++)
if (error = pthread_join(*(tid + i), NULL))
fprintf(stderr, "Error joining thread %d: %s\n", i, strerror(error));
free(tid);
return;
}
monitorfd -> file descriptor 여러개를 monitoring하는 것을 다중 스레드로 구현한 것. 모니터링할 fd는 array로 주고 array의 갯수를 numfds로 준다. calloc 함수로 fd의 개수만큼 thread를 만들어서 thread에게 각 스레드가 fd하나씩을 담당해서 읽어서 처리하는 함수를 실행을 시킬 것이다. id를 저장하기 위한 용도로 개수만큼 할당해서 저장. tid라는 포인터로 tid 포인터는 array가 되는 것이다. for문에 들어가서 갯수만큼 thread를 만든다. 원래 thread는 i 번째 스레드 종료하길 기다리고 종료하면 pthread 리턴하고 그 다음 스레드가 종료되길 기다렸다가 끝날때까지 기다렸다가 다 끝나고나면 mainthread도 종료. 여러개의 fd를 모니터링하는 함수 구현.
Exiting : pthread_exit함수는 스레드 종료할 때 호출하는 함수고 나를 기다리는 함수에게 넘겨줄 값을 void*를 넘겨서 리턴을 할 수 있다. 그냥 exit()는 process를 종료시키는 함수. return을 호출하면 pthread_exit함수해서 종료한다.
Cancellation
#include <pthread.h> int pthread_cancel(pthread_t thread); int pthread_setcancelstate(int state, int *oldstate);
이들 함수는 하나의 쓰레드에서 실행중인 다른 쓰레드를 종료하기 위한 목적으로 사용된다. 취소 요청을 받은 다른 쓰레드가 어떻게 작동할런지는 설정에 따른다. 요청을 받은 쓰레드는 바로 종료하거나 취소 지점을 벗어난 후 종료할 수 있다.
pthread_cancel() 은 파라미터에 해당한는 쓰레드에게 종료 요청을 보낸다.
pthread_setcancelstate()는 호출한 쓰레드의 취소 상태를 변경하기 위해 사용된다. 상태는 (PTHREAD_CANCEL_ENABLE, PTHREAD_CANCEL_DISABLE) 중에 선택할 수 있다. 앞에꺼는 취소상태를 활성화 시키기 위해서, 두번째는 취소 상태를 비활성화 시키기 위해서 사용된다
Example>
실제 thread를 생성해서 parameter 전달하고 return 값 받는 예제.
1. 별도의 thread가 file copy하는 작업을 함수를 써서 별도의 thread로 수행. copy 되는 동안 기다리는 것. copy된 총 바이트 수를 기다리는 thread에게 전달하는 프로그램. copy 될 함수의 source파일의 descriptor target file의 descriptor를 넘겨준다. array포인터를 넘겨준다.
#include<errno.h>#include<fcntl.h>#include<pthread.h>#include<stdio.h>#include<string.h>#include<sys/stat.h>#include<sys/types.h>#define PERMS (S_IRUSR | S_IWUSR)#define READ_FLAGS O_RDONLY#define WRITE_FLAGS (O_WRONLY | O_CREAT | O_TRUNC)void *copyfilemalloc(void *arg); //별도 스레드가 수행할 함수(형식 중요) 총 복사된 바이트 수 리턴intmain(int argc, char *argv[]){ /* copy fromfile to tofile */int *bytesptr;
int error;
int fds[2];
pthread_t tid;
if (argc != 3) {
fprintf(stderr, "Usage: %s fromfile tofile\n", argv[0]);
return1;
}
if (((fds[0] = open(argv[1], READ_FLAGS)) == -1) || //argv[1]이 소스파일 경로, argv[2] target파일 경로
((fds[1] = open(argv[2], WRITE_FLAGS, PERMS)) == -1)) {
perror("Failed to open the files");
return1;
}
if (error = pthread_create(&tid, NULL, copyfilemalloc, fds)) { //thread생성하고 tid로 id저장fprintf(stderr, "Failed to create thread: %s\n", strerror(error));
return1;
}
if (error = pthread_join(tid, (void **)&bytesptr)) { //return넘겨줄때까지 pthread_join이 기다린다. heap 공간의 주소값이 bytesptr로 넘어온다. fprintf(stderr, "Failed to join thread: %s\n", strerror(error));
return1;
}
printf("Number of bytes copied: %d\n", *bytesptr);
return0;
}
copyfilemalloc temp.c temp2.c
copyfilemalloc.c
#include<stdlib.h>#include<unistd.h>#include"restart.h"void *copyfilemalloc(void *arg){ /* copy infd to outfd with return value */int *bytesp;
int infd;
int outfd;
infd = *((int *)(arg));
outfd = *((int *)(arg) + 1);
if ((bytesp = (int *)malloc(sizeof(int))) == NULL)
returnNULL;
*bytesp = copyfile(infd, outfd);
r_close(infd);
r_close(outfd);
return bytesp;
}
: 넘겨받은 argument가 int형의 array이다.
descriptor값은 소스파일 target 파일 담긴 시작 주소가 넘어온 것이다.
다음값을 포인터로 참조할려고 시작주소 +1 element 역참조니까 두번째 element target file descriptor
heap 공간에다가 return값을 쓴다. 포인터값이 리턴이 된다.
malloc을 사용하지 않고 return을 받을 방법이 없겠느냐-> stack을 사용해서 리턴받으면?
static int ret; ret = copyfile(); 받아서 return을 하기를. copy thread가 여러개면
malloc을 사용하지 않고 static정적 변수를 사용하면 copy하는 thread가 하나일떄만 작동. copy가 여러개면 복사결과값이 하나의 static 값에 덮어씌워지기 때문에 제대로된 결과값 얻을 수 없었다.
thead에 파일 복사 할 방법이 뭐가 있겠느냐?
-> 이 예제에서만 통하는 방법이긴 한데 두개의 fd array를 넘겨준다. fd는 integer타입. return할때 integer포인터 타입으로 반환하긴했지만 총 바이트 수를 반환. 넘겨줄려했던 return타입이 같다. main thread가 공간을 만들고 thread로 넘겼었다. 방을 하나 더 만들자. array의 3번째 element에 복사한 결과물을 여기에 담아서 return을 하면 thread가 별도로 할당할 필요도 없고 static 할당할 필요도 없고 main thread에서 만들었던 공간을 access 할 수 있다. array에 담아버리면 별도로 return할 필요도 없다. 이 프로그램에서는 실제로 return도 한다. 세번째 array의 주소값을 return을 한다. 자식이 끝나고나서 복사된 바이트 수가 쓰여져 있는 것을 확인할 수 있다. 그런 아이디어를 이야기 하고 있는 것이다. thread는 malloc을 통해서 동적으로 할당한 메모리를 다 사용하고 난 다음에는 clean up해줘야 한다. 동적 메모리 할당한 것과 해제해야 하는것이 달라서 관리 측면에서 비효율적이다. main thread가 array에 pointer를 넘겨줄때 공간을 하나 더 추가해서 넘겨주어야 한다. array 크기가 2가 아니라 3으로 해서 넘겨줘야 한다. file 복사결과 총 바이트 수를 세번째 element에 copy하면 된다. return value는 두번째 파라미터나 만들었던 array의 3번째 element를 통해서 받을 수 있게끔 코드가 짜여져 있다.
callcopypass.c
#include<errno.h>#include<fcntl.h>#include<pthread.h>#include<stdio.h>#include<string.h>#include<sys/stat.h>#include<sys/types.h>#define PERMS (S_IRUSR | S_IWUSR)#define READ_FLAGS O_RDONLY#define WRITE_FLAGS (O_WRONLY | O_CREAT | O_TRUNC)void *copyfilepass(void *arg);
intmain(int argc, char *argv[]){
int *bytesptr;
int error;
int targs[3]; //마지막은 return값을 받기 위한 방.pthread_t tid;
if (argc != 3) {
fprintf(stderr, "Usage: %s fromfile tofile\n", argv[0]);
return1;
}
if (((targs[0] = open(argv[1], READ_FLAGS)) == -1) ||
((targs[1] = open(argv[2], WRITE_FLAGS, PERMS)) == -1)) {
perror("Failed to open the files");
return1;
}
if (error = pthread_create(&tid, NULL, copyfilepass, targs)) { //함수를 복사하는 함수 넘겨주기fprintf(stderr, "Failed to create thread: %s\n", strerror(error));
return1;
}
if (error = pthread_join(tid, (void **)&bytesptr)) { //바이트 수를 저장하고 있는게 3번째 방이 넘겨지게 됨fprintf(stderr, "Failed to join thread: %s\n", strerror(error));
return1;
}
printf("Number of bytes copied: %d\n", *bytesptr); //복사된 바이트 수를 알 수 있다.printf("Number of bytes copied targs[2]: %d\n", targs[2]);
return0;
}
#include<unistd.h>#include"restart.h"// void* 타입의 array가 방 3개짜리 array가 넘어온것이다.void *copyfilepass(void *arg){
int *argint;
argint = (int *)arg; //사실은 integer pointer
argint[2] = copyfile(argint[0], argint[1]); // array index를 통해서 접근r_close(argint[0]);
r_close(argint[1]);
return argint + 2;
}
// 포인터 형식으로 참조할려면 *(((int*)arg)+2) 이렇게 쓰는거
malloc을 쓰지 않고도 thread의 결과값을 return 받을 수 있다.
Wrong parameter passing
Thread를 생성하고 thread에게 parameter를 넘겨주는 예제인데 잘못된 프로그램이다. parameter를 잘못된 방식으로 passing하는 예제. void* printarg라는 함수를 별도의 Thread가 실행하는 task가 되는 것이다. printarg라는 함순데 이 함수의 동작은 fprintf함수를 써서 stderr장치 즉 화면에 Thread received하고 함수의 argument를 integer값을 출력. 함수의 argument는 사실 integer pointer로 넘어온다는 것이고 integer포인터가 가리키는 실제 integer값(역참조니까) 그러니까 main thread가 넘겨준 integer변수를 이 스레드가 화면에다가 출력하고자 하는 것이다. main에서는 10개의 thread를 만들어서 그 10개의 thread가 각각 printarg함수를 호출해서 화면에 자기가 넘겨받은 integer변수를 화면에 출력하도록 하는 것이다.
pthread_t tid[NUMTHREADS]에 thread의 아이디가 저장된다. 그 다음에 for문을 돌면서 pthread_create함수를 돌면서 thread를 생성하고 생성된 i번째 생성된 thread의 아이디는 tid array의 i번째 element에 저장이 된다. 그리고 2번째 parameter는 NULL로 둔다. 새로 생성된 thread가 수행할 task는 printarg이다. (3번쨰 parameter) 넘겨주는 integer값이 i의 주소값. 여기서 i는 for문으로 돌리는 i이다. main thread가 for문의 각 iteration마다 i값을 넘겨준다. 첫번쨰 thread에게는 i가 0인값이 넘어가고 두번째는 i가 1인값.. 10번쨰 thread는 0부터 9까지의 숫자를 화면에 출력하고 끝난다. 순서는 thread가 어떤 순서로 출력할지 모르나 0부터 9까지가 화면에 나오기를 기대하고 프로그램을 짠 것이다. 결론적으로 이것은 잘못된 코드이다. 그다음에 for문은 10번 돌면서 pthread_join함수를 호출해서 기다린다. 종료가 되면 다시 for문을 돌아서 j가 1일떄 이렇게 해서 10개의 thread가 종료될때까지 기다렸다가 main thread가 all thread done하고 전체 프로그램이 종료된다.
#include<pthread.h>#include<stdio.h>#include<string.h>#include<unistd.h>#define NUMTHREADS 10staticvoid *printarg(void *arg){
fprintf(stderr, "Thread received %d\n", *(int *)arg);
returnNULL;
}
intmain(void){ /* program incorrectly passes parameters to threads */int error;
int i;
int j;
pthread_t tid[NUMTHREADS];
for (i = 0; i < NUMTHREADS; i++){
if (error = pthread_create(tid + i, NULL, printarg, (void *)&i)) {
fprintf(stderr, "Failed to create thread: %s\n", strerror(error));
tid[i] = pthread_self();
}
}
for (j = 0; j < NUMTHREADS; j++) {
if (pthread_equal(pthread_self(), tid[j]))
continue;
if (error = pthread_join(tid[j], NULL))
fprintf(stderr, "Failed to join thread: %s\n", strerror(error));
}
printf("All threads done\n");
return0;
}
0부터 9까지가 나왔어야 했었는데 실제 나온 결과는 0이 없다. 문제가 뭔가. 문제 상황이 일어날 수 있는 case는 처음에 main thread가 진행되면서 for문으로 들어와서 pthread_create함수를 호출한다. 그러면 os가 thread를 새로 생성하도록 요청한 것이다. 성공적으로 요청했으니까 return을 받는다. 그런데 이 첫번째 thread를 os가 만들어야 하는데 첫번째 thead가 만들어지는데 delay가 있는 것이다. 그 사이에 main thread는 for문을 다시 돌아서 2번째 pthread_create를 호출한다. 2번째 요청이 들어왔을때 thread가 생성이 되었다. 이 때 앞선 thread가 생성이 된것이다. arg값은 pointer가 가리키는 값이 main thread의 i값인데 지금 i값은 1이다. 그래서 첫번째 thread가 1을 출력하는 것이다.
thread가 생성되서 parameter를 참조할 시점에 mainthread 때문에 참조할 것이 변경이 된 것이다. thread가 생성되는 타이밍에 따라서 mainthread의 i값이 출력이 되기 때문에.
교제의 해결책 ---> 요청하는 타이밍을 늦추자. pthread_create할때마다 매 iteration마다 sleep을 둬서 1초씩 쉬었다가 다음 thread를 호출하자. 아무리 그래도 1초안에는 생성이 될것이기 때문에. i값을 받아서 잘 출력한다. 1초 이내에 thread는 만들어질것이다.
#include<pthread.h>#include<stdio.h>#include<string.h>#include<unistd.h>#define NUMTHREADS 10staticvoid *printarg(void *arg){
fprintf(stderr, "Thread received %d\n", *(int *)arg);
returnNULL;
}
intmain(void){ /* program incorrectly passes parameters to threads */int error;
int i;
int j;
pthread_t tid[NUMTHREADS];
for (i = 0; i < NUMTHREADS; i++){
if (error = pthread_create(tid + i, NULL, printarg, (void *)&i)) {
fprintf(stderr, "Failed to create thread: %s\n", strerror(error));
tid[i] = pthread_self();
}
sleep(1);
}
for (j = 0; j < NUMTHREADS; j++) {
if (pthread_equal(pthread_self(), tid[j]))
continue;
if (error = pthread_join(tid[j], NULL))
fprintf(stderr, "Failed to join thread: %s\n", strerror(error));
}
printf("All threads done\n");
return0;
}
완벽한 solution으로 볼 수 없는게 1초 이내에 thread가 생성되겠지라고 가정하고 있는 것이기 때문에 혹시나 thread생성하는데 1초이상 걸리는 경우가 생긴다면 이 solution은 같은 문제를 발생시킨다.
확실한 방법은 i를 절대 변경되지 않는 변수값을 넘겨주면 된다. 변수를 10개 만들어서 첫번째 thread에게는 첫번째 변수 두번째 thread에게는 두번째 변수. 아무리 thread가 생성된다 하더라도 변수값 parameter로 받아서 출력할 수 있다. 그러면 프로그램 로직이 변경되긴 해야 한다.
Thread safety
내부적으로 static storage 사용하는 경우. 하나의 static storage에 여러 개의 thread가 같이 써서 충돌 문제가 생긴다. 그런 함수는 thread safe 한 함수가 아니다. thread safe한 함수는 여러 thread가 동시에 호출해도 task 수행하는데 문제가 없는 함수. safe하다는 관점에서는 async signal -> signal handler안에서 안전하게 호출할 수 있는. thread safe한 함수가 만드는게 쉬울까 async signal safe 한 함수 만드는게 쉬울까? async signal safe함수는 다중 thread가 아니더라도 충돌 문제가 생길 수 있다. 다중 스레드도 아니고 싱글 스레드에서도 생긴다. thread safe한 함수 만들기가 더 쉽다. POSIX에서는 thread safe 하도록 구현하도록 요구한다. (예전에 그랬다)