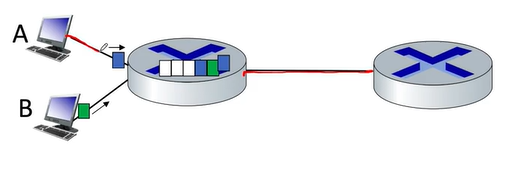
소켓을 들으면 일반적으로 전구의 소켓을 떠올릴 것이다. 그리고 컴퓨터에서 말하는 소켓은 전구의 소켓과 비슷하게 연결하는 통로라고 생각하면 된다. 사용자 즉, host가 2명이 있다고 생각해보자. Host가 서로 데이터를 주고 받는다고 생각해보자. 각각의 데이터는 단계별로 통과하여 데이터를 전달하게 되는데, 이 단계는 5가지가 있다. Application, Transport, Network, Link, Physical layer이다. 여기서 Application은 순수 software라고 생각하면 되고, Transport부터 Physical layer까지는 OS에 구현이 되어 있다. (Link layer와 Physical Layer는 NIC에도 있다.)
데이터 통신을 위해서는 먼저, 송신자의 Application에서 Socket이라는 문을 통하여 아래 layer들로 전달되고 수신자도 아래에서부터 데이터가 올라오고, Socket 문을 거쳐서 Application에 데이터가 도달하게 된다. 프로세스가 데이터를 보내거나 받기 위해서는 반드시 소켓을 열어 소켓에 데이터를 쓰거나 읽어야 한다.
Multiplexing / demultiplexing
Multiplexing과 demultiplexing은 transport layer에서 일어난다. 서로 반대되는 개념인데, multiplexing이 여러 데이터를 한 통로에 넣어서 섞어버리는 것이라면 demultiplexing은 한 통로에서 온 것을 여러 갈래 중 해당하는 곳으로 보내는 것을 의미한다. 우리가 인터넷 호스트에서 demultiplexing이라고 한다면 packet들이 도착했을때, packet들이 어떤 process로 가야되는지 보내는 것을 demultiplexing이라고 한다. Sender에서 multiplexing은 여러 개의 socket에서 오는 data를 handling하는 것을 의미한다. 즉, process마다 socket이 하나 있다고 생각하면 된다. physical layer에서 link, network layer까지는 같이 오다가 transport layer에서 어떤 socket으로 가는지 결정해준다.
어떻게 demultiplexing이 작동할까
Host는 IP layer(Network Layer)에서는 datagram을 전달받는다. 각각의 datagram은 source와 destination IP address를 가지고 있다. 각 datagram은 하나의 segment를 들고온다. 각 segment는 source와 destination의 port number를 가지고 있다. 그럼 host는 port number와 IP 주소를 이용해서 segment를 적절한 소켓에 데이터를 올려보내는 것이다.
TCP socket은 4가지 정보로 identify된다. Source의 IP주소, Soure의 port number, 목적지의 IP 주소, 목적지의 port number이다. 그럼 서버는 동시에 여러개의 TCP socket을 지원해야 된다. 각각의 socket은 각기 다른 socket으로 연결되는 것이다. socket은 port number에 binding되어야 하고, socket에 port number가 할당되어야만 socket의 기능을 할 수 있다. 위에서 볼 수 있듯이 16bit를 socket number로 사용할 수 있다. 이 중에서 0~1023은 잘 알려진 port로 임의로 사용할 수 없고(ex. 웹 서버:80포트) 임의로 사용할 수 있는 것은 49152~65535 번들이다.
하나의 프로세스는 같은 프로토콜, 같은 IP 주소, 같은 port number를 가지는 소켓을 여러 개 만들 수 있기 때문에, 하나의 프로세스는 하나의 port만으로도 여러 호스트에 있는 프로세스의 요청을 처리할 수 있다. (게임 서버에서 동시 접속자 수가 엄청나게 많을 수 있는 이유도 동일하다) 그래서 서버의 경우는 보통 하나의 포트만 할당받고, 하나의 포트로 여러 개의 소켓을 열게된다.
예시
위의 그림에서 모두 destination IP 주소는 B이고 port number는 80이다. 여기서 demultiplexing되어 다른 socket으로 들어간다.
Port number는 네트워크 상에서 통신하기 위해서 호스트 내부적으로 프로세스가 할당 받아야하는 고유한 숫자이다. 같은 Host 내에서 서로 다른 프로세스가 같은 Port number를 가질 수는 없다.
static이란 ‘고정된’이란 의미를 가지고 있다. Static 키워드를 사용해서 Static 변수와 Static 메소드를 만들 수 있는데 다른 말로 ‘정적 필드’와 ‘정적 메소드’ 라고도 하며, 합쳐서 정적 멤버라고 한다.
static field와 static method는 객체에 소속된 멤버가 아니라, 클래스에 고정된 멤버이다. 이 의미는 클래스 로더가 클래스를 로딩해서 메소드 메모리 영역에 적재할 때, 클래스 별로 관리된다. 따라서 클래스의 로딩이 끝나는 즉시 바로 사용할 수 있다.
Static member 선언
객체(인스턴스)로 생성할 것인지, static으로 생성할 것인지의 결정 기준은 공용으로 사용할 것이냐 아니냐로 결정하면 된다. 그냥 생성하면 java에서는 객체로 생성된다. static으로 생성하려면 static 키워드를 추가적으로 붙여서 공용으로 사용할 수 있다.
static field 사용 예시
먼저 Friend 클래스를 만들어 보았다. Friend에서는 static 변수인 numberOfFriends를 두었다. 이렇게 두면, Main에서 Friend의 static field를 어떻게 사용할 수 있는지 확인해보자.
package com.company;
public class Friend {
String name;
static int numberOfFriends;
Friend(String name){
this.name = name;
}
}
package com.company;
public class Main {
public static void main(String[] args) {
System.out.println(Friend.numberOfFriends);
}
}
Friend객체를 새로 생성하지 않고서 바로 numberOfFriends를 Friend 클래스에서 호출할 수 있다.
그럼 객체를 만들 때, 친구의 수를 한 명씩 늘리고, 이 변수를 공유할 수 있도록 해보자.
package com.company;
public class Friend {
String name;
static int numberOfFriends;
Friend(String name){
this.name = name;
numberOfFriends++;
}
}
////Main
package com.company;
public class Main {
public static void main(String[] args) {
Friend friend1 = new Friend("Jake");
Friend friend2 = new Friend("Heon");
System.out.println(Friend.numberOfFriends);
}
}
이렇게 하면 Friend의 numberOfFriend는 2가 출력되는 것을 확인할 수 있다.
우리가 별 생각없이 쓰던 Math.round()같은 함수도 static 함수이기때문에 사용할 수 있었던 것이다.
(Math 객체를 따로 만들지 않고 바로 Math.round()와 썼었다)
static 멤버의 특성
Static 키워드를 통해 생성된 정적멤버들은 Heap 영역이 아닌 Static 영역에 할당된다. Static 영역에 할당된 메모리는 모든 객체가 공유하여 하나의 멤버를 어디서든지 참조할 수 있는 장점을 가지지만 Garbage Collectior의 관리 영역 밖에 존재하기 때문에 Static영역에 있는 멤버들은 프로그램의 종료될때까지 메모리가 할당된 채로 존재하게 된다. 즉, 너무 남발하게 되면 문제가 생긴다.
클래스를 설계할 때, 멤버변수 중 모든 인스턴스에 공통적으로 사용해야하는 것에 static을 사용한다. : 객체를 생성하면 각 객체들은 서로 독립적이라서 서로 다른 값을 유지하기 때문에 공통적인 값을 필요로 하는 경우에 static을 붙인다.
static이 붙은 멤버변수는 인스턴스를 생성하지 않아도 사용할 수 있다. : static이 붙은 멤버 변수는 클래스가 메모리에 올라갈 때 이미 자동적으로 static 영역에 생성된다.
static이 붙은 메서드에서는 인스턴스 변수를 사용할 수 없다. : 인스턴스 변수는 인스턴스를 생성해야만 존재하기 때문에 static이 붙은 메서드를 호출할 때 인스턴스가 생성되어있음을 보장할 수 없기 때문에 static이 붙은 메서드에서 인스턴스 변수의 사용을 허용하지 않는다. (반대로 인스턴스 변수나 인스턴스 메서드에서는 static이 붙은 메서드를 사용할 수 있다.)
메서드 내에서 인스턴스 변수를 사용하지 않는다면, static을 붙이는 것을 고려한다. : 메서드의 작업내용중에서 인스턴스 변수를 필요로 한다면 static을 붙일 수 없다. 반대로 인스턴스 변수를 필요로 하지 않는다면 가능하면 static을 붙이는 것이 좋다. 메서드 호출시간도 짧아져서 효율이 높아진다. (static을 안붙인 메서드는 실행 시 호출되어야할 메서드를 찾는 과정이 추가적으로 필요하다.)
인스턴스 변수와 관계없거나, 클래스변수만을 사용하는 메서드들은 클래스메서드(static method)로 정의한다.
public URL(String url) throws MalformedURLException → 지원되지 않는 protocol이나 URL 문법에 맞지 않으면 MalformedURLException에 속한다
public URL(String protocol, String host, int port, String file) throws MalformedURLException
생성자는 생성된 URL이 유효한지 안한지 체크하지 않는다. 그래서 URL이 존재하지 않거나 존재하더라도 접속되지 않을 수도 있다.
URL syntax가 만족해야 하는 것은 일단 ‘:’ 가 있어야 한다. 세미콜론을 통해 schem이나 protocol을 구분한다. 뒤에 오는 것은 어떤지는 신경쓰지 않는다.
URL로 데이터를 얻는 방법
data를 얻는 함수를 알아보겠다
public InputStream openStream() throws IOException
제일 많이 사용되고 기본이 된다.
Client와 Server의 handshaking도 실행한다
읽어들일 수 있는 data에서 InputStream을 반환한다.
InputStream으로 읽는 data는 raw content이다. 즉, ASCII 텍스트 파일은 ASCII로 읽히고, image file은 binary image data로 읽힌다.
HTTP header나 protocol 관련 정보는 포함하지 않는다.
한계 : 너무 상위 레벨이라서 생기는 한계가 있다.
openStream()은 URL이 text를 가리키고 있다고 가정한다. 그러나 실제로 URL은 image나 sound, video같은 다른 타입도 가리킬 수 있다.
text이더라도 server에서의 encoding과 receiver에서의 encoding이 다를 수도 있다.
다른 OS이면 해석이 다를 수도 있다.
HTTP header도 encoding 정보가 있을 수 있는데 여기서는 위에 말한대로 HTTP header를 읽을 수 없다.
그래서 openConnection()이 필요하다.
// 인수로 url 아무거나 넣어서 테스트하면 된다.
public class SourceViewer {
public static void main(String[] args){
if(args.length > 0){
InputStream in = null;
try{
// Open the URL for reading
URL u = new URL(args[0]);
in = u.openStream();
// buffer the input to increase performance
in = new BufferedInputStream(in);
// chain the InputStream to a Reader
Reader r = new InputStreamReader(in);
int c;
while((c=r.read())!=-1){
System.out.print((char)c);
}
}catch (MalformedURLException ex){
System.err.println(args[0] + " is not a parseable URL");
}catch (IOException ex){
System.err.println(ex);
}finally {
if(in!=null){
try{
in.close();
}catch (IOException e){}
}
}
}
}
}
public URLConnection openConnection() throws IOException
반환 객체로부터 InputStream을 얻어야 할 수 있다
openStream보다 low level control이다.
openStream은 openConnection과 getContent()을 동시에 하는 것이다.
public Object getContent() throws IOException
어떤 type으로 data retrieve 할것인지 결정할 수 있다.
URL은 ASCII나 HTML file을 의미할 수 있다.
URL은 GIF나 JPEG같은 image를 의미할 수 있다. → java.awt.ImageProducer가 return된다.
header of data에 있는 Content type field를 본다.
import java.io.IOException;
import java.io.InputStream;
import java.net.*;
public class ContentGetter {
public static void main(String[] args){
try{
URL u = new URL("<https://www.oreilly.com>");
Object o = u.getContent();
InputStream r = (InputStream) o;
int c;
while((c=r.read())!=-1) System.out.print((char) c);
r.close();
System.out.println("I got a "+o.getClass().getName());
}catch (MalformedURLException ex){
System.err.println(args[0] +" is not a parseable URL");
}catch (IOException ex){
System.err.println();
}
}
}
public Object getContent(Class[] classes) throws IOException
: 인터넷은 전 세계에 걸쳐 파일 전송 등의 데이터 통신 서비스를 받을 수 있는 컴퓨터 네트워크 시스템을 의미한다. 그래서 만약 우리가 ‘인터넷을 사용한다’ 라고 말하는 것은 사업자가 만들어 놓은 네트워크 인프라를 사용하는 것이다. (여기서 사업자는 SK,KT 회사들을 의미한다.)
인터넷 망을 통해 데이터를 디지털 신호로 바꾸어 전달하고, 받은 디지털 신호를 데이터로 다시 바꾸면서 네트워크 통신을 하는 것이다. 이 때, 네트워크 통신을 위한 규칙, 즉 공통된 메뉴얼을 프로토콜이라고 한다.
network edge
network edge는 hosts들로 구성된다. hosts들은 사용자 또는 서버를 포함하고 기본적으로 단말들을 의미한다. server는 data center이다. 우리가 브라우저에 접속한다고 생각하면 서버에 데이터를 요청해서 데이터를 받아온다. 이렇게 끝단에 있는 것들을 network edge들이라고 생각하면 된다. 이 사이사이를 link들이 이어주는데, 이제 어떻게 보낼것인지 어디로 보낼것인지 이런것들을 처리해주는 부분이 network core부분이다.
network core
data를 보낼 때, data자체는 크기가 크니까 잘게 쪼개서 보낸다. 이 때 잘게 쪼갠 조각 하나하나를 패킷(packet)이라고 한다. 이 패킷들을 어떻게 전달할 것인지가 문제이다. network core들은 ISP쪽을 의미하고 core에 edge들이 달려있는것이다. ISP도 서로서로 연결이 되어있다. 즉, network core들은 router들의 interconnection이다.
network core의 2가지 key function은 무엇일까?
Forwarding(switching) : local action이다. 라우터에서 패킷을 받았는데, 패킷에는 목적지 주소가 써져 있다. 이 목적지로 가는 패킷은 몇 번 링크로 forwarding을 해야 하는지 forwarding table을 가지고 있다. 그래서 궁극적으로 패킷이 목적지에 도달할 수 있도록 하는 것이 forwarding이다.
Routing : routing은 global action이다. source에서 destination까지 어떤 경로를 취해야 하는지 패킷이 어떤 경로를 따라가야 하는지 체크하는 것이 라우팅이 된다. (라우팅 알고리즘도 여러 가지가 있다.)
packet-switching의 개념이 중요한데, 패킷 하나가 보내지면 store and forward라는 방식을 사용한다. 이 방식은 전체가 받아질때까지 버퍼에 store하고 다 받아진 다음에야 보낸다. 중요한 성능 측정중 하나가 packet transmission delay이다. host가 data packet을 보내는 경우를 생각해보자. packet의 길이가 Lbits라고 한고, 전송속도를 R이라고 가정하자. 그럼 packet transmission delay, 즉 L bit packet을 link로 보내는데 걸리는 시간은 L/R이 된다.
그런데 packet switching은 queueing이 발생할 수 밖에 없다. 왜냐하면 link를 공유하게 되는데 전송되어 빼내는 속도보다 들어오는 속도가 빠르면 congestion, 즉 queueing delay가 생긴다.
그럼 잃어버리는 data도 생길것이다. arrival rate > transmission rate일 때, 패킷이 버퍼에 쌓이는데 메모리 용량은 한계가 있다. 그럼 packet drop이 생긴다.
여기서 packet switching과 반대되는 개념인 circuit switching도 있다. end - end resource가 예약이 되는 개념이다. 그러니까 이 link를 독점적으로 사용하는 것이다. traffic이 없다고 해도 항상 비워져 있어야한다. 그래서 telephone network에서 많이 쓴다. 전화하는 중간에 전화해도 통화중이라고 알려주지 같이 통화할 수 있는건 아닌것처럼 말이다.
그럼 packet switching과 circuit switcing을 비교해보자. 만약에 link로 1Gb/s통과하고 각각의 사용자는 사용하면 100 Mb/s를 사용하고 10%확률로 사용한다고 가정하자. 그럼 circuit switching은 1Gb에서 100Mb를 나눈값이 10명밖에 사용을 못한다. 그런데 packet switching은 35명이 사용한다고 가정할 때 35명이 동시에 사용할 확률이 0.004밖에 안된다. 그래서 여러명이서도 사용할 수 있는 것이다.
그럼 packet switching이 무조건 우세일까? 그건 아니다. 성능을 보장해야 하는 경우는 circuit switching을 사용하게 된다.
pacekt switcing은 data loss가 있으므로 reliabel data transfer이나 congestion control이 필요하다.
Performance : loss, delay, throughput
인터넷은 기본적으로 packet switching이다. packet switching은 모든 resource를 공유하는 것이라고 위에서 설명하였다.
delay에는 4개의 요소가 있는데, 4가지 요소는 transmission delay, nodal processing delay, queueing delay, propagation delay이다.
nodal processing delay는 packet이 도착했을 때, packet에 bit error가 있는지 없는지 확인하고 output link를 결정하는 과정이다. nodal processing delay는 보통 microsec로 굉장히 짧다. 그래서 보통 하드웨어에서 구현이 되어 있다.
queuing delay : transmission 받으려고 기다리는 delay이다. router의 congestion level에 따라서 변화가 굉장히 심하게 있을 수 있다. 어떤 경우에는 queueing delay가 0이었다가 어떤 경우에는 굉장히 컸다가 굉장히 dynamic한 상황이다.( nodal processing delay같은 경우는 거의 변화가 없다. ) Queueing delay는 변화가 있기 때문에 여러가지 요소가 있다.
transmission delay : packet을 링크에 밀어넣는 속도이고, packet length가 Lbits이고, transmission rate이 R bps다 라고 하면 L/R초가 걸리게 되는 것이다.
propagation delay : bit는 전기신호인데 001 이런식으로 보내는데 전자기파, 빛의 속도 20만킬로미터 퍼 second가 되는데 physical link가 d미터였다고 하면 d/s가 걸리는 것이다. link가 아주 길지 아니면 굉장히 delay가 짧다.
이것들이 다 합쳐서 Packet delay가 된다.
packet arrival rate이 a라고 해보자. packet per second. packet length는 bits이다. a packet per second인데 하나의 packet이 Lbits니까 arrival rate이 aL bps가 된다. R은 transmission rate이다.
La/R → traffic intensity
그럼 여기서 의문이 생긴다. traffic intensity가 1보다 작다는 것은 queueing delay가 발생안한다는 뜻이 아닐까?
아니다. 여기서 arrival rate는 평균을 의미하기 때문에 이 경우에도 queueing delay가 발생할 수 있다.
Packet loss
congestion이 발생할때 버퍼링이 될 수 있는데 버퍼가 꽉찬 상태에서 추가로 들어오면은 loss가 발생한다. loss packet이 발생하면 재전송 mechanism이 있다. 그리고 throughput은 얼마나 통과했느냐 얼마나 data들이 통과했는냐를 나타내는것이 throughput이 된다. sender에서 receiver까지 bit가 전송되는 속도. instantaneous는 어떤 시점에서의 속도를 나타내는 것이다.
average는 긴 시간 간격이고 그 시간안에 전송된것.
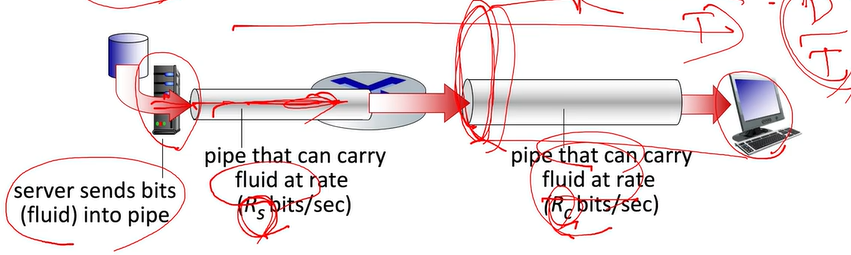
Rs가 Rc보다 작은 상황이라고 해보자. Rs속도가 안나오면 Rc가 아무리 높아도 사용안된다.
bottleneck problem. → 그럼 end to end 는 최대 Rs가 된다. (병목현상이라고 부른다.)
즉, 여러 곳에서 들어올 때 최소값이 end-end throughput이 되는 것이다.
TCP / IP 계층
Application Layer : 특정 서비스를 제공하기 위해 애플리케이션끼리 정보를 주고받을 수 있게 해준다. ( FTP, HTTP, SSH, Telnet, DNS, SMTP)
—> ex> 브라우저와 웹서버가 HTTP요청, 응답을 통해 통신하는 것
Transport Layer : 송신된 데이터를 수신측 애플리케이션에 확실하게 전달해 준다. 네트워크 통신을 하는 애플리케이션은 포트 번호를 사용하게 된다. Transport Layer는 port 번호를 사용해서 애플리케이션을 찾아주는 역할을 한다. TCP, UDP와 같은 프로토콜이 사용된다.
Internet Layer : 수신측까지 데이터를 전달하기 위해 사용된다. 송신측, 수신측 모두 IP 주소를 가지고 있다. IP주소를 바탕으로 정확한 목적지를 찾아갈 수 있게 해준다. IP, ARP같은 프로토콜이 사용된다.
Network Access Layer : 네트워크에 직접 연결된 기기 간의 데이터 전송을 도와준다. 여기서는 물리적 주소인 MAC주소를 사용한다. Ethernet, PPP, Token Ring과 같은 프로토콜을 사용한다.
그럼 우리가 www.google.com을 웹브라우저에 입력하면 무슨 일이 일어날까?
먼저 www.google.com을을 입력하면 google서버의 80포트로 HTTP Request를 보내는 것을 의미한다. 해당 요청을 인터넷을 통해 구글서버로 전달하기 위해 우리는 패킷을 만들어야 한다. 패킷에는 각 계층에 필요한 정보들이 담겨야 한다.
( 계층별로 HTTP, TCP, IP, Ethernet 프로토콜을 사용한다고 생각하자.)
Application Layer에는 Http Request가 들어간다.
Transport Layer에는 SP, DP. SP는 시작포트, DP는 도착포트. 시작포트번호는 내 컴퓨터에서 만든 소켓의 포트 번호라서 당연히 컴퓨터는 알고 있을 것이다. 목적지 포트 번호 또한 80으로 알고 있다.
(80은 웹서버의 well known 포트 번호이다)
IP header에는 SA와 DA. 시작 IP주소, 도착 IP주소. 시작 IP주소는 알고 있겠지만,(내pc니까) 목적지 ip주소는 모른다. www.google.com이라는 도메인 주소만 알고 있기때문에 DNS 프로토콜을 사용해서 IP주소를 알 수 있다.
브라우저는 OS에게 도메인에 대한 IP주소를 알고 싶다고 요청한다. 그럼 OS에서 DNS서버로 요청을 보내게 된다. 그럼 OS가 DNS 서버를 어떻게 알고 있을까? DNS서버 주소는 이미 컴퓨터에 등록이 되어 있다.
DNS또한 HTTP와 같은 애플리케이션 계층 프로토콜이다. 53번 포트를 사용한다. DNS도 HTTP Request와 비슷하게 도메인이 담긴 쿼리를 도메인 서버로 보낸다. 그럼 도메인 서버가 IP주소를 응답 해준다.
DNS는 Transport Layer에서 UDP라는 프로토콜을 사용한다. UDP는 TCP와는 다르게 헤더가 간단하다. 포트번호말고 다른게 없다. 그 이유는 UDP가 비연결지향형 프로토콜이기 때문이다.
Ethernet 프로토콜에 대한 헤더를 알아야하는데 아직 MAC주소를 모른다. MAC주소는 어떻게 알아와야할까? 이전까지는 목표인 구글 서버에 대한 정보가 필요했다. 그럼 MAC주소도 우리의 목적지인 구글 웹서버의 MAC주소가 필요할까? 아니다. 여기서필요한 MAC주소는 구글의 MAC주소 대신 물리적으로 연결된 우리집 공유기의 MAC주소가 필요하다. 이 공유기를 통해 다른 네트워크와 연결이 가능하니까 게이트웨이라고 부르기도 한다. 게이트웨이의 IP는 이미 알고 있다. ( netstat -rn 명령어를 통해 알 수 있음)
그럼 어떻게 IP주소로 MAC주소를 알 수 있을까? IP주소로 MAC주소를 알아내기 위해서 ARP 프로토콜을 사용한다. ARP 프로토콜을 IP주소를 MAC주소로 바꾸어주는 주소해석 프로토콜이다.
TCP 프로토콜은 데이터를 송신하기 전에 송신측과 수신측이 서로 연결되는 작업이 필요하다. 이러한 작업을 3 Way Handshaking이라고 부른다.
3way handshaking을 수행하기 위해서는 TCP header에 표시한 플래그들이 사용된다. 이러한 플래그들을 컨트롤 비트라고 부른다. SYN과 ACK 플래그가 사용된다.
클라이언트는 서버에게 접속을 요청하는 SYN 패킷을 보낸다. 서버는 SYN 요청을 받고, 클라이언트에게 요청을 수락한다는 ACK와 SYN플래그가 설정된 패킷을 보낸다.
클라이언트는 서버에게 다시 ACK를 보낸다. 이제부터 연결이 이루어지고 데이터가 오가게 된다. 이런 3가지 과정을 3way handshaking이라고 한다.
내가 사용하는 컴퓨터는 Private IP를 사용하고 있다. Private IP는 외부의 네트워크 환경에서 IP주소를 찾지 못한다. 그래서 공유기를 통해 나갈 때 public IP로 주소를 변환하여 나가는 작업이 필요하다.
이러한 작업을 NAT (Network Address Translation)이라고 한다.
우리집 공유기를 거치고 나서 구글 서버에 도착하기 위해서는 여러 라우터를 거쳐야 한다. 라우터는 네트워크와 네트워크를 연결해주는 역할을 한다. 라우터가 목적이 경로를 찾아 나가는 과정을 라우팅이라고 한다. 라우팅을 거쳐 구글 서버가 연결된 라우터까지 데이터가 도착을 하면, 패킷의 IP헤더에 기록된 구글 서버 IP주소를 통해 MAC주소를 얻어와야 한다. 이때 이전에 설명했던 ARP프로토콜을 사용한다.
이때 ARP는 라우터가 연결된 네트워크에 브로드캐스팅된다. 목적지 구글서버가 자신의 IP로 온 ARP 요청을 받고 MAC주소를 응답해준다. 이제 목적지 구글서버의 MAC주소를 알았으니 데이터가 물리적으로 전달될 수 있다. ARP로 IP주소를 통해 MAC주소를 얻고, 드디어 목적지 구글 서버에 데이터가 도착한다.
그럼 구글 서버에서 HTTP Request를 받고 응답을 돌려보낸다. '/'에 매핑된 GET요청을 처리해서 적절한 HTML을 응답해준다. 그리고, HTTP 요청과 응답과정이 끝나면 연결을 종료해야 한다. 여기서도 TCP 컨트롤 비트가 사용된다. 이 단계에서는 ACK, FIN플래그가 사용된다.
클라이언트가 서버로 연결을 종료하겠다는 FIN 플래그를 전송한다. 서버는 클라이언트에게 ACK 메시지를 보내고 자신의 통신이 끝날 때까지 기다린다. 서버가 통신이 끝나면 클라이언트로 FIN을 보낸다. 클라이언트는 확인했다는 의미로 서버에게 ACK를 보낸다. 그럼 연결종료가 완료된다. 총 4단계이고 이걸 4way handshaking이라고 한다.
여기서 서버가 FIN을 보내는 과정에서 한가지 문제가 발생할 수 있다. 서버가 FIN을 보내기 전에 보냈던 데이터가 FIN 보다 늦게 도착할 경우이다. 서버로부터 FIN을 수신했다고 클라이언트가 바로 연결된 소켓을 닫아버리면 FIN을 보내기 전에 보낸 패킷은 영영 클라이언트가 받을 수 없게 된다. 그래서 클라이언트는 서버로부터 FIN요청을 받더라도 일정시간동안 소켓을 닫지 않고, 혹시나 아직 도착하지 않은 잉여 패킷을 기다린다. 이렇게 4way handshaking이 완료되어도, 소켓을 닫지않고 잉여패킷을 기다리는 상태를 TIME_WAIT이라고 한다.
오늘 WIT 동아리에서 프로젝트 발표를 진행할 때, 프로젝트 기간이 남을 경우 AWS S3로 배포한다는 이야기가 나와서, 매번 배포할 때 사용한다는 것만 알고 자세히 어떤 건지 알기 위해서 찾아보았다.
Amazon S3란?
Amazon Simple Storage Service의 약자로 파일 서버의 역할을 하는 서비스라고 생각하면 된다.
(어떠한 정보(파일)를 저장하는 서비스)
정보를 서버를 구축해서 저장할 수도 있겠지만 S3를 쓰면 많은 것을 신경쓰지 않고 할 수 있다.
일반적인 파일 서버는 트래픽이 증가함에 따라서 장비를 증설하는 작업을 해야 하는데, S3는 이걸 대신해 준다.
또한 파일에 대한 접근 권한을 지정할 수 있어서 서비스를 호스팅 용도로 사용하는 것을 방지할 수 있다.
호스팅 : 서버 컴퓨터의 전체 또는 일정 공간을 이용할 수 있도록 임대해 주는 서비스. 사용자가 직접 서버를 구입하고 운영할 필요 없이 호스팅 업체가 미리 준비해 놓은 서버를 빌려 사용하는 형식이다. 웹 호스팅, 서버 호스팅, 메일 호스팅 등 다양하다.
는 특정 비즈니스, 조직 및 규정 준수 요구 사항에 맞게 데이터에 대한 엑세스를 최적화, 구조화 및 구성할 수 있는 관리 기능을 제공하는 것으로 온라인 스토리지 서비스이다.
사용하는 이유
일단 이것을 사용하는 이유는 저장 용량이 무한대이고 파일 저장에 최적화되어있고, 용량을 추가하거나 성능을 높이는 작업이 필요없다.
Auto Scaling이나 Load Balancing에 신경쓰지 않아도 된다.
정적 웹페이지는 S3를 이용하면 성능도 높이고 비용도 절감된다. 동적 웹페이지는 EC2라는 것을 사용하면 성능도 높이고 비용도 절감한다.
S3 자체로 정적 웹서비스가 가능하다.
예를 들어 웹사이트를 만들 때 사용자들이 파일을 전송하면 그 파일을 S3에 저장하고 S3에서 다운받아서 다른 사용자에게 제공한다.
사용되는 용어들
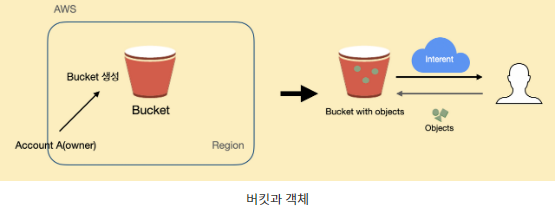
객체 : 데이터 하나하나를 의미한다.
버킷 : 객체가 파일이라면 연관된 객체들을 그룹핑한 최상위 디렉토리를 버킷이라고 한다. 버킷에 포함된 모든 객체에 대해서 일괄적으로 인증과 접속 제한을 걸 수 있다.
객체 스토리지 : S3의 가장 큰 특성으로 높은 내구성과 가용성을 제공한다. 하나의 단위 객체가 업로드되면 자동으로 내부의 여러 위치에 복제본을 생성한다. S3객체 스토리지도 동일 Region내에 여러 AZ에 걸쳐 복제본을 생성한다. (한 객체에 손상이 발생해도 손상되지 않은 복제본이 있어서 내구성 상승)
버전관리 : 객체들의 변화를 저장한다. (Git 생각하면 된다.)
RRS : Reduced Redundancy Storage. 일반 S3객체에 비해서 데이터가 손실될 확률이 높은 형태의 저장 방식이다.
Glacier : 매우 저렴한 가격으로 데이터를 저장할 수 있는 아마존의 스토리지 서비스
장기적으로 데이터 보관을 위한 용도면 Glacier가 적합하고, 장기 스토리지나 백업 및 복구 파일용은 Standard-IA가 적합하다.