대부분의 프로그램, 흔히 우리가 Application Software라고 불리는 것들은 high level language로 작성되어 있다.
이건 우리가 보는 거의 젤 테두리 느낌이다.
만약 high level language로 프로그램이 짜여져 있으면 System Software인 Compiler(컴파일러)가 기계가 이해할 수 있는 machine code로 바꾸어준다. machine code는 도저히 이제 구분하기가 어려운 10101010001.. 로만 구성된 이진 코드이다.
그리고 System Software에는 OS도 포함된다. Operating System, OS는 우리가 사용하는 user Program과 하드웨어 사이에서 인터페이스 역할을 한다. 기본적인 input output도 처리해 주고, 메모리도 할당해주고, 프로그램 task들을 스케쥴링하고 리소스 할당도 다 OS가 해주는 역할이다.
하드웨어는 Processor, memory, I/O controller를 갖는다.
위에 얘기했던 HLL(High Level Language)랑 Binary Machine Language는 이제 program code의 레벨로 나눌 수 있다.
기계가 이해할 수 있는 건 Binary Machine Language이다. 우리가 그나마 잘 이해한다는 C나 java로 코드를 짜도 기계는 이해할 수 없는 애들이다.
먼저, 어셈블리 언어를 알아야 한다. 어셈블리 언어는 그래도 이진코드보다는 조금 직관적이다. 이런 어셈블리 언어로 구성된 것은 one to one으로 machine code와 매칭된다. 어셈블리 언어는 명령어를 텍스트로 나타낸 것이다. 텍스트 하나하나가 기계어로 매치되어 바뀐다. 이걸 바꿔주는게 어셈블러로 보면 된다.
어셈블리 언어보다 이제 우리에게 더 직관적인게 HLL이다. High Level Language는 여러 장점이 있다.
먼저, 개발자가 사용하는 자연어와 비슷하다. 그래서 생산성도 올라가고, 프로그램 관리도 쉬워진다. 또, 프로그램이 컴퓨터와 독립적으로 되는 것이라 효과적이다. 이러한 HLL을 어셈블리언어로 바꿔주는게 컴파일러다.
가상메모리라는 것은 메모리 관리 기법 중 하나로, 프로세스 전체가 메모리 내에 올라오지 않더라도 실행이 가능하도록 하는 기법이다.
가상 메모리의 장점은 다음과 같다.
1. 사용자 프로그램이 물리 메모리의 제약에서 벗어날 수 있다
2. 각 프로그램이 더 작은 메모리를 차지하기 때문에 더 많은 프로그램을 동시에 수행이 가능하다. (물론 그냥 가능한 것처럼 보이는 것이다.)
3. 프로그램을 메모리에 올리고 swap하는데 필요한 I/O의 횟수가 줄어든다.
위의 해당 내용만 알아서는 가상 메모리가 어떤 건지 잘 이해가 가지 않는다. 하나하나씩 배경지식을 알아가면서 가상메모리의 개념을 알아보겠다.
먼저 메모리라는 것은 컴퓨터에서 어떤 존재일까?
컴퓨터에서 컴퓨터는 CPU가 일을 한다. 여기서 일이라 함은 연산을 수행하게 된다.
그런데 CPU가 일을 하려면 아무 정보도 없이 할 수는 없다. 1+2를 수행하더라도 1과 2를 어디서 불러와야 한다.
CPU가 값을 참조해야 한다는 뜻이다. 여기서 값은 레지스터라는 저장 공간에 저장되어 있다. 레지스터는 자료를 보관하는 매우 빠른 기억 장소이다. 그렇지만 레지스터는 용량이 매우 작고, 휘발성이라는 특성을 가지고 있다.
따라서, 레지스터 보다는 조금 더 느리지만, 조금 더 큰 용량인 메인 메모리(물리적 메모리라고 한다)를 두어서 해당 내용을 참조한다.
메인메모리가 레지스터보다는 크기가 크지만, 메인메모리와 레지스터는 용량이 작고 휘발성 특성을 가진다. 그래서, 이 둘보다는 더 많은 내용을 저장하는, 또 비휘발성의 특성을 가지는 DISK memory를 사용한다. (DISK memory는 우리가 흔히 하드디스크(HDD)라고 불리는 것이다.)
CPU는 레지스터와 메인메모리까지의 값만 참조할 수 있다. 그래서 보조저장장치(DISK)에 있는 값을 참조하려면 OS의 도움을 받아서 입출력 작업을 실행해야 한다. 프로그램들은 보통 DISK에 저장되어 있다.
그럼 DISK의 프로그램은 어떤 방식으로 해서 CPU가 실행을 하는 것일까?
먼저 DISK에 프로그램은 이진(binary) 실행 파일 형식으로 존재한다. 만약에 개발자가 작성한 소스 프로그램이 있다면 컴파일러와 링커의 작업으로 실행파일이 생성된다.
예를 들어서, Java로 소스코드를 작성했다고 생각해보자. 그럼 컴파일러는 소스 코드를 내 컴퓨터에서 실행할 수 있도록 바이트 코드로 바꾸어서 소스코드를 JVM에서 실행할 수 있도록 도와준다. 그리고, 링커는 컴파일러에 의해서 생성된 파일을 가져와서 실행 파일로 결합한다.
실행 파일을 실행하면 fork 요청으로 새 프로세스를 생성하고, exec 요청으로 로더를 호출한다. 그럼 여기서 로더는 어떤 역할을 하냐면, 로더는 새로 생성된 프로세스의 주소공간을 사용하여서 지정된 실행 파일을 메모리에 올려준다.
즉, 프로그램을 실행하면 디스크에 존재하던 실행파일이 메모리에 올라오고, 그럼 이 내용을 CPU가 참조할 수 있게 되는 것이다. CPU가 그럼 이제 실행 파일을 실행하면 0번부터해서 시작하는 프로세스마다 독자적인 주소공간을 생성하고, CPU는 이 주소를 바라보는데, 이 주소가 바로 논리 주소이다.즉, CPU는 논리주소를 바라보고 있는 것이다. CPU가 일을 하려면 논리 주소가 메모리 상에 올라와 있어야 한다.
그럼 논리주소는 실제 물리적 메모리의 특정 위치와 매핑 되어야 하는데, 이 매핑 작업을 주소 바인딩 이라고 한다.
바인딩을 하는 방법은 물리적 메모리 주소가 결정되는 시기에 따라서 나누어 지는데, 컴파일 타임 바인딩, 로드 타임 바인딩, 실행 시간 바인딩으로 나누어진다.
여기서 실행 시간 바인딩을 사용하면 가상 메모리를 이제 사용할 수 있게 된다. 실행 시간 바인딩을 하기 위해서는 하드웨어적인 지원이 필요한데, CPU가 주소를 참조할 때마다 주소 맵핑 테이블을 이용해서 바인딩을 점검한다.
레지스터는 현재 프로세스의 물리적 메모리의 시작 주소가 저장되어 있다. 그래서 레지스턴는 논리 주소 + 기존 레지스터 값으로 물리적 주소의 위치를 찾는다. (아까 CPU에 올라올 때, 0번부터 프로세스가 주소공간을 생성한다고 했으니까)
앞에서 말한대로, CPU가 프로세스를 실행하려면 메모리에 올라와 있어야 한다. 그런데 너무 많은 프로그램이 메모리에 올라오면 메모리 공간이 부족하게 된다. 그래서 메모리 공간의 확장 영역으로 스왑 영역 이라는 것을 사용한다.
스왑 공간은 외부 저장장치에 존재하지만 물리메모리의 확장 느낌이다. 물리메모리에 공간이 부족하기 때문에 실행중인 프로세스의 주소공간을 일시적으로 메모리에서 디스크로 내려 놓는 것이다.
스왑 영역은 디스크에 존재하지만 파일시스템과는 별도로 존재한다. 파일시스템은 비휘발성이지만 스왑영역은 메모리 공간의 확장으로 사용하기 때문에 프로세스가 수행 중인 동안에만 일시적으로 저장된다. 메모리에서 스왑영역으로의 이동을 swap in, swap out 이라고 한다.
스왑 영역도 외부저장장치에 존재하기 때문에 OS에 의해 IO작업이 일어난다. 하지만 공간효율성보다는 시간효율성을 고려한 저장이 일어나서 일반적으로 파일시스템에 접근하는 것보다 좀 더 빠른 접근이 가능하다.
즉, 프로세스는 메모리에 올라와야하는데, 만약 현재 실행되고 있는 프로세스 말고 다른 프로세스를 실행하려고 한다면 기존 프로세스를 스왑 영역으로 내쫓고 필요한 프로세스가 물리메모리에 올라와야 한다. 이렇게 된다면 빈번하게 스왑영역과 IO가 발생될 것이다.
만약 프로세스의 크기가 물리 메모리의 크기를 벗어난다면 실행조차 불가능하게 된다. 이런 불편함 때문에 가상메모리 개념이 필요하게 되었다.
즉, 필요한 내용만 물리메모리 위에 올려놓고 사용하면 되지 않을까라는 생각을 사람들이 하게 된 것이다. 이렇게 가상메모리의 개념이 등장한다.
가상메모리는 실제의 물리메모리 기능과 개발자의 논리메모리 개념을 분리한다.
따라서 가상메모리를 사용하면 프로세서 전체의 내용을 메모리에 올릴 필요없이 필요한 부분만 메모리에 올려 실행이 가능하다.
그럼 필요한 부분만 어떻게 올려 줄 수 있을까?
여기서 필요한 페이지만 물리메모리에 적재하는 **요구 페이징 기법(Demand Paging)을 사용한다.
이 기법에서는 주소공간이 하나의 단위가 아니라 여러 개의 페이지로 나눠져 있다. 그 중에서 지금 당장 필요한 페이지들만 물리 메모리에 가져와 사용한다.
그럼 또 의문이 생긴다. 필요한 페이지가 물리 메모리에 올라와 있는지 아닌지를 어떻게 알까?
특정 페이지 메모리 존재임을 구분하기 위해 유효(valid), 무효(invalid) 비트를 사용한다.
invalid는 해당 페이지가 메모리에 없음을 의미하고 이를 페이지 폴트(Page fault)가 발생했다고 한다. 이 경우 보조저장장치에 페이지가 있다면 보조저장장치에서 해당 페이지를 가져온다.
물리메모리에 대응되는 페이지 테이블에 valid, invalid 비트로 물리적 메모리에서 페이지의 바인딩 정보를 확인할 수 있다. 앞서서 말한 하드웨어인 MMU의 도움을 받아 실행 타임 바인딩 기법이 적용된다.
Transaction의 컨텍스트에서 Rollback 은 문제가 발생할 경우 Transaction중에 데이터베이스에 대한 변경 내용을 실행 취소하는 프로세스이다.
Transaction은 일련의 데이터베이스 작업을 하나의 원자 단위로 그룹화하는 방법이다.즉, 연산들을 전부 실행하든지 전혀 실행하지 않는 All or nothing 방식이다.
이 개념은 Transaction내에서 수행된 모든 변경사항이 단일 단위로 commit(데이터베이스에 저장)되거나 rollback(실행 취소)된다는 것이다. Transaction으로 인한 하나의 묶음 처리가 시작되기 이전의 상태로 되돌린다.
예를 들어, 한 은행 계좌에서 다른 은행 계좌로 돈을 송금하는 시나리오를 가정해보자. 거래가 차변영업(한 계좌에서 돈을 제거하는 것)과 신용영업(다른 계좌에 돈을 추가하는 것)을 모두 포함하는 경우, 데이터베이스는 두 가지 영업이 모두 완료되었는지 또는 둘 다 완료되지 않았는지 확인해야 한다.
차변 작업은 성공했지만 신용 작업이 어떤 이유로 실패하면 rollback 작업은 차변 작업을 취소하여 데이터베이스의 원래 상태를 효과적으로 복원한다.
rollback 작업은 일반적으로 Transaction중에 오류나 예외가 발생하거나 사용자 또는 응용 프로그램에 의해 Transaction이 명시적으로 롤백될 때 트랜잭션 관리 시스템에 의해 수행된다.
보통 로그인을 구현할 때, 인증받기 위해 Token 또는 Session을 사용한다. 두 가지 방법의 차이점을 알아보겠다.
Token
토큰은 인증 및 인가에 대한 보다 현대적인 접근 방식이다.
토큰은 일반적으로 Local Storage나 cookie와 같은 클라이언트 측 스토리지 메커니즘에 저장되며, 각 요청과 함께 서버로 전송된다. 토큰은 Stateless 즉, 서버는 클라이언트 세션에 대한 정보를 저장할 필요가 없다.
이를 통해 서버 확장(Scale Up)이 쉬워져 보다 분리된 아키텍처가 가능하다. 토큰은 쉽게 취소되고, 도난의 영향을 덜 받기 때문에 세션보다 안전하다.
쉽게 취소된다는 의미는 서버에 의해서 언제든지 토큰을 무효화할 수 있다는 것이다. 만약 유저가 로그아웃을 하면 서버는 그냥 토큰을 취소하면 되는 것이다.
Session
세션은 클라이언트 상태에 대한 정보를 서버에 저장한다.
즉, 서버는 모든 활성 세션의 레코드를 유지하고 세션 데이터의 스토리지를 관리해야 한다.
세션은 구현이 간단하고 기존 웹 애플리케이션에서 자주 사용된다. 그러나 토큰만큼 안전하지 않기 때문에 세션 ID가 도난당한 경우 세션은 보안에 취약할 수 있다.
일반적으로 토큰은 확장성과 보안이 향상되기 때문에 현대 웹 애플리케이션에 더 나은 옵션이다. 다만 세션은 여전히 일반적으로 사용되고 있으며 기존 웹 애플리케이션 또는 단순 인증 요건을 가진 애플리케이션에게는 적절한 선택사항이 될 수 있다.
그럼 Token을 Cookie와 Local Storage 중 어디에 저장하는 것이 좋을까?
LocalStorage와 Cookie 중 어느 쪽을 선택할지는 애플리케이션의 특정 요건에 따라 달라진다.
Local Storage
로컬 스토리지는 클라이언트 측 스토리지 메커니즘으로 클라이언트 디바이스에 데이터를 저장할 수 있다.
로컬 스토리지에 저장된 데이터는 여러 탭 및 창을 통해 액세스할 수 있으며 사용자가 브라우저를 닫더라도 삭제되지 않는다.
로컬 스토리지는 다른 도메인에서 자바스크립트로 액세스할 수 없기 때문에 쿠키보다 안전합니다.
Cookie
쿠키는 브라우저에 의해 클라이언트 장치에 저장되는 작은 텍스트 파일이다. 쿠키는 클라이언트 세션에 대한 정보를 저장하는 데 사용할 수 있으며 요청 시마다 서버에서 쉽게 액세스할 수 있다. 쿠키의 크기는 보통 4KB로 제한되어 있으며, 적절하게 관리하지 않으면 보안 위험에 취약할 수 있다.
일반적으로 로컬 스토리지는 여러 세션에 걸쳐 유지해야 하는 대량의 데이터 또는 데이터를 저장하기 위한 더 나은 옵션이다. 쿠키는 클라이언트 세션에 필요한 소량의 데이터를 저장하는 데 최적의 선택사항이며, 각 요청과 함께 서버로 쉽게 전송할 수 있다.
결국에 다른 특이 사항이 없는 이상 Token을 사용하여 Local Storage로 저장하는 방법이 좋은 것 같다.
데이터베이스 로깅이란 데이터베이스의 모든 변화 레코드를 가지고 있는 것이고, 데이터베이스의 회복이란 데이터베이스의 transaction들을 수행하는 도중 장애로 인해 손상된 데이터베이스를 손상되기 이전으로 복구시키는 작업이다. 이 정보는 log file로 저장되어 있고 데이터베이스 transaction의 기록으로 역할을 한다. 실패했을 시, 로그 파일은 데이터베이스를 일관된 상태로 회복하기 위해 log file을 사용한다.
데이터베이스가 로깅을 이용하여 데이터베이스를 회복하는 과정은 다음과 같다
데이터베이스는 전체 백업을 수행하거나 정기적인 incremental 백업을 수행하여 백업된다.
데이터베이스에서 transaction이 commit되면, log file에 해당 transaction에 의해 변경된 내용을 설명하는 항목이 생성된다. 이 정보는 장애 발생 시 데이터베이스를 복구하는 데 사용된다.
만약 실패가 일어나면, 데이터베이스는 시스템이 종료되고 복구 프로세스가 시작된다.
복구 프로세스는 로그 파일을 읽고 로그 파일에 포함된 정보를 사용하여 마지막 commit 당시의 상태로 데이터베이스를 recreate하는 것으로 시작된다. 여기에는 오류가 발생했을 때 완전히 완료되지 않은 transaction의 실행 취소가 포함된다.
복구 프로세스가 완료되면 데이터베이스가 다시 시작되고 정상적인 작업을 재개할 수 있다.
로그 파일은 데이터베이스의 저장위치와 분리되어서 실패했을때 잃어버리지 않아야 한다. 추가적으로 log file은 정기적으로 백업되어서 위기 상황을 막아야 한다.
주의깊게 봐야할 부분은 buffer를 활용하는 부분인데, 이 코드에서 buffer n개를 모두 사용하지 못한다. cell의 n-1개만 사용한다는 뜻인데, cell 하나는 채울 수가 없다. 이유는 index의 in과 out이 같은 것을 empty로 간주하기 때문에 마지막까지 사용하면 full인지 empty인지 구분할 수가 없게 된다.
→ in +1== out 일 때 full이라고 생각하기 때문에
( 컴파일할 때, n을 작게 하면 한 cell이 채워지지 않는다는 것을 알 수 있다. )
n개의 cell을 다 채울려면 어떻게 해야할까? in이나 out으로 full이나 empty를 판단하는 것이 아니라, 버퍼 안의 데이터의 개수를 셈으로써 full이냐 empty이냐를 알도록 하면 된다. 그렇게 하기 위해서는 변수가 필요하다. (아래에서는 공유변수 counter를 사용한다.)
개수를 다루는 변수로 counter를 사용하는데, counter는 전역변수이면서 공유변수 이여야 하는데 쓰레드의 counter 공유 변수 동시 접근 시 문제가 생긴다.
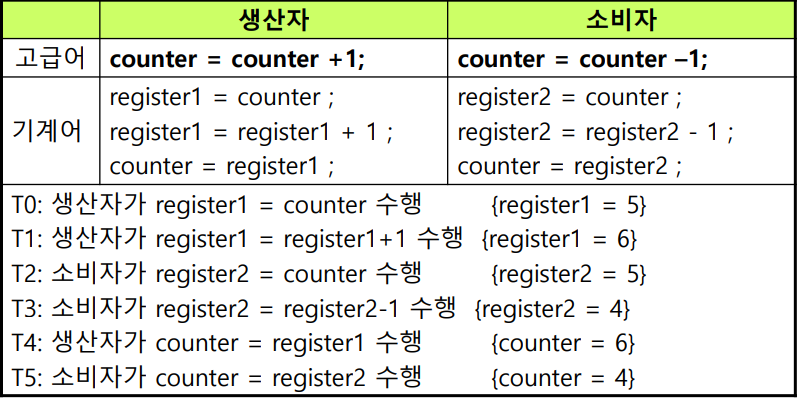
그 문제가 바로 Race Condition이다.
Race Condition
우리가 생각할 때, counter=counter+1이라는 코드가 실행되면 한 번에 딱 실행될거원라고 생각하지만 실제로는 아니다.
이 코드가 기계어로 실행될 때는, 3가지 과정을 거치는데 register에 저장하고 register에서 값을 증가하고 counter에 다시 register에 넣는 단계를 거친다.
counter=counter-1의 경우도 마찬가지이다. 따라서, 공유변수 counter를 두고, 2개의 thread에서 counter값에 접근하면, counter값이 이상하게 변할 수 있다. 위에서 보면 실행 상은 counter가 5여야 하는데, 실제로 기계어로 실행되면 4또는 6이 될 수도 있는 것이다.
이 문제가 Race condtition이다.Race 즉, 서로 다른 쓰레드가 같은 자원을 두고 경쟁하는 상태를 의미한다.
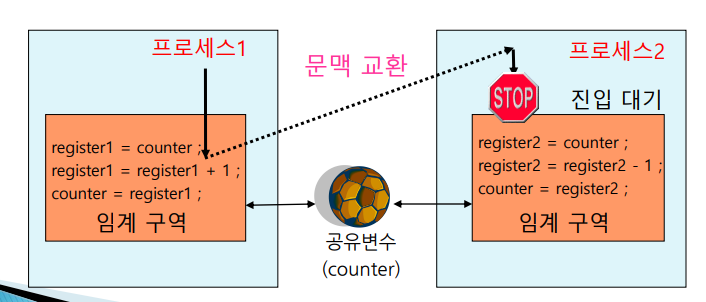
그렇다면 이런 Race condition은 어떠한 방법으로 해결할까? 지금 문제가 되는 것이 기계어가 3줄이니까 3줄이 한번에 돌지 않고 문맥 교환이 일어나서 상대 쓰레드가 들어와서 공유변수의 값을 수정해서 벌어지는 일들이다. 그럼 문맥교환이 일어나더라도 간섭이 없도록 코드가 실행되게 만들면 어떨까?
이 방법이 바로 Atomic한 실행이라고 한다. 예를 들어 counter부분을 임계구역으로 만들어놓으면 생산자에서 코드 2줄까지 실행하고 문맥교환이 일어나서 소비자에서 진입하려고 할 때, 진입하지 못하도록 하고 대기하도록 한다.
원소적(Atomic) 실행
: 공유변수를 통해 상호작용하는 프로세스 혹은 쓰레드 간에 문맥교환이 언제 일어나도 간섭이 없는 실행이 보장되는 것.
-> 공유변수를 사용하는 코드 영역에 임계 구역을 설정한다. 아까 코드에서는 register와 counter를 사용하여서 counter의 값을 증가시키거나 감소시키는 부분을 임계 구역으로 설정하는 것이다.
한 쓰레드가 먼저 임계구역 내에 진입하여 실행 중 문맥 교환이 발생하여 상대 쓰레드에 선점되더라도 그 쓰레드가 임계 구역에 진입하는 것을 허락하지 않고, 대기하도록 한다. 즉, 다른 쓰레드가 실행되더라도 임계구역에는 못들어간다는 의미이다.
임계구역(Critical Section) 설정
임계구역이란 Atomic 실행을 위하여 각 프로세스 혹은 쓰래드가 공유변수, 자료구조, 파일 등을 배타적으로 읽고 쓸 수 있도록 설정한 코드 세그먼트이다.
임계구역 설정하는 것이 비간섭으로 돌게 하는 수단이 된다. (임계 구역의 정의 중요)
→ 공유 변수가 임계 구역처럼 느껴질 수 있겠지만 변수는 수행되는 부분이 아니다. 수행은 코드가 하기 때문에 임계구역은 코드에 만들어 놓는다. 배타적으로 돌도록 코드에 설정해준다.
entry, exit을 설정해 놓음으로써 이 부분은 배타적으로 돌아야한다고 명시한다. enter, exit으로 임계구역을 만들어 놓아야 한다. 화장실을 예시로 든다면, 화장실에 들어갈 때 문을 잠그로, 나갈 때 여는 것과 유사하다.
임계구역을 하면 한쪽이 먼저 들어가게 되겠고, 그렇게 하면 경쟁하는 다른쪽들은 못 들어가고 있다가 먼저 들어간 쪽이 빠져나가면 그제서야 다른 쪽들 중에 하나가 들어가게 됨으로써 진입과 진출이 순서화된다. (Serialize)
이런 것을 동기화라고 한다. 즉, 코드 상으로는 독립적이지만 실행 상황에서 선행제약을 만드는 것이다.
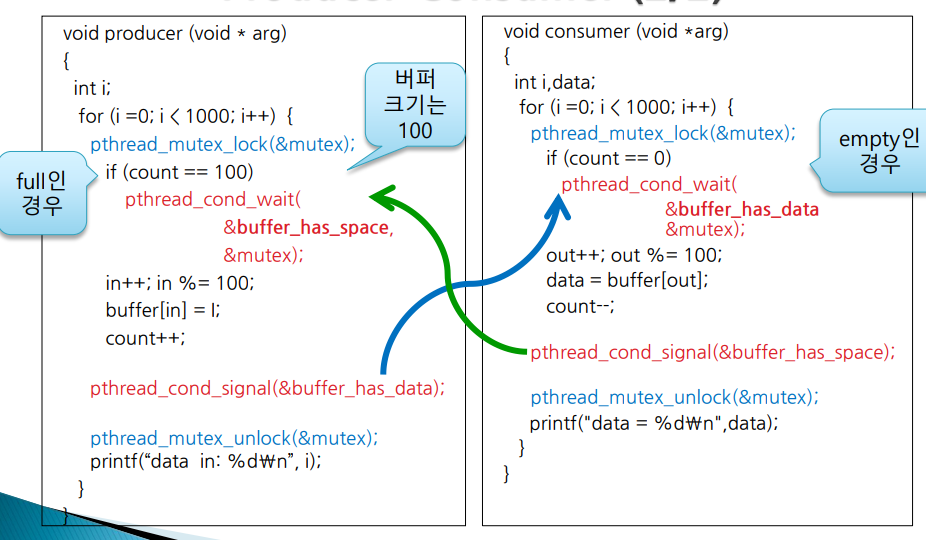
임계 구역 설정은 mutex가 기본이다. lock을 mutex 변수로 선언한다.
위의 코드에서 보면 pthread_mutex_lock으로 잠금을 걸고, 만약 버퍼 크기가 꽉찼으면 pthread_cond_wait으로 대기한다. 그리고 그게 아니라면 in으로 넣고 count값을 증가시켜준 뒤, pthread_cond_signal 함수를 호출한다. 이 함수는 대기 중인 쓰레드에게 signal을 보내 pthread_cond_wait으로 대기중인 쓰레드를 깨우게 되어 다른 쓰레드가 이후의 작업을 진행할 수 있도록 해준다.
- 멀티 프로세싱 혹은 멀티 태스킹(프로세스와 task는 같은 의미) -> 멀티 태스킹을 더 많이 사용함
- 시분할 시스템의 경우 여러
- 하나의 프로그램이 수행 중 여러 개의 프로세스개의 프로세스를 동시에 수행을 만드는 경우도 있음(ex> child)
- 사용자 프로세스와 시스템 프로세스로 나누어짐 - 자원 경쟁 측면에서는 동일
- 사용자 프로세스 - 응용 프로그램이 실행되는 것
- 시스템 프로세스 - 운영체제가 필요에 의해 생성
프로세스의 문맥(context)
- 문맥 : 시분할 시스템에서는 중단과 속개를 반복하게 됨. 중단, 속개 2개의 상태가 있기 때문에 프로세스는 동적인 상태 변화를 하는 객체이다. 프로세스의 모든 실행 정보가 중단될 당시 어디 보호되고 속개될 때 복구되어야 한다. 프로세스의 모든 수행 정보를 문맥이라고 한다. 문맥은 프로세스의 모든 실행 상태를 담고 있기 때문에 간단하지는 않다.
프로세스 문맥의 구성
- 사용자 수준 문맥(User-level context) - 메인 메모리 현재 상태
커널공간이랑 나머지는 프로세스. 한 프로세스가 커널 공간을 제외하면 마치 전체 공간 차지하는 것을 차지하는 것처럼 보인다(가상 메모리이기 때문) 각 프로세스는 가상 메모리 기법 에 의해서 전체 메모리 공간을 사용할 수 있다고 간주하고 넘어가도록 한다.
맨 밑에 text 영역, 그 위에 해당 프로그램에서 선언된 전역변수가 배치되는 부분, 이 광역변수 영역은 data와 bss부분으로 나뉜다. heap은 c에서 malloc으로 동적 메모리 할당 받는 요청이 왔을때 할당하고, free함수가 불리면 회수하는 동적인 곳. runtime시 일어나기 때문에 늘엇다 줄었다 하는 곳이다(힙이 운영된다) 맨 위가 stack인데 stack은 보통 프로그램의 함수가 호출될 때마다 call stack의 자료가 push가 되고 return될때 pop up 된다.
stack에서 다뤄지는 것 중에 지역변수라는 것이 있다. 지역변수는 call stack 내에서 잡히게 되어서 그 함수가 호출될때 stack에 push되고 함수가 return될 때 pop된다.
char g_ch =0 ; 이 부분에서 0으로 선언한 것은 컴파일 시부터 절대 잃어버리면 안되기 때문에 프로그램이 프로세스화 되는 과정에서 메인 메모리가 탑재해주는 그 시점부터 0으로 초기화 시켜줘야 한다.
char g_str[1024]와 int g_int 는 컴파일한 바이너리 코드를 다 잡고 있어야 할 필요가 없다. 초기화 정보가 없는 광역변수가 bss에 해당한다. bss는 속도가 빠르다. - 텍스트 영역 - 프로그램 코드 부분 : 코드는 binaray code를 의미, binary code가 메모리에 탑재된 것을 텍스트 영역
cf> Call Stack 프레임 - 파라미터, 지역변수, return address, frame point가 frame이다. stack에 들어가는 push, pop되는 시스템. Call stack 안에 call stack 프레임이 들어간것.
- 파라미터 : 호출되는 함수의 인자에 assign 되는 값
- 지역변수 : 호출되는 함수 내에서만 생성되는 변수
- return address : 호출되는 함수 종료 시 되돌아가 수행을 계속해 가기 위하여 jump해 가야 할 주소, 함수를 호출한 그 라인의 다음라인이 됨.
- frame point(stack frame pointer) : 스택 상의 프레임 시작 주소, 이 frame이 push가 될 때, 그 전 frame (push되기 전에 top에 있던 프레임)의 frame 시작주소를 여기 기억하고 있다. push 당한 놈의 frame 시작주소를 기억하고 있어야지만 된다.
- 프레임 : 함수호출 시 스택 상에서 운용되는 내용(데이터)
- 프레임 포인터 : 스택 상의 프레임 시작 주소(베이스 주소)
- 프레임의 크기가 함수마다 다르기 때문에 바로 이전 프레임의 프레임 포인터 값을 프레임 내에 간직하고 있어야 함.
Stack Pointer : 콜 스택의 최상위 메모리 주소, stack pointer를 가지고 있어야만 스택 operation을 원할히 할 수 있다. push나 pop같은 것을 수행하기 위해 가지고 있는것. 현재 어디까지 썼는지 stack을. 마지막에 저장된 데이터의 주소.
func1에 10,20을 호출하였을 경우
위에 부분이 main함수의 frame이 된다. main함수의 frame을 보면 frame의 base주소가 있을것이다. 약자로 mfp라고 썼다. main frame의 시작주소를 가리키고 있다. func1이 call일어나면 먼저 파라미터 2개를 push하고 return address를 적고 점프를 한다.
새로 불린 함수 내에서는 ebp(frame pointer)의 값을 copy해서 pop됐을때 다시 복구하기 위한 준비를 한다(mfp값을 caller's frame pointer에 save해두고) ebp에는 현재의 frame base 주소를 ebp에다가 넣어준다. 그리고 지역변수들을 stack에 push된다. stack pointer register는 intel에서는 esp레지스터가 된다. func를 호출하고 나면은 ebp와 esp는 다음을 가리키게 되고 있을 것이고, 나중에 pop up을 하기 위한 대비책으로는 즉 메인 프레임 포인터 값은 mfp에 save해두고 나중에 돌아갈 수 있게 해놓았다.
방금 한것을 assembly 언어로 해석한것
foobar.c -> foo가 불리게 되면 bar(111,222)호출해서 a,b에 assign된다.
main함수가 없어도 compile되어서 생성된 것 볼 수 있다. gcc 컴파일 돌려서 -S하면 assemble 코드가 생성됨.
-m32는 32bit machine assembly code로 생성해달라는 의미이다. 출력해서 나온 파일을 보면, foo에 해당하는 assembly line이 있고 bar에 해당하는 assembly라인이 있다.
foo로부터 bar를 호출하는 부분이 어디냐 하면은 빨간색, movl $222은 esp(stack pointer)가 포인팅하는 곳에다가 222를 move한다는 것은 push하는 것이다. movl $111 %esp도 push를 하는것이다. 그리고나서 call bar를 하면은 instruction ptr을 push하고, foo로 점프를 하는 것이다.
foo로 한 것이 3갱이다. 222 push하고, 111 push하고, instruction ptr값 push하고.
ESP는 stack pointer이고 EBP는 frame pointer이다. frame 내에서의 상대적인 주소들을 적절하게 다루기 위해서 EBP라는 변수를 별도로 두고 있다. 만약에 frame pointer를 따로 쓰지 않는 경우, 특히 frame이라는 개념자체가 없는 경우에는 EBP를 일반 레지스터로 쓸 수 있지만, 일반적으로는 EBP를 사용한다.
instruction ptr은 program counter인데, intel 32bit에서는 EIP(ip가 instruction pointer의 약자이다)레지스터. 프로그램 카운터라고 보면 된다. call을 하면 instruction ptr까지도 push를 하니까 3개가 push가 된것이고, bar로 점프를 하게 되는 것이다.
bar에서는 ebp, 즉 현재까지의 frame pointer register의 값, 그거를 다시 stack에 push를 하는 것이다. 그리고 나서 ebp의 값을 옮기는 것이다. push해서 save했으니까 ebp의 값을 현재 bar의 frame의 base값으로 삼는다. 그리고 나서는 local 변수와 계산들에 대한 operation을 상대적인 주소로 진행한다. (ebp로 operation한다) pop 했을때도 ebp값을 복구해주어야만 돌아가서도 제대로 동작한다는 것이다. ebp값을 save하는 것이 중요하다.
코드상으로는 그렇고 그림으로 그려보면
foo가 돌릴때도 ebp save하는 것이 있었고, bar를 부르기 위해 222,111 push. call이 일어나면 현재의 instruction pointer값을 push하고 3개가 stack에 들어가 있고, ebp값을 copy해서 return됐을 때 복구할 수 있도록 해놓고, 현재의 esp값이 바로 새로운 ebp값이 만들어지는 것이다.
마지막 그림이 call이 이루어진 다음의 상태이다.
- 커널 수준 문맥(Kernel-level context) - 커널이 관리하는 내용
- CPU 내의 각종 특수 레지스터의 내용 : 특수 레지스터의 종류
- 프로그램 카운터(PC) : 다음 수행할 명령어의 주소를 담고 있는 레지스터
- 스택 포인터(SP) : 스택 운영에 필요함
- CPU 상태 레지스터(PSR, Program Status Register) : 예를 들어 모드비트도 상태 레지스터의 한 비트에 해당한다.
// -> 커널이 관리해야 하는 중요한 문맥에 해당한다.
- CPU 내의 각종 범용 레지스터 내용 - 특수 레지스터와 달리 일반 계산용 레지스터가 된다.
- 프로세스의 현재의 각종 자원 사용 정보
- 커널의 프로세스 관리 정보
특수 레지스터에 어떤 것들이 있고, 각각의 역할이 무엇인지 이해하려면 CPU내의 레지스터를 중심으로하는 동작구조를 이해할 필요가 있다.
시작은 먼저 PROGRAM COUNTER(파란색부분)에서 시작해야 한다. CPU는 기본적으로 fetch(가져온다), decode, execute과정을 계속해서 반복하는 것이다. 메인메모리로부터 명령어 하나씩을 순차적으로 읽어오게 된다. 즉, fetch를 하게 된다. 그래서 Program Counter는 다음으로 읽어올 명령어의 주소를 담고 있는 것이 되고, 이 주소를 아래의 Address Buffer에 실으면 어떤 하드웨어적인 동작을 통해서 해당 명령어가 Instruction Register(명령어 레지스터)로 읽혀들어오게 된다. 어디서 읽혀들어오냐면 메인 메모리의 그 주소로 읽혀들어오게 된다. 여기까지가 fetch의 과정이다. 그러면 그 내용을 가지고 decode를 하게 된다. decode는 이 명령어를 해독하는 것이니까 그 다음에는 execute를 시키는 것이다. execute는 옆에 있는 연산 논리 회로(ALU)에 의해서 진행된다. 그러한 과정에서 PC라는 것은 CPU가 이제 다음으로 실행할 명령어의 주소, 즉 다음으로 fetch할 주소를 담고있는 특수 레지스터이다. 만약 방금전에 실행한 명령어가 조건 명령어였고, 그 결과로 특정 명령어로 jump를 해야할 일이 생겼다면 jump해갈 주소를 여기 담게 된다. 결과가 jump할 필요가 없었다면 계속 수행해야될 것이 되니까 조건 명령어의 바로 다음 주소가 Program Counter에 담겨있게 된다. 기본적으로 PC값은 현재 수행한 명령어의 바로 다음 명령어 주소로 자동으로 설정되도록 되어 있다. 그러니까 jump가 멀리 일어나지 않는다면, 자동적으로 그 다음 명령어가 수행되게 된다. 그런데 이게 왜 문맥으로 중요하냐? 시분할 시스템에서 하필이면 어떤 명령어에서 딱 time slice가 소진이 되어서 스케쥴링이 일어났는데, 우선순위가 떨어져서 다른 프로세스에게 그 다음 슬라이스를 주게되었을 경우 그렇게 되면, 현재 돌던 것은 잠시 중지된다. 중지된다는것, 어느 주소까지 수행되고 중지된다 그런 후에 나중에 다시 어떤 조건이 만족되어서 속개된다면 어디서부터 속개되어야 할까? 바로 현재까지 실행되었던 명령어 그 다음 주소의 명령어부터 실행이 되어야 한다. 그래서 그 다음 주소가 어디 담겨있냐하면 Program Counter에 담겨있다. 그래서 이 Program Counter값을 반드시 보존해야지만, 즉, 문맥으로 보존해야지만 시분할 시스템에서 잠시 중단되었다가 속개될때 문제가 없게 된다. 즉, Program Counter가 문맥을 형성하는 중요한 특수 레지스터이다.
그렇게 fetch 해온 데이터를 decode해서 실행하게 되면, 그 결과로 특정한 상태가 발생할 수 있게 되는데, 그러한 상태를 flag register에 반영을 한다. 상태는 다양한 것들이 있는데, 예를 들면 덧셈이나 곱셈을 했는데 캐리가 발생했다던지, 이런것들이 상태에 해당한다. 아까의 process 상태와는 다르게 CPU의 상태를 의미한다. PSR(Program State Register)이라고 하는 상태 레지스터가 있게 되는데, 현재 명령어 실행 후, 상태를 기록하는 것이 기본역할이기도 하지만, 그거 이외에도 decode한 명령어를 수행할 때 조건으로도 작용될 수 있고, 다음 명령어 수행할 때 중요한 정보로 반영되기도 하는 아주 중요한 레지스터이다. 예를 들어 덧셈을 했는데 올림이 생기면 올림이 생겼다는 것을 상태 레지스터에 기록을 해두고, 공교롭게도 덧셈 명령어 수행하고 난 다음에 time slice가 딱 끝나서 다른 process가 잠시 돌았다 그거 돌고 다시 속개될때 올림이 일어났다는 정보를 까먹었다, 어디다 기록하지 않았었다. 그렇게 되면 숫자가 날라가게 된다. 그렇게 되면, 연산에 오류가 생긴다. 상태 자체를 잘 보존해야 한다. 즉 PSR이라는 특수 레지스터의 값이 문맥의 중요한 역할이 된다.
Stack Pointer(SP)가 process 수행 시 call stack에 운영된다고 하는데 이 call stack의 탑에 해당하는 주소를 저장하는데 사용되는 특수 레지스터이다. 이것도 함수 중심의 프로그램을 수행할 때는 굉장히 중요한 역할을 하게 된다. 문맥으로도 따로 관리를 해야하는 부분이다. PC, PSR, SP 레지스터는 시분할 시스템에서 프로세스가 번갈아 가면서 수행될 때, 중단과 속개를 오류없이 반복하기위해서 잘 보존되어야 하는 중요한 레지스터들이 된다.
범용 레지스터들 : 사칙연산이나 논리 연산들을 수행하는 명령어에 사용이 된다. 특히, 그러한 명령어에 operand로 사용되는 계산 목적의 레지스터로서 이 범용 레지스터의 내용도 process가 중단되었다가 속개될때, 잘 보존되었다가 복구되어야만 process가 원할히 돌 수 있다.
사용자 수준의 문맥과 PC, SP, PSR과 어떤 연관관계를 가지고 있을까? 임의 프로세스가 현재 실행되고 있다고 볼 때, Call stack의 탑 주소 관리는 SP 레지스터가 하고, 그리고 text 내에 다음 수행할 명령어의 주소는 PC 레지스터에 담겨있다. 물론 그 명령어가 하나하나 실행되고 난 결과로 생겨나는 CPU의 상태는 PSR에 저장된다. 이렇게 현 프로세스가 진행될 때에는 이러한 특수 레지스터들이 그 수행에 주어진 역할들을 함께 하게 된다. 근데 스케쥴링에 의해서 다른 프로세스가 돌아가기 시작하면 이 값들을 덮어쓰고 만다. 그러면 다시 속개될때 수행에 문제가 생긴다. 따라서 다른 프로세스가 수행을 시작하기 전에 반드시 그 시점의 특수 레지스터 값들을 어딘가에 save해야 된다. 그곳이 바로 PCB이다. 즉, 프로세스 컨트롤 블록이라는 것인데, 그곳에 save를 했다가 다시 속개될때 그곳으로부터 restore를 해야지만 원할하게 돌아가게 된다. 특수 레지스터만 이렇게 PCB를 이용해서 save와 restore를 반복하는 것은 아니다. 범용 레지스터들도 마찬가지이다. (여기 그림에는 안나타냄) PCB가 이러한 레지스터 값들만 보존하는 것일까? 그것은 아니다. 그보다 더 많은 정보들을 담고 있는데, 이에 대해서는 나중에 설명한다.
PC 레지스터와 SP레지스터는 이름 자체가 의미하는 바가 있기 때문에 그 역할을 금방 이해할 수 있다. 그러나 PSR, 즉, Program Status Register 또는 Flag Register는 추가 설명이 필요하다. PSR은 PSW(Program Status Word)라고도 부른다.
예를 보면, Pentium Flag CPU의 경우, 다음과 같은 Flag Register를 갖고 있다.
flag register는 위와 같은 내용을 담고 있다는 것인데, 프로세스의 중단과 속개를 위해서는 반드시 보존되어야하는 주요한 내용인 것이다. 예를 들어, AND 명령어를 수행하고 난 결과가 true이면, ZF 비트가 1이 된것이다. 곧바로 스케쥴링이 되어서 다른 프로세스를 진행시킨 후에 나중에 속개하게 될때 이 flag ZF가 0일지 1일지 보장이 안되면, 만약에 0으로 바뀌어있으면, 속개된 후 프로세스는 엉망이 된다. 따라서, 잘 보존했다가 속개 시에 꼭 리스트화를 하고 속개해야 된다.
ARM 계열의 CPU의 PSR의 사례이다. 여기도 28번에서 31번 bit에 유사한 flag들이 있다. NZCV가 대표적인 4가지 flag이다. 이러한 flag뿐만 아니라 interrupt enable, disable이런 다양한 flag들을 여기에 담고있다. 참고로 ARM process의 경우, processor 수행 모드가 여러가지가 있어서 모드에 따라서 적합하게 작동하도록 아주 정교하게 설계가 되어있다. Fast Interrupt, Trap과 관련된 다양한 모드들이 함께 구분되어 동작되도록 되어있다. 즉, Rest, Data Abort, FIQ... 이러한 여러가지 모드가 있다. 이런 모드로 적절하게 변경을 해가면서 수행이 될 수 있도록 되어있다. 참고로 NZCV(Negative, Zero, Carry, Overflow)의 약자이다. 이런 것들이 상태 플래그가 된다.
문맥교환
- CPU를 다른 프로세스로 넘기는 작업( CPU라는 자원 입장에서 )
- 실행이 정지되는 프로세스의 문맥은 보존되고, 새로 실행되는 프로세스의 문맥이 활성화됨
- 사용자 수준 문맥은 메모리에 남아 있다( 원래 메모리에 있었음 ), 메모리의 현재 상태를 이야기한다. 원래 메모리에 있었기 때문에 그대로 두면 문맥이 보존된다. 커널 수준의 문맥이 문맥 교환에서 중요하다.
- 커널 수준의 문맥 중에서 Program Counter, Stack Pointer, PSR, 범용 레지스터.
- CPU에 있던 레지스터의 내용들은 추후의 복구를 위해 저장(save)되고(왜냐하면 다른 프로세스가 될 때 이 값들을 뭉게버리기 때문에), 스케쥴링된 새로운 프로세스의 문맥이 적재(restore)됨.
- 실행 중단 프로세스의 범용 레지스터와 특수 레지스터 값들을 저장해두고(PCB에 저장한다), 그 다음에 스케쥴링에 의해서 속개될 프로세스 문맥 정보를 그 프로세스 PCB로부터 restore하는 과정을 문맥 교환이라고 한다.
- 그 이외의 커널 수준 문맥, 각종 자원 정보와 프로세스 관리정보들은 어떻게 해야 할까? 그건 PCB에 이미 담겨있기때문에 그대로 두면 보존이 된다.
- 문맥 교환은 프로세스의 중단과 속개를 반복할 때 일어나는 문맥의 보존과 복구의 절차이다.
문맥교환의 시점
- 프로세스가 중단되고 다른 프로세스가 수행되는 경우에 발생한다고 볼 수 있다. 문맥 교환의 시점이라는 것이 프로세스의 상태라는 주제로 넘어가게 되고, 스케쥴링과 PCB에 대한 설명으로도 이어지게 된다.
- 문맥교환이 일어나는 시점은 4가지로 이루어질 수 있는데, ( 스케쥴링, 인터럽트, 입출력 요청, 시그널 대기요청 )
- 첫번째가 시분할 기반의 스케쥴링. 스케쥴링이 일어나는 시점에 문맥교환이 일어날 수 있다. 스케쥴링은 기본적으로 타임 슬라이스가 소진되었을때 스케쥴링이 일어난다.
- 두번째가 인터럽트로 인해 CPU가 선점 당할 때.
- 세번째로 프로세스 스스로가 입출력 요청을 하게 되면, 당연히 다른 프로세스가 CPU를 돌려야 한다. 그 경우 문맥교환이 일어날 수 있다.
- 네번째로 프로세스 스스로가 다른 프로세스가 보낼 시그널에 대한 대기 요청을 하여 CPU를 반납할 때. 즉, 다른 프로세스의 상태 변화를 기다리기 위해서 대기를 해야할 경우 마냥 대기할 수 없으니까 CPU를 반납함으로써 잠시 다른 프로세스가 돌아야되는데 그것을 위해서 문맥교환이 일어난다.
// 문맥, 문맥교환 전부 시분할 시스템이 전제되어 있다.
프로세스의 상태 천이
중단과 속개 2개의 상태보다는 더 복잡하고 다양한 상태가 존재한다. 특히 운영체제의 종류에 따라서 상태들의 종류가 다르다.
프로세스의 상태(영어로 알아두면 좋다.)
생성(new) : 프로세스가 생성된 상태, PCB와 메모리 상의 주소 공간이 마련된 상태.
준비(ready) : CPU의 배정을 기다리는 상태. 큐에 스케쥴링 되기를 기다리는 상태
실행(running) : 프로세스가 CPU에 의해 실행되고 있는 상태. 예를 들어 core가 하나라면 한순간에 돌리는 process는 하나.
대기(blocked) : 프로세스가 어떤 사건(event)이 발생하기를 기다리고 있는 상태 (사건의 예 : 입출력의 완료 또는 시그널의 접수)
종료(terminated) : 프로세스가 종료된 상태
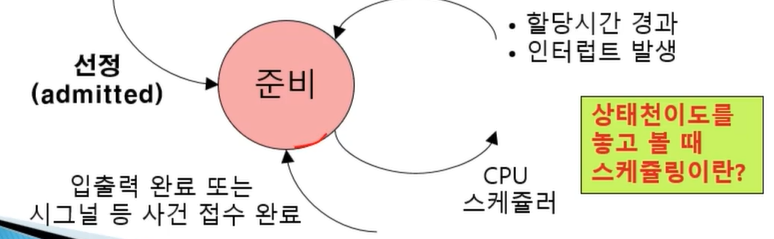
비자발적 문맥교환(할당시간 경과, 인터럽트 발생) 이 경우는 곧바로 준비상태로 처리한다. 사건을 기다리기 위해 block될 이유가 없기 때문이다. 입출력 요청이나 시그널 대기는 대기상태로 천이했다가, 입출력 완료 또는 시그널 접수 되면 준비상태로 천이된다.
실행상태가 되기 위해서는 준비상태를 거쳐서야만 실행상태로 천이될 수 있다. 즉, 스케쥴러에 의해서 CPU가 할당되어야만 실행상태로 가게 된다.
준비상태 : 스케쥴링에 의하여 언제든지 실행이 될 수 있는 상태
여기서 준비 상태를 빠져나가는 화살표는 하나, 그 대상은 실행상태로 가는 경우이다. 즉, 프로세스가 CPU에 의해서 실행되기 위해서는 반드시 준비 상태를 거쳐야 한다. 결국, 준비 리스트(ready list), 준비 큐(ready queue)를 통과해야만 한다는 것이다. 왜 준비 큐만 얘기하지 않고, 준비 리스트라고 하는지? -> 스케쥴러가 큐만 사용하는 것은 아니다. 큐라고 하면 FIFO이 원칙인데, FIFO 원칙만 사용하는 것은 아니기 때문에 혼용해서 부를 수 밖에 없다.
- 준비상태로 천이되어 오는 경우(그림에서 3가지)
1. 프로세스 생성 후, 선정되어 CPU 할당을 대기하고 있게 되거나, (생성상태에서 들어오는 경우)
2. 프로세스가 실행되던 도중에 비자발적인 문맥교환이 일어났거나, (실행상태에서 들어오는 경우, 비자발적 문맥교환)
- CPU의 독점 방지를 위해서 타임 슬라이스 소진 시,
- 또는 인터럽트 발생으로 커널이 CPU를 회수하고 프로세스를 일시 중지시킨 상태
3. 대기하고 있던 입출력 또는 시그널 사건이 완료된 경우(대기 상태에서 들어오는 경우)
- 상태천이도를 놓고 볼 때 스케쥴링이란 준비 상태에 있는 준비리스트 또는 준비 큐에 있는 것을 뭔가의 원칙에 의해서 하나 선택해서 CPU가 수행할 수 있도록 타임슬라이스를 배정해 주는 것.
실행 상태 : CPU가 프로세스를 실행하는 상태
- 실행상태에서 천이되는 경우
1. 실행 상태 -> 준비 상태
실행상태에서 할당시간이 지나고 나면, 회수를 당해서 준비상태로 천이되게 되고, 그렇게 되면 스케쥴링을 통해서 다른 프로세스에 있는 프로세스들과 우선순위 경쟁을 하게 된다.
물론 할당시간이 모두 경과되지 않더라도 입출력 제어기로부터 어떤 인터럽트가 발생했다, 이 프로세스랑 관련이 있는 인터럽트이든, 관련이 없는 인터럽트이든 입출력 제어기로부터 어떤 인터럽트가 발생하면 이때도 역시 준비상태로 천이가 된다. 이렇게 할당시간이 경과되거나 인터럽트 발생하면 비자발적 문맥 교환을 거쳐 준비상태로 천이된다.
2. 실행 상태 -> 대기 상태
: 주어진 할당시간 동안 프로세스를 진행하다보면 두 개의 모드 중에 한 모드에 있게 된다. 사용자 프로그램이 사용자 모드로 수행되다가 시스템 콜을 실행하면 커널 모드로 들어가서 커널 부분을 실행하게 되는데 그러다가 입출력 요청이나 시그널 대기하는 내용을 수행하면 대기 상태로 들어가게 되어있다.
3. 실행 상태 -> 종료 상태 : 퇴출(exit)
대기 상태
대기 상태로 가면 블럭되게 된다. 블럭된 기간 동안은 CPU가 더 이상 프로세스를 수행할 필요가 없어진다. 따라서 CPU를 반납을 하게 되는데, 이렇게 대기 상태로 들어가면 프로세스는 사건별로 구성된 대기 리스트로 이동을 해서 대기를 하게 된다. 그런 후 대기하던 사건이 완료되면, 다시 준비 상태로 천이하게 된다. 사건만 해당하는 것은 아니고 입출력도 해당한다. 대기 상태인 동안 입출력 장치는 입출력을 진행하고 있을 것이고, 어떤 프로세스는 이 프로세스에게 시그널을 보낼 준비를 하고 있을 것이다. CPU는 준비 상태에 있던 프로세스들 중 하나를 스케쥴러를 통해 선택해서 실행시키고 있을 것이다. 대기 상태로 존재한다는 것은 입출려과 CPU가 overlap되어서 동시에 동작할 수 있는 기회를 제공하는 것이다.
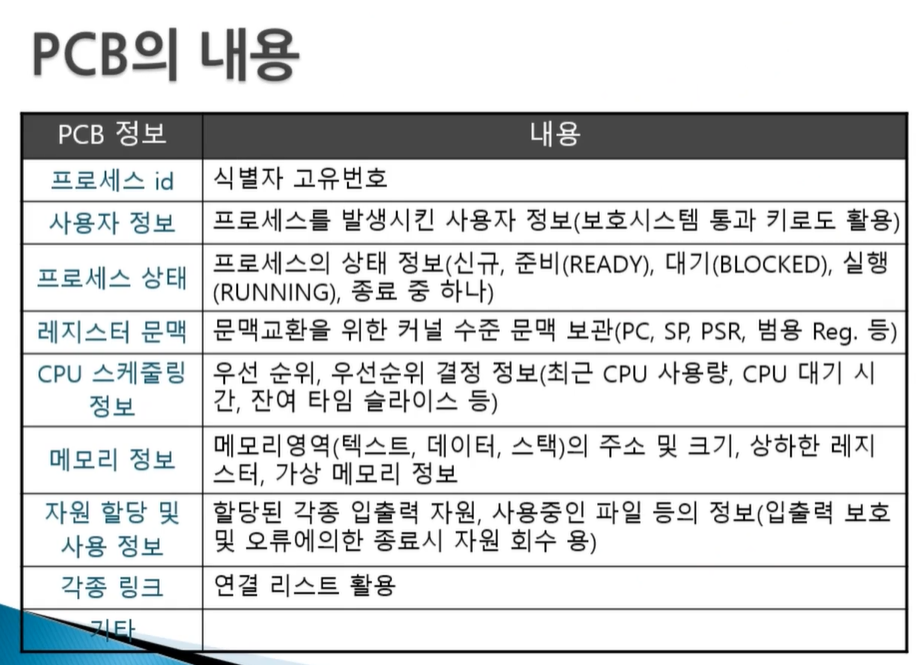
PCB(Process Control Block)
문맥, 상태는 과연 어디에 보관되어 있을까? 보관의 실체는 어디일까? PCB라고 하는 것이다.
PCB는 프로세스의 일생 동안 해당 프로세스의 모든 정적 및 동적인 정보를 저장하느 저장소이다. 결국 프로세스의 문맥을 저장하는 자료구조이자 현재 프로세스의 상태, 그리고 메모리나 파일 통신 등 각종 자원 정보가 저장되는 저장소이다.
커널이 프로세스를 관리하기 위한 실체 - 커널은 PCB를 통해 프로세스 관리.
( 리눅스의 경우 PCB에 해당하는 커널 내 자료구조의 이름은 task struct이다 )
- 프로세스 상태 천이도에 있었던 준비 리스트나 대기 리스트는 결국에는 PCB의 포인터의 리스트였던 것이다.
단, PCB라는 자료구조 자체가 리스트들로 이리저리 옮겨다니도록 구현하진 않고, PCB의 포인터가 리스트를 옮겨다닐 것이다. C가 왜 시스템 언어로 적합한지가 이런 이유이다.
- 실행상태 시에 PCB는 준비리스트에 존재하며, 상태표시만 RUNNING 상태로 변경
5가지 상태 중 실행상태가 있었는데 실행상태라는 것은 리스트를 담고있는것이 아니고, 프로세스가 실행된다는 사실이다. 상태 표시만 있는 것이다. 실질적으로 CPU가 프로세스를 돌리는 것이다. 그래서 PCB에 실행상태 즉 RUNNING이라고 상태를 표시하는 것이다. 단, PCB는 그냥 준비리스트에 존재한다. CPU가 프로세스를 타임슬라이스 동안 실행시키는 특수 상태가 실행상태이다.
프로세스 하나마다 커널 내의 자료구조인 PCB가 만들어져서 사실은 커널은 PCB를 관리하는 것이다는 내용이다.
CPU 스케쥴링 정보 : 스케쥴링은 스케쥴링 알고리즘에 의해서 실행되는데 스케쥴링 알고리즘은 각종 정보를 분석해서 최고의 우선순위의 프로세스를 결정해주어야 하기 때문에, 이를 위해서 어딘가 저장해야 되는데 그게 PCB이다.