Operating System은 disks의 의미있는 정보들을 file system으로 관리한다. (file 단위로 관리한다.)
File System
: file과 attributes의 집합체. 수많은 file을 관리하기 위해 file의 이름, 위치를 별도로 관리하고 있다.
새로 파일 생성하면 disk에 생성된다. physical한 위치를 실제 위치가 아닌 filename과 offset을 이용해서 개념적으로 사용자가 보기 편하게 지정한다. -> 경로명을 의미한다.
Directory
: file의 한 종류이다. 파일 중 directory entries를 포함하고 있는 것이다. directory entries는 filename을 disk의 file physical location과 연관시킨다. directory는 그 안에 파일들을 포함할 수 있다. directory entries를 포함하고 있는 파일이다. directory entries는 filename과 offset 페어의 집합을 가지고 있는것이 directory이다.
ex> dir directory안에는 directory entry 정보를 가지고 있다. 파일에 대한 정보를 나타내는 id => offset. file을 새로 만들게 되면 inode 객체가 새로 생성되고 OS는 unique한 id번호(inode)를 부여해준다. ls에 명령을 주면 확인할 수 있다.
ls -i
inode번호, 파일명 이러한 pair를 directory entries라고 함. 이런 정보들을 가지고 있는 것이 directory다. 대부분의 파일 시스템은 tree structure로 구성되어있다. -> 똑같은 파일이 존재할 수 있다는 장점(다른 디렉토리에 있다면)
Root directory : 다른 모든 sub directory의 부모.
Parent directory : 현재 작업 디렉토리의 parent directory ".." 현재 작업중인 디렉토리 기준으로 부모.
Current working directory: "." 파일의 경로명을 표현할 때 사용한다.
home directory : 사용자 id를 가지고 login . 사용자가 만든 아이디가 보통 home directory가 된다. "~" home directory 의미. cd ~ : 홈디렉토리로 감. cd만 입력해도 됨.
sub-directory : 다른 디렉토리 안에 속해있는 디렉토리.
pathname : 절대경로(absolute path)(fully qualified pathname), 상대경로(relative path)
상대경로는 현재 작업 directory 기준으로 나타낸다.
상대경로의 가지수는 무한대의 가지수가 있을 수 있다.
Change Directory
cd 명령어 사용. 똑같은 작업을 프로그램 상에서도 할 수 있다.
#include<unistd.h>
int chdir(const char* path);
chdir함수
현재 작업 디렉토리를 다른 디렉토리로 변경할 수 있다. 경로명을 parameter로 주면 이동하게 된다. 성공의 의미로 0을 리턴, 실패하면 -1을 리턴한다. 현재 작업중인 directory만 영향을 미친다.
// getcwd 함수를 이용해서 현재 위치를 확인하자.
Get Current Directory : pwd (print working directory) : 현재 작업 디렉토리
#include<unistd.h>
char* getcwd(char* buf, size_t size);
char* getcwd(char* buf, size_t size) : 현재 작업디렉토리가 반환이 된다.
getcwd(cwd,sizeof(cwd)); 이런식으로 쓰면 된다. (물론 cwd는 위에 선언해주어야한다)
첫번째 파라미터 : String을 담을 수 있는 파라미터. 현재 작업디렉토리를 buf에 써준다. (output parameter)
두번째 파라미터 : buf의 크기
buf의 크기를 char array의 크기 를 얼마짜리로 만들어야하나?
return 값은 buf의 포인터 값이 리턴. 실패하면 NULL 리턴.
Buffer size : 최대경로의 길이를 알아야 할텐데 적당히 주기도 위험. 경로의 길이가 얼마가 될지 모르기 때문에.
-> 시스템 별로 PATH_MAX constant값이 설정되어 있다. 이 값을 활용하자. array의 크기를 PATH_MAX로 설정.
물론 정의되어있지 않은 시스템도 있기때문에 임의로 사용하면 된다.
아래는 PATH_MAX로 buffer의 크기를 지정하엿다.
#include <limits.h>
#include <stdio.h>
#include <unistd.h>
#ifndef PATH_MAX
#define PATH_MAX 255
#endif
int main(void) {
char mycwd[PATH_MAX];
if (getcwd(mycwd, PATH_MAX) == NULL) {
perror("Failed to get current working directory");
return 1;
}
printf("Current working directory: %s\n", mycwd);
return 0;
}#ifndef PATH_MAX : PATH_MAX가 정의되어있지않으면 밑에 구문을 실행하라는 내용이다. 이미 정의가 되어있으면 ifndef건너뛰게 되는것이다.
shell에서 실행파일명을 안써도 그냥 ls만 해도 되는 이유?
file name만 주면 shell은 환경변수에서 PATH에 등록된 환경변수를 순서대로 뒤진다. linux에서는 환경변수를 .profile에 설정을 하기도 한다. PATH라는 환경변수 값이 뭐냐 -> env
중간에 PATH가 보임 -> 여기에 directory가 보임. 디렉토리 발견하면 실행.
which 명령어를 사용하여 위치 알 수 있음
which ls
현재 작업디렉토리도 path에 등록되어 있으므로 파일 경로 입력안해도 실행되게 된다. path의 마지막에 등록이 된다.
마지막에 추가해야된다 -> 젤 처음에 추가되면 보안상에 문제가 생긴다. 해커가 ls를 젤 앞에 심어두면 그 프로그램이 실행된다. --> 위험 방지.
Directory Access : shell에서는 cd 명령어를 사용해서 했던 것이다.
프로그램에서 사용하려면? -> opendir, closedir, readdir 함수를 사용한다.
디렉토리 목록을 사용하기 위해 opendir먼저 하고 closedir함수, 하나씩 읽겠다면 readdir 함수 사용한다.
opendir system call
open된것을 하나하나씩 반환을 해준다. 성공하면 DIR pointer를 리턴하고 실패하면 null pointer를 반환한다.
#include<sys/types.h>
#include<dirent.h>
DIR* opendir(const char* dirname);
opendir 사용하기 위해서는 2가지 헤더 include 하고. 오픈된 디렉토리 목록이 반환이 된다. 포인터값이 반환이 된다.
DIR type은 <dirent.h>에 정의되어 있고, directory stream을 나타난다.
Directory stream : 나열된 정보. 타겟 디렉토리 안에 있는 모든 directory entries의 sequence.
readdir system call
Directory read : directory를 readdir함수를 통해서 읽을 수 있다.
#include<sys/types.h>
#include<dirent.h>
struct dirent *readdir(DIR* dirptr);
dirptr값은 opendir함수의 리턴값. readdir함수를 처음 호출하게되면 순차적으로 반환이 된다.
readdir의 리턴값이 dirent라는 구조체로 리턴이 된다.
하나의 directory entry를 가리키는 것이 dirent라는 구조체로 담긴다.
반복적으로 오픈해서 탐색한다.
while문 안에서 readdir을 반복적으로 호출하는 것이다.)언제까지 호출할 수 있냐 -> 더이상 읽을 수 없을때까지.
dirent 구조체에는 d_ino (inode번호). d_name(파일명) 의 pair정보가 저장되어있다.
다 하면 closedir 사용한다.
closedir system call
#include<dirent.h>
int closedir(DIR* dirptr);
성공하면 0을 반환, 실패하면 -1을 반환한다.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <dirent.h>
// DIR* opendir(const char*dirname);
// struct dirent* readdir(DIR* dirptr);
// int clodedir(DIR* dirptr);
int main()
{
DIR *temp = NULL;
struct dirent *file = NULL;
char home[1024];
strncpy(home, getenv("HOME"), sizeof(home));
if ((temp = opendir(home)) == NULL)
{
fprintf("stderr,%s directory 정보를 읽을 수 없습니다.\n", home);
return -1;
}
while ((file = readdir(temp)) != NULL)
{
printf("%s\n", file->d_name);
}
closedir(temp);
return 0;
}rewinddir system call
rewinddir : directory entry sequence를 access할 수 있는 DIR*
내부 포인터를 다시 처음으로 되돌린다. 다시 첫번째 directory entry가 반환이된다. 첫번째 디렉토리를 다시 호출해야겠다 할 때 사용.
#include<sys/types.h>
#include<dirent.h>
void* rewinddir(DIR* dirptr);
showname.c
#include <dirent.h>
#include <errno.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
struct dirent *direntp;
DIR *dirp;
if (argc != 2) {
fprintf(stderr, "Usage: %s directory_name\n", argv[0]);
return 1;
}
if ((dirp = opendir(argv[1])) == NULL) {
perror ("Failed to open directory");
return 1;
}
while ((direntp = readdir(dirp)) != NULL)
printf("%s\n", direntp->d_name);
while ((closedir(dirp) == -1) && (errno == EINTR)) ;
return 0;
}target directory는 argv[1]에 target directory가 들어있다. dirp 포인터값을 가지고 access할 수있다.
d_name을 출력한다. 모든 디렉토리 탐색하면서. null이면 모두 읽었으니까 빠져나와서 close(dirp)한다.
File status information
lstat, stat 함수 이용하면 특정 파일의 속성 정보들 알 수 있다. file을 이름으로 접근한다.
(stat 명령어는 Linux 파일에도 있다) <sys/stat> 헤더파일 include하고 사용해야 한다. 여러가지 정보들을 두번째 파라미터로 반환해준다.
#include<sys/stat.h>
int lstat(const char* restrict path, struct stat* restrict buf);
int stat(const char* restrict path, struct stat* restrict buf);
stat, lstat, fstat 함수들은 모두 파일 정보를 읽어오는 함수이다. 모두 int형 정수를 반환한다.
restrict는 그냥 없다고 생각하고 봐도된다.
그럼 lstat이랑 stat은 뭔 차이일까?
l은 link라고하는 파일. link라고 하는 것은 윈도우에서 바탕화면 아이콘이 링크를 의미한다고 생각하면 된다. 바탕화면 아이콘 더블클릭하면 원본파일이 실행되는 것처럼 symbolic link가 바탕화면 아이콘을 의미한다고 생각하면된다.
그럼 stat과 lstat에서 첫번째 파라미터로 link가 오게 되면 link의 stat정보를 표현하냐 아니면 원본파일의 stat을 표현하는가??
여기서 stat과 lstat에서 차이가 생긴다.
stat함수에서 link를 주면 원본파일의 status information 반환된다.
lstat함수에서 link를 주면 link파일 자체의 속성파일이 반환된다.
성공하면 stat구조체에 파일 정보들로 채워진다.
구조체의 필드 정보(stat 구조체의 필드 정보들)

printaccess.c
#include <stdio.h>
#include <time.h>
#include <sys/stat.h>
void printaccess(char *path) {
struct stat statbuf;
if (stat(path, &statbuf) == -1)
perror("Failed to get file status");
else
printf("%s last accessed at %s", path, ctime(&statbuf.st_atime));
}last access time을 ctime이라는 함수를 써서 string으로 변환함.
Determining the type of a file
st_mode를 써서 targetfile이 디렉토리인지 아닌지 판단하는 함수.
st_mode type을 조사하기 위한 매크로가 있다. S_ISDIR쓰면 st_mode가 디렉토리인지 확인.
#include <stdio.h>
int isdirectory(char *path);
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr,"Usage: %s filename\n",argv[0]);
return 1;
}
if (isdirectory(argv[1]))
fprintf(stderr,"%s is a directory\n",argv[1]);
else
fprintf(stderr,"%s is not a directory\n",argv[1]);
return 0;
}man inode확인하면 field의 의미들 나옴.
UNIX File Implementation
: 파일의 종류는 주로 파일의 확장자를 통해서 파일의 타입이 결정된다. 파일의 타입을 결정하는 것이 OS level 혹은 application 레벨에서 파일의 타입을 구분하는 경우가 있다. 확장자는 OS가 구분하기 위함이 아니라 사용자가 구분하기 위함이다. Directory가 계층을 이뤄서 구성이 되고, directory안에 directory entry 정보들이 들어간다. 하나의 entry에는 filename과 inode번호를 가지고 있다.
inode
: inode는 파일의 정보를 담는 객체이다. 각각의 파일은 inode를 가지고 있고, inode number로 구별된다. Inode는 파일에 대한 정보를 저장하고 있다. stat이나 lstat함수를 호출하면 OS에서 파일에 대한 정보를 inode에서 찾아서 들고온다. 들고와서 stat구조체에 담아준다.
시스템에서 생성할 수 있는 inode는 한계가 있다. inode의 크기는 파일의 크기와 관계없이 고정이 되어 있다. inode안에 파일의 컨텐츠가 들어있는건 아니므로 contents를 찾아갈 수 있는 포인터 정보만 있다.
inode의 구조
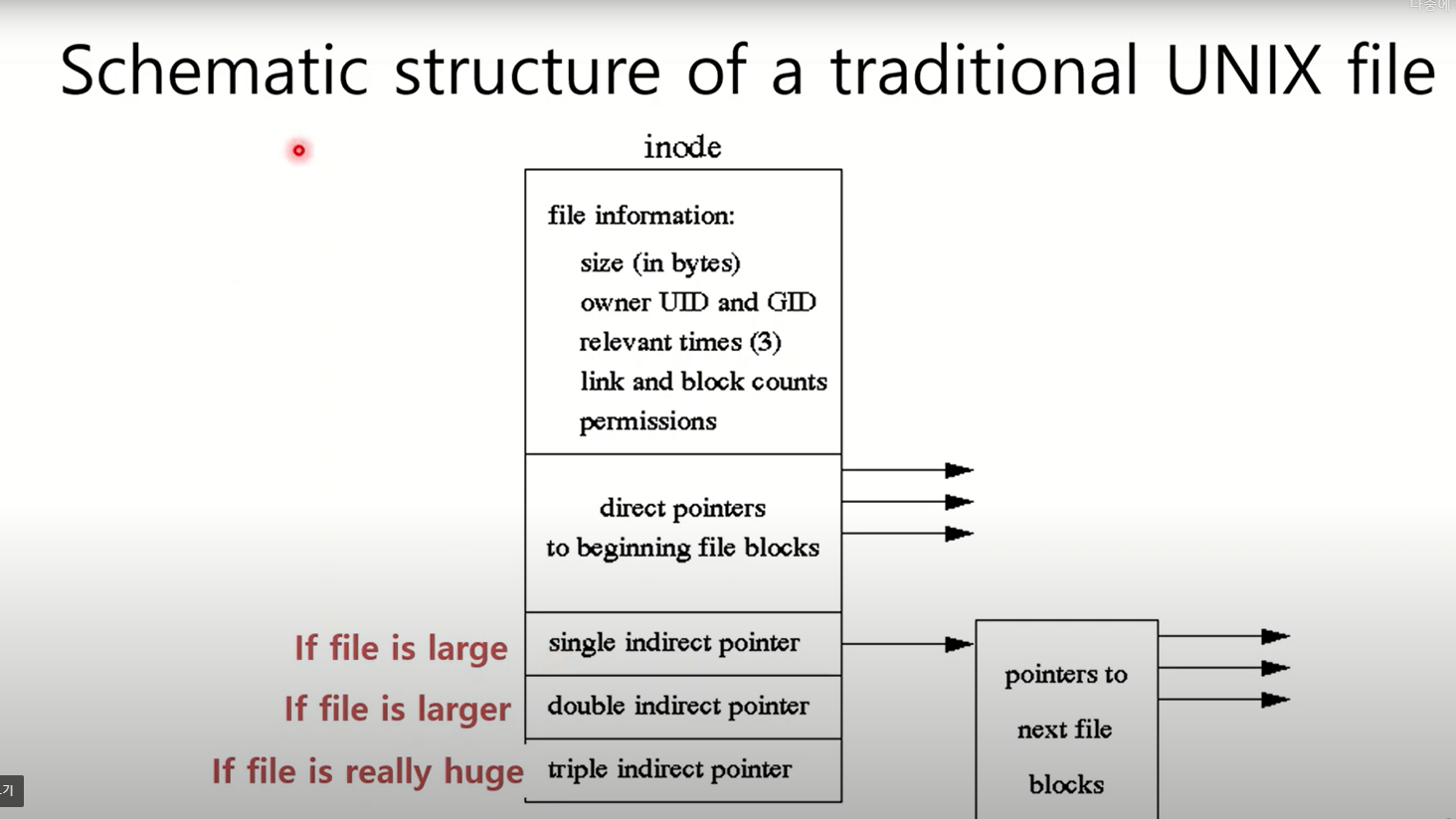
inode에서는 pointer 종류가 구분된다.
direct pointer는 파일의 콘텐츠 블럭을 가리키는데 파일 블럭을 직접 나타낸다. 파일 블럭안에는 파일 내용이 바로 있다.
indirect pointer는 간접적으로 파일블럭을 가리키는 포인터이고 종류는 여기서 3가지가 있다.
single indirect pointer는 한단계 거쳐서 파일 블록을 가리킨다. double indirect pointer는 두 단계, triple indirect pointer는 3단계를 거쳐서 파일을 가리킨다.
direct pointer의 개수만큼 file의 블럭을 direct pointer가 직접 가리키게 된다.
indirect pointer가 가리키는 block에는 파일 콘텐츠가 없고 direct pointer의 값들이 들어가 있다.
그렇다면 왜 indirect pointer를 가질까?
indirect pointer의 존재 이유는 파일이 크기 때문에(컨텐츠 내용이 많음) 많은 개수의 file block을 가리켜야 해서 direct pointer만으로는 부족하다. single direct pointer로 direct pointer들을 가리키는 block을 가리킬 수 있으므로 유용하다.
Directory implementation
: directory라는 것을 어떻게 구현할까? directory안에 directory entry정보가 있다. directory도 하나의 파일이기 때문에 파일 type중 directory 타입이라는 파일이다. directory는 file name과 file location을 담고 있다.
directory = inode number(file location 표현) + file name
inode에 접근하려면
Advantages of inode + filename
File system은 디렉토리들로 구성이되어 있고 디렉토리안에 디렉토리 entry 정보가 들어있다. Directory entry정보란 것은 inode + filename을 유지한다. Directory entry 안에 파일 자체에 대한 정보는 들어있지 않다. 전체적인 파일 시스템 구조는 디렉토리 엔트리들의 집합으로만 표시되어있다. 디렉토리 구조의 크기는 크지 않다. 대부분의 OS에서 분리하는 식으로 파일구조가 이루어져 있다.
실제파일과 directory를 구분하는 장점들은 일단 파일명을 변경할때 간단하다. 파일이름이 디렉토리 entry에 있기 때문에 실제 inode에 찾아갈 필요없이 directory entry만 찾아가서 변경하면 된다. 실제 그 파일의 inode객체를 이동시킬 필요가 없이 directory entry만 옮기면 된다. File move, mv 명령을 가지고 파일의 디렉토리를 옮길 수 있고 이름을 변경할 수 있다. 파일을 다른 디렉토리로 이동하겠다 하면 파일의 inode와 컨텐츠 블록 전체가 이동하는게 아니고 디렉토리 entry만 변경하게 된다.
예를 들어 크기가 기가바이트 크기의 파일을 다운로드 받는다고 하자. 이 파일을 다른 디렉토리로 이동시킬 때 많은 시간이 필요하지 않다. 왜냐하면 파일이 다 이동되는게 아니라 디렉토리 entry만 이동하기 때문이다. 그러나, 파일을 다른 디렉토리로 복사하게 되면 현재 파일 내용과 똑같은 파일을 copy해야하기 때문에 inode를 새로 만들고 contetns도 새로 블록이 생성되어야하기 때문에 시간이 오래걸린다.
또, 디스크 상에 실제 파일 블럭은 하나만 존재하더라도 그 파일을 나타내는 이름은 여러개가 있을수도 있다. 파일은 하난데 파일을 나타내는 link는 여러개를 둘수있다. 같은 inode를 가리키는 디렉토리 entry만 추가하면 되기 때문에 쉽게 추가할 수 있다. 그게 link개념이 되는거다. . 디렉토리 entry의 집합 디렉토리 구조자체는 크지않다. 왜냐하면 실제 파일정보는 inode라는 별도의 객체에 저장이 되어있기때문에 directory entry자체는 크기가 작다.
inode구조를 통해서 inode안에 direct, indirect포인터를 통해서 파일블럭을 찾아갈 수있다. 포인터가 몇개의 파일블럭을 가리킬 수 있느냐에 따라 하나의 파일의 최대 크기가 결정이 되는것이고 하나의 포인터를 통해서 이 파일이 표현할 수 있는 최대 크기가 몇바이트 되냐가 예제에 나와 있다.
(Exercise)
: 어떤 inode객체가 있는 inode가 128바이트라고 가정하자. 포인터는 4바이트짜리다. 가정에서 status information이 차지하는 공간이 68바이트였다. inode공간이 크게 나누면 status information 차지하는 공간, pointer가 차지하는 공간으로 나뉜다.
하나의 블럭의 크기가 8kbyte이다. inode에는 파일 콘텐츠 블럭도 있고 포인터 담는 블럭도 있다. 블럭을 가리키는 포인터의 크기도 32비트 4바이트. 이렇게 가정이 되어있을때 이 inode 객체 안에 direct 포인터 공간이 얼마나 있을까. 이 inode안에 direct pointer는 몇개가 있을 수 있을까. 그럼 포인터 정보를 봐야된다 .포인터는 2가지 종류가 있었다. direct, indirect포인터 또 indirect포인터는 종류가 3가지이다. indirect포인터는 이렇게 하나씩 있다. indirect포인터 3개가 차지하는 공간은 4바이트 공간이 3개가있는거니까 12바이트를 차지한다. 전체 inode크기에서 status information과 indirect 포인터 차지하는 공간 빼면 128 - 12 - 68 = 48 -> 이게 다이렉트 포인터가 차지하는 공간. 다이렉트 포인터의 개수는 48/4 = 12. 즉 12개의 다이렉트 포인터가 존재한다.
그 다음 질문을 보면 다이렉트 포인터를 가지고 얼마나 큰 파일 컨텐츠를 담을 수 있겠느냐. 다이렉트 포인터를 가지고 얼마나 큰 파일을 가질 수 있겠느냐. 12개의 포인터가 있는거니까 다이렉트 포인터 하나가 파일 블럭 하나를 가리키게된다. 파일 블럭 하나가 블럭하나가 8Kbyte이다. 12*8kbyte의 블럭을 가리킬 수 있게 되는것이다.
이렇게 되면 96킬로바이트 크기의 파일콘텐츠를 가질 수있다. 8 kilobyte는 8곱하기 2의10제곱 바이트다. 1킬로바이트라는 것은 2의 10제곱 바이트로 분리하기 때문. 1024바이트*8. 2의 10승 킬로바이트는 1메가바이트.
저장공간의 단위는 이런식으로 표현한다. 8192바이트 12개가 있는것이다. 98304바이트가 된다. 다이렉트 포인터 12개 가지고는 최대 96kb밖에 못하는 것이다. 그래서 indirect pointer가 필요한 것이다.
single indirect pointer를 가지고는 얼마나 큰 크기의 컨텐츠를 가질 수 있겠는지 계산해보자. single indirect pointer는 block을 하나 가리키고 있는데 block안에 direct pointer들을 가지고 있다. direct pointer하나가 파일 블럭을 가리키고 있다. single indirect pointer를 가지고 몇 개의 파일블럭을 가리킬 수 있냐면 direct pointer개수만큼을 가리킬 수 있다. pointer block안에 direct pointer가 몇 개가 있냐의 문제이다. block하나가 8kbyte짜리니까 이 블럭안에 directpointer가 몇개가 들어갈 수 있겠느냐. 포인터하나가 4바이트이기 때문에 8kbyte를 4byte로 나누면 몇 개의 direct pointer를 가지는지 확인할 수 있다. 2048pointer. 2의 11제곱 개가 된다. 그래서 하나의 block안에 2048개의 다이렉트 포인터가 있다는 얘기다.
각각의 다이렉트 포인터로 파일 블럭하나를 가리킬 수 있으니까 2048개의 파일블럭을 가리킬 수 있다. 파일블럭하나도 8kb니까 2048개 * 8kb-> single indirect pointer가지고는 16777216바이트 --> 16mb 정도의 크기를 가지는 것이다. single indirect pointer를 가지고 16mb 콘텐츠를 가질 수 있다. 같은 방식으로 확장해서 생각해보면 double indirect pointer를 가지고는 얼마나 큰 콘텐츠를 가질 수 있을지 계산할 수 있다.
Hard Links and Symbolic Links
: 링크라고 하는 것은 파일 이름과 inode사이의 연관관계를 표현한 것을 link라고 한다. filename은 디렉토리 entry안에 포함되어있었고 inode객체와의 연관관계를 표현한것을 링크라고 한다.
UNIX 시스템에서는 두가지 시스템의 link가 있다고 얘기한다. link라고 하는것이 하나는 hardlink symbolic link 또는 softlink라고 표현한다. 링크도 hard와 soft로 구분된다. 강한association을 가지고 있는게 hardlink이고 느슨한 연관관계가 symbolic link이다. 실제 구조도 보면 이래서 hard구나 symbolic이구나를 확인할 수 있다.
Directory entry 자체가 사실 hard link를 표현한 것이다고 얘기한다. directory entry는 어떤 파일의 inode를 직접 가리키고 있는 객체다. inode 번호를 통해서는 inode를 찾아갈 수 있다. 보통 파일 하나를 생성하면 그 파일을 나타내는 inode객체가 하나 생성된다. inode객체가 생성되고 inode번호가 부여된다. inode번호는 directory entry에 저장된다.
예를 들어 test라는 파일의 속성과 상태정보 콘텐츠를 찾아갈 수 있는 inode가 생성되고, 파일을 하나 만들게 되면 내부 시스템적으로 inode객체와 directory entry가 생성이 된다. directory entry 자체가 hardlink를 가리킨다. 파일명과 inode사이의 연관 관계를 표현한 것이다. inode번호가 test file inode를 직접 가리키고 있다. 디렉토리 entry자체가 디렉토리 디렉토리 entry가 바로 link, test라는 파일명과 그리고 inode번호가 inode를 결국 나타내는 것이다.
파일명과 inode사이의 연관관계 다이렉트한 연관관계 표현한게 hardlink다. 조금 더 표현하면 내가 지금 절대 경로로 표현해서 루트 밑에 temp라는 디렉토리 밑에 test.txt라고 하는 파일을 하나 만들겠다고 했을 때 디렉토리 구조가 있으니까 디렉토리 entry중에 test.txt라는 entry가 추가 되고 test.txt의 inode가 만들어지고 inode번호가 디렉토리 entry안에 할당이 된다. root밑에 temp 디렉토리 밑에 test.txt파일이 보인다. 디렉토리 entry에 하나가 추가되는 것이다. 파일 하나 만든다고 하는게 파일명과 inode가 직접 direct 연결된걸로 표현한게 하드링크다. 하드링크는 별도로 만드는게 아니라 파일을 만들면 만들어지는 것이다. 재밌는건 파일을 가리키는 하드링크를 또 만들 수 있다. 그냥 파일을 만드는 것도 하드링크 만드는건데 또 추가할 수있다. 디렉토리 엔트리를 하나 추가하는것이다. hardlink개념은 파일명과 inode를 직접적으로 연결시키는 directory가 hardlink이다.
symbolic은 직접연결이 아니라 간접적으로 연결시키는게 symbolic link다. 별개의 파일이고 그 파일안에 원본 파일로 가는 경로명이 들어있다. 이게 symbolic link라는 걸 OS가 알게 되면 원본 파일의 경로를 보고 원본파일에 inode로 찾아간다. symbolic link를 만들면 symbolic link에 해당하는 디렉토리 엔트리가 추가된다. 근데 symbolic link에 해당하는 inode가 있는데 이 inode안에 보면 원본파일의 경로가 들어가있다. inode안에 원본파일 경로가 있다. 그럼 OS가 확인하고 얘는 심볼릭 링크네? 하면 탐색을 멈추는게 아니라 원본파일의 경로를 계속 쫓아간다. /temp/sym이라는 파일을 오픈하겠다하면은 /temp/sym파일의 inode를 봤더니 inode가 symbolic이네? 하고 다시본다. 아 원본은 /temp/test.txt구나 해서 얘를 open한다. symbolic link를 통해 간접 연결, indirect하게 연결되어있다.
이전에 stat함수를 얘기하면서 lstat함수를 얘기하면서 첫번째 변수로 symbolic link가 오게 되면 이 파일의 status information이라고 하는게 심볼릭 링크자체의 정보가 있고 아니면 원본 파일의 어떤 status를 반환하느냐 lstat을 쓰고 첫번째 symbolic link를 주면 바로 symblolic link의 status가 반환된다. 그냥 stat함수를 써서 symbolic link주면 원본의 status가 반환된다. symbolic이 바탕화면 아이콘 이라고 생각하면 된다.
그래서 inode의 status information중에 어떤 정보가 있었냐면 stat 함수의 결과인 stat 구조체 중에 number of hard link에 해당하는 필드가 있다. hard link의 개수 hardlink가 꼭 하나가 아니라 여러개가 있을 수 있다. hardlink를 추가할때마다 inode 링크값이 하나씩 늘어난다. default로는 카운트값이 1인데 파일에 대해서 hardlink를 하나 더 추가할 수 있다. hardlink의 디렉토리 엔트리가 추가되는것이다. inode 안에 이 inode를 가리키는 카운트값이 유지가 된다. 카운트값이 왜 유지되냐 하면 이 inode 값을 언제까지 유지할꺼냐 os가 판단할 수 있는 기준으로 카운트값을 사용한다.
파일이 생성이 되면 새로운 디렉토리가 생성이 되고 새로운 inode가 생성이 된다. hardlink라는 것은 디렉토리 reference라는 것을 가리키는 것이고 직접적인 포인터정보를 가지고 있는 것이다. 파일과 연관된 파일명이라는 것은 간단하게 디렉토리 엔트리에 포함되어있는 label이라고 표현을 하기도 하는데 그냥 파일이름이라고 생각하면 된다.
그리고 같은 파일인데 같은 파일을 가리키는 게 꼭하나가 아니라 여러 개가 있을수도 있다. 그 하드링크의 이름은 같은 디렉토리안에 다른 이름으로 존재할수도 잇다. 다른 디렉토리에 원본으로 존재하고 다른 디렉토리에 위치할수도있다. 파일을 생성하면 inode가 생성되고 디렉토리 entry도 추가되면 inode를 access할수있다.
같은 inode를 가리키는 디렉토리엔트리를 또 만들 수 있다. 같은 inode가리키는 hardlink이름이 여러개가 있을수있다. 같은 이름일수도 있고 다른이름일수도 있다. 이것은 symbolic link도 마찬가지다. 경우에 따라 필요하다면 다른이름을 통해서 hardlink를 access할때 어떤 특정 디렉토리를 통해서 파일을 변경하게 되면, (파일 컨텐츠나 뭐 속성) 어떻게 되냐면 예를 들어 test prime이라는걸로 변경했다면 test가 가리키는 inode에 뭔가 추가를 한다. 그 변경된 사항이 test라는 이름이 test라는 걸로 해도 영향을 끼친다. 같은 파일을 가리키고 있기 때문에 다른 하드링크의 이름으로 변경된 사안이 그대로 반영된다.
이건 하드링크가 아니라 symbolic link도 마찬가지다. 하드링크는 같은 파일시스템 내의 파일에 대해서만 참조를 할 수있다라는 제약 사항이 있다. 새로운 하드링크를 또 생성을 할수있고 새로 생성하면 새로운 디렉토리 entry만 추가되는 것이다. 새로 추가되는것은 같은 inode를 가리키기 때문에 inode번호가 동일하다. 하드링크를 추가하기 위한 shell 명령어는 Ln(link의 약어)명령어를 통해 원본 파일의 hardlink를 추가할 수 있다.
이렇게 추가하면 link count값이 증가하게 된다. 반대로 하드링크가 삭제될때 마다 link count가 삭제된다. 삭제는 rm으로 하면 된다. 하드링크를 생성하기 위해서는 ln shell 명령어 시스템 콜 함수는 link이다. 삭제하기 위해서는 shell명령어는 rm., system call 함수는 unlink. 하드링크를 삭제하면 link count값이 감소한다. 그래서 삭제하다가 삭제해서 count값이 0이 되면 inode 자체가 삭제된다. count값이 0이 아니면 inode유지, 해당 디렉토리 entry만 삭제. inode의 카운트값이 언제까지 유지되는지 보고 결정한다. 최초에는 그냥 파일을 만들게 되면 link count값이 1이니까 rm을 통해서 hardlink를 삭제하면 inode자체도 삭제를 하게 된다.
Link Counter : 대부분의 파일 시스템은 하드링크를 서포팅하고 같은 파일을 가리키는 하드링크가 링크카운터값을 inode에 유지하고 있다. link counter는 정수형 숫자이다. 그리고 link counter의 integer값은 link의 총개수를 유지하는 것이고 새로운 hardlink가 추가될 때마다, link가 삭제될때마다 link count값이 감소하게 된다. 0이되면 os는 inode자체도 파일이 이제 삭제가 되는것이다. 삭제된 inode공간은 system에 반환된다.
#inlcude <unistd.h>
int link(const char* path1, const char* path2);
int unlink(const char* path);
link는 파라미터 2개오고 첫번째가 원본 경로명, 두번째가 생성될 경로명이 된다.
unlink는 삭제될 파일의 경로명이 파라미터로 온다.
Example
$ ln / dirA/name1 /dirB/name2
The following code performs the same action as the above
#include <stdio.h>
#include <unistd.h>
if(link("/dirA/name1","/dirB/name2")==-1)
perror("Falied to make a new link in /dirB);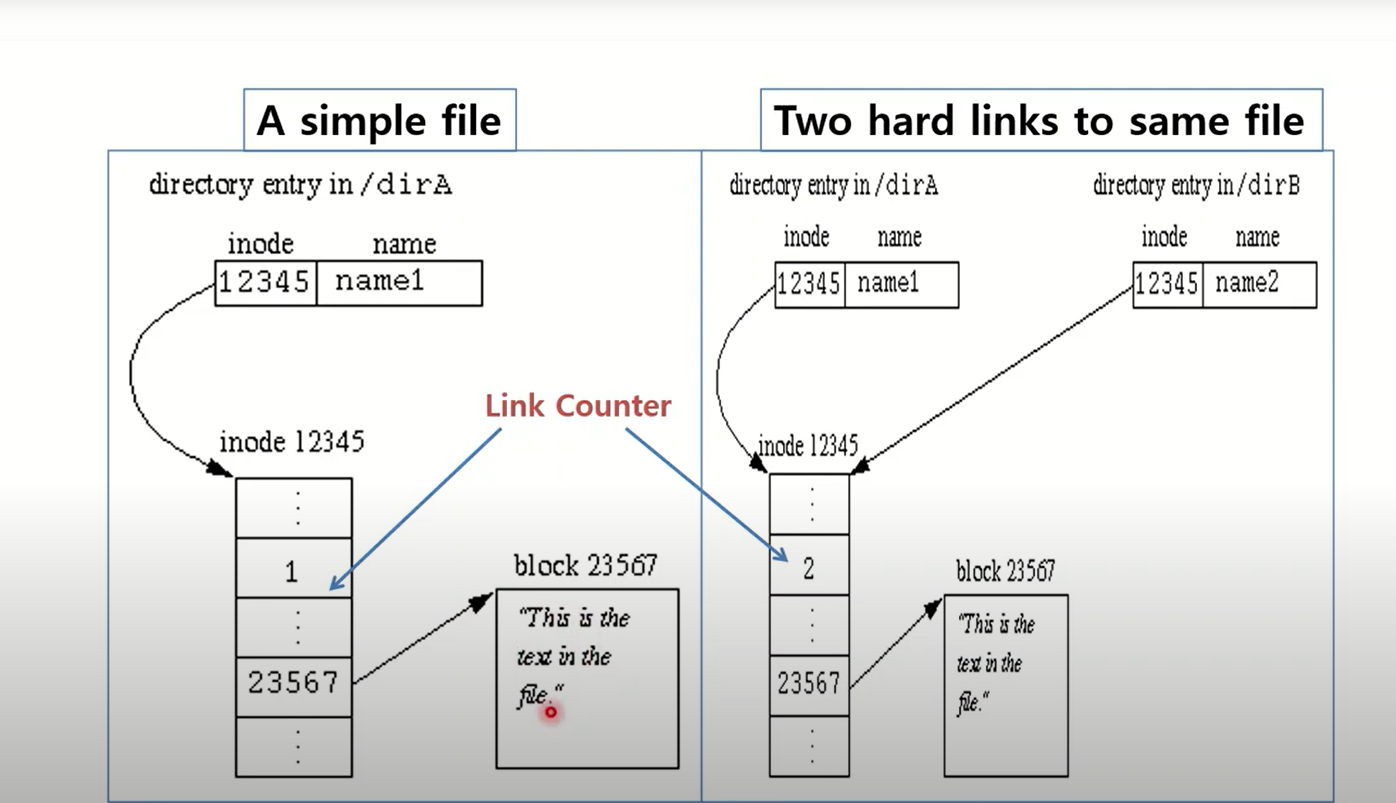
ln 명령어로 만들고자 할때도 파라미터 사용은 동일하다. 원본 하드링크 경로 순으로 입력한다.
하드링크를 새로 만들게 되면 inode관계가 어떻게 되는거냐하면 root밑에 dirA밑에 entry하나가 name1이라는게 있고 12345 라는 inode 숫자이름은 링크의 카운터다. 이 inode를 통해서 name1이라는 것에 컨텐츠 블럭이 따로 잇다. name1이라는 거에 하드링크를 하나 만들었다. name2라고 추가하면 dirB라는 디렉토리 엔트리가 추가되고 inode번호는 원본 inode번호와 같은 번호, 같은 inode를 가리키게된다. 블럭에서는 변화가 없고 linkcount만 하나 추가된다. 이런 상태가 되었으니 name2로 변경하면 파일블럭도 변경된다. 반영된다. hardlink라 하는것도 원본이다.
(inode로 같은지 확인해주면 된다.)
Symbolic link는 파일명과 inode사이에 간접적인 연관관계를 갖는것이다. symbolic link를 만들면 symbolic link라는 파일이 만들어지게 된다. 원본 파일이 포함된 특별한 파일이 만들어지게 된다. symbolic link 이 경로를 내가 access할려는 것을 symbolic link로 하게 되면 symbolic link의 inode를 보고 탐색하는데 그냥 일반 파일이 아니라 symbolic link라는 것을 알게 되면 원본 파일을 보고 탐색을 계속한다. OS가 계속 탐색을 하게 되는것이다. Symbolic link를 만들기 위해서는 ln -s옵션을 주게 되면 hard link가 아닌 symbolic link를 만들게 된다. link count값을 따로 유지하지 않는다. 하드링크는 조금더 강한 링크이기 때문에 inode에서 링크 카운트를 관리하는데 symbolic link는 따로 관리하지 않는다.
Symbolic link API
#include <unistd.h>
int symlink(const char* path1, const char* path2);int symlink라는 별도의 함수를 사용한다. 파라미터의 순서는 1. 원본 2. 새롭게 만들어지는 target 경로명이 된다.
ln -s를 써서 symbolic link를 만든다. symlink써서 만든다. 만약에 에러가 나면 -1이 리턴이 된다.
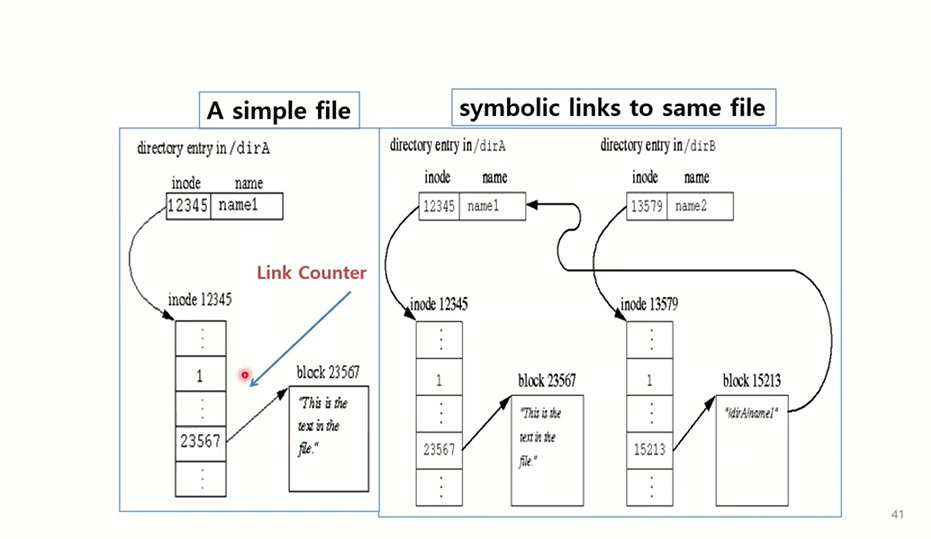
name2를 바꾸면 원본파일이 변경이 된다. symbolic link나 hardlink나 결국 같은 것을 가리킨다. 차이는 직접적 연결이나 간접적 연결이냐의 차이가 난다.
ln -s temp.c temp-sym.c
ls -i
우분투에서 보면 색깔도 다르다 --> 별도의 파일이 만들어지고 symbolic link는 표시를 화살표로 해준다.

temp.c라는 원본파일과 같은 이름 만들고 저장. 그리고 ls하면 아까랑 다른 temp.c가 만들어진다. inode보면 새로운걸 가리키게 된다. 근데 temp-sym.c와 temp.c는 또 간접적으로 연결되어있다.
'CS > 시스템 프로그래밍' 카테고리의 다른 글
| Times and Timers (0) | 2021.11.16 |
|---|---|
| UNIX Special Files (0) | 2021.11.03 |
| UNIX I/O (0) | 2021.10.15 |
| System Call 함수 [Fork() 함수, wait() 함수] (0) | 2021.10.04 |
| Process (0) | 2021.10.03 |