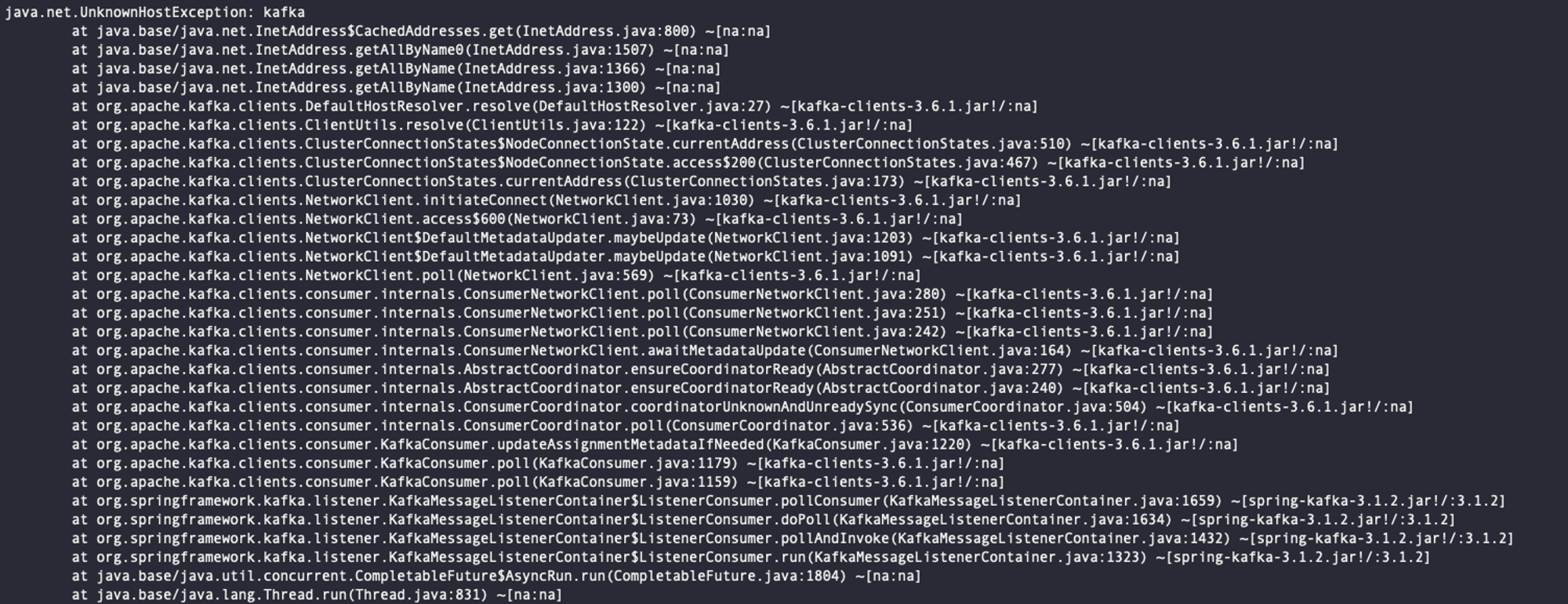
[오류 상황]
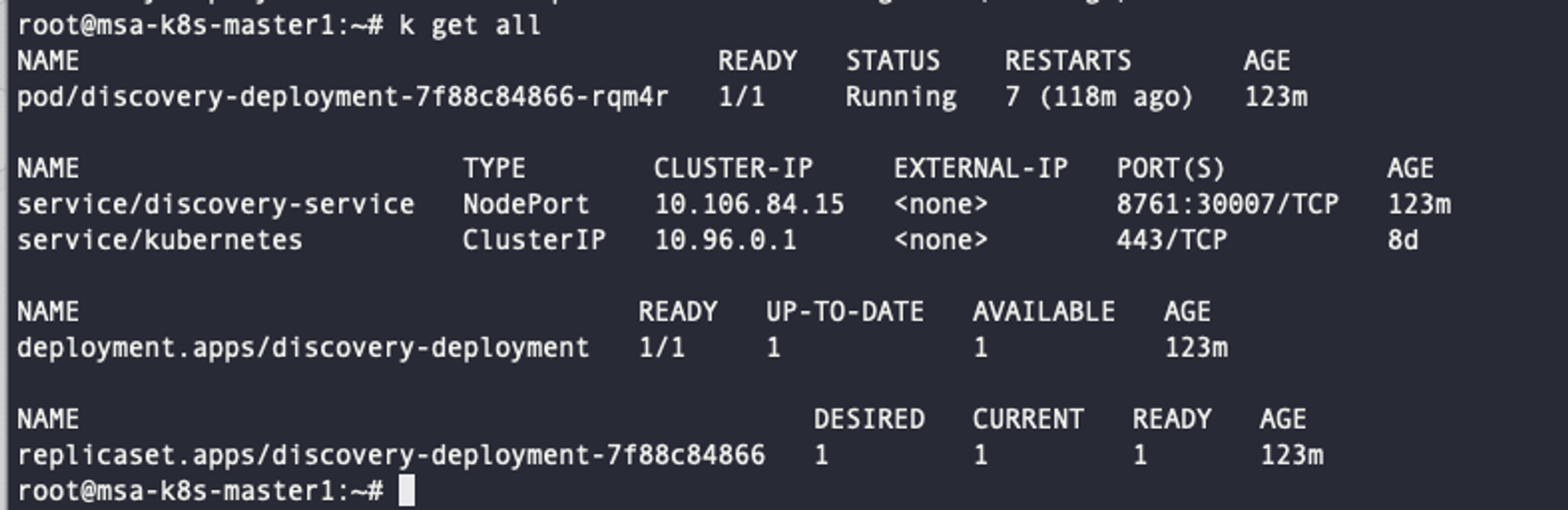
기존에 서비스를 EC2에서 사용하다가 자원에 따른 비용이 너무 비싸져서 NCloud로 옮기면서 Kafka의 브로커를 3개에서 1개로 축소하였습니다. 해당 변경사항을 반영하기 위해 각 topic에 대한 replicationFactor도 모두 1로 바꾸었는데 계속해서 아래와 같은 replicationFactor가 3으로 설정되어있다는 오류가 발생하였습니다.
[2024-07-18 06:00:55,185] INFO [Admin Manager on Broker 1]: Error processing create topic request CreatableTopic(name='__transaction_state', numPartitions=50, replicationFactor=3, assignments=[], configs=[CreateableTopicConfig(name='compression.type', value='uncompressed'), CreateableTopicConfig(name='cleanup.policy', value='compact'), CreateableTopicConfig(name='min.insync.replicas', value='2'), CreateableTopicConfig(name='segment.bytes', value='104857600'), CreateableTopicConfig(name='unclean.leader.election.enable', value='false')]) (kafka.server.ZkAdminManager) org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 3 larger than available brokers: 1.
[원인 및 해결]
Kafka가 원래 JVM 기반 자바 애플리케이션이라 자바와 호환성이 좋은데, Spring @Transactional 을 사용해서 카프카 메시지 produce를 하게 되면 이 과정 자체를 트랜잭션 처리를 하게 됩니다. (저도 유저 생성 시 Kafka 메시지를 보내기 위해 DB 저장 로직과 Kafka 전송 로직을 트랜잭션 처리하였습니다)
이때 카프카 내부적으로 사용하는 토픽이 _transaction_state 이고, 이 토픽의 기본 replication_factor가 3입니다.
Kafka의 _transaction_state 토픽은 트랜잭션 기반 메시징 시스템에서 중요한 역할을 합니다. 이 토픽은 Kafka 브로커가 트랜잭션의 상태를 관리하고 유지하는 데 사용됩니다.
(default로 3으로 설정되어있기 때문에 계속해서 오류가 생겼던 것입니다)
_transaction_state 가 하는 역할
Kafka의 트랜잭션 기능을 이해하려면 _transaction_state 토픽의 역할과 작동 방식을 이해하는 것이 중요합니다.
Kafka 트랜잭션 개요
Kafka 트랜잭션은 메시지의 일관성과 원자성을 보장합니다. 이를 통해 메시지 생산자와 소비자가 특정 작업을 완전히 완료하거나 전혀 완료하지 않는 트랜잭션을 수행할 수 있습니다.
Kafka의 _transaction_state 토픽은 트랜잭션 상태를 관리하고 유지하는 핵심 구성 요소입니다. 이 토픽은 트랜잭션의 상태를 저장하고, 복구 과정을 지원하며, 트랜잭션의 일관성을 보장합니다. 이를 통해 Kafka는 높은 신뢰성과 일관성을 요구하는 애플리케이션에서도 안전하게 사용할 수 있습니다.
_transaction_state 토픽의 역할
- 트랜잭션 상태 저장: _transaction_state 토픽은 각 트랜잭션의 상태 정보를 저장합니다. 여기서 의미하는 상태정보는 트랜잭션의 시작, 커밋, 중단 등의 상태가 포함됩니다. 이 정보는 Kafka 브로커가 트랜잭션을 추적하고 관리할 수 있도록 합니다.
- 복구: 브로커가 실패하거나 재시작될 때, _transaction_state 토픽의 데이터를 사용하여 트랜잭션 상태를 복구합니다. 이를 통해 시스템은 일관된 상태를 유지할 수 있습니다.
- 코디네이터: Kafka는 트랜잭션 코디네이터를 사용하여 트랜잭션을 관리합니다. 코디네이터는 _transaction_state 토픽을 사용하여 트랜잭션의 현재 상태를 기록하고, 각 트랜잭션의 상태를 유지합니다. 이는 트랜잭션의 커밋 또는 중단을 처리할 때 중요합니다.
트랜잭션 상태 전이
트랜잭션은 여러 상태를 거치며 전이합니다.
- Empty: 초기 상태로, 트랜잭션이 아직 시작되지 않은 상태.
- Ongoing: 트랜잭션이 시작되고, 메시지가 생산되고 있는 상태.
- PrepareCommit: 트랜잭션이 커밋 준비 중인 상태.
- PrepareAbort: 트랜잭션이 중단 준비 중인 상태.
- CompleteCommit: 트랜잭션이 성공적으로 커밋된 상태.
- CompleteAbort: 트랜잭션이 성공적으로 중단된 상태.
[시나리오]
- 트랜잭션 시작:
- 프로듀서가 트랜잭션을 시작합니다.
- 트랜잭션 코디네이터가 _transaction_state 토픽에 트랜잭션 ID와 함께 상태를 기록합니다.
- 메시지 생산:
- 프로듀서는 여러 메시지를 생성합니다.
- 각 메시지는 트랜잭션 ID와 함께 기록됩니다.
- 트랜잭션 커밋:
- 프로듀서가 커밋을 요청합니다.
- 트랜잭션 코디네이터가 _transaction_state 토픽에 상태를 PrepareCommit으로 업데이트합니다.
- 모든 메시지가 성공적으로 기록되면 상태를 CompleteCommit으로 변경합니다.
- 트랜잭션 중단:
- 프로듀서가 중단을 요청하거나 오류가 발생합니다.
- 트랜잭션 코디네이터가 상태를 PrepareAbort로 업데이트합니다.
- 모든 메시지가 무효화되면 상태를 CompleteAbort으로 변경합니다.
'프로젝트' 카테고리의 다른 글
| Kafka, Zookeeper Docker-Compose로 Ubuntu 서버 배포 (0) | 2024.03.15 |
|---|---|
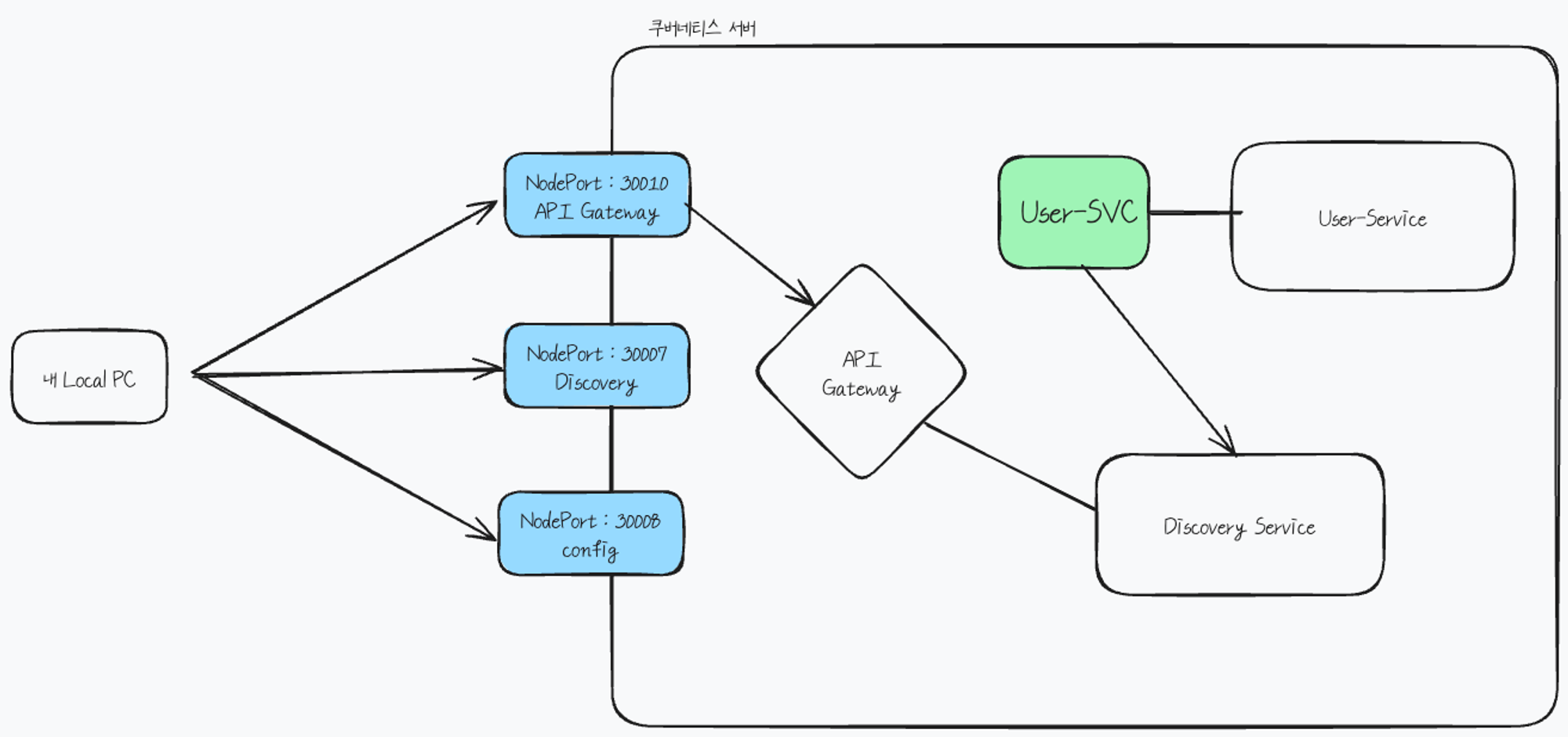
| 쿠버네티스 Discovery, API Gateway, Microservice 연동 (0) | 2024.03.14 |
| 마이크로서비스 프라이빗 클라우드에 배포하기 (0) | 2024.03.12 |
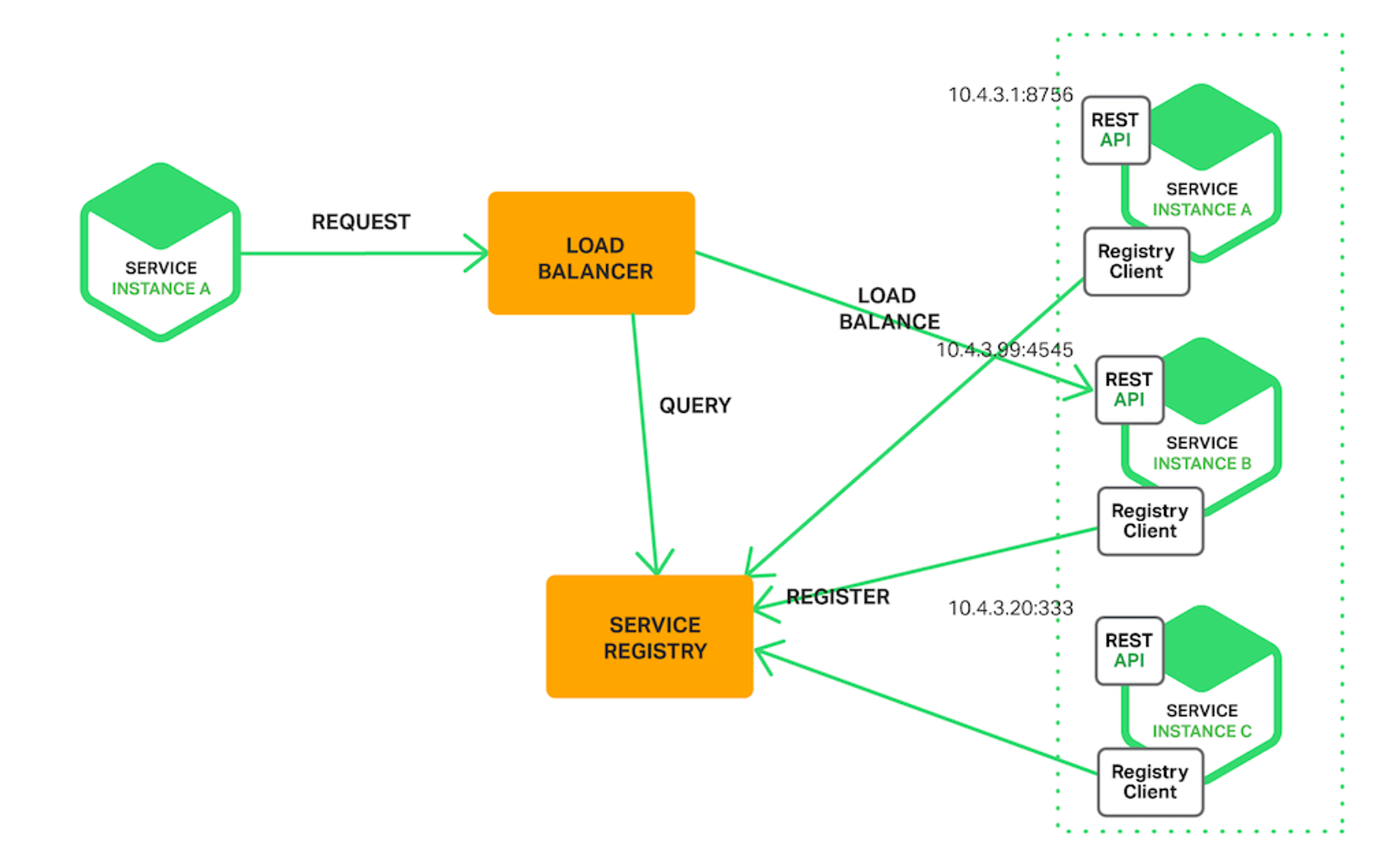
| Service Discovery (0) | 2024.03.05 |