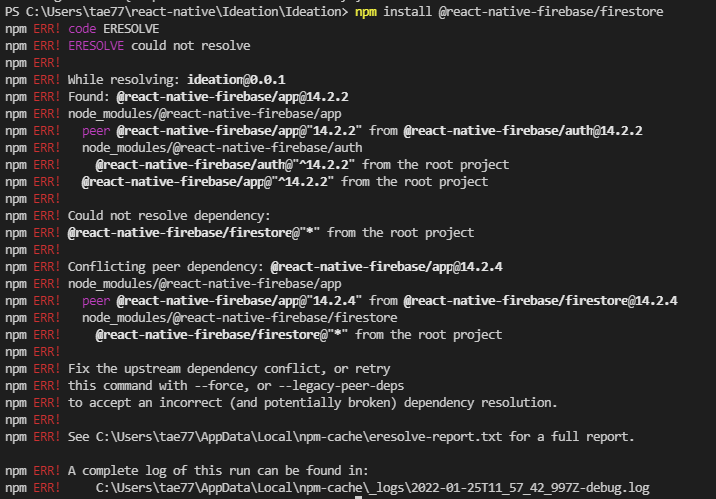
운영체제의 필요성과 목적
- 한정된 자원(limited source)과 사용자 사이의 경쟁을 조율하기 위한 운영자(운영체제)의 정책(운영체제가 수행하는 알고리즘)이 필요하다
- 컴퓨터에서의 자원과 경쟁 : 일반적으로 하드웨어 자원을 사용하고자하는 프로세스가 자원의 한도를 넘어간다.
-> 컴퓨터 속에서는 항상 여러 프로그램이 한정된 자원을 서로 독차지하려고 경쟁
- 가장 적합한 알고리즘을 수행하는 것이 중요하다 -> 적합한 알고리즘이란 어떤 것을 갖춘 것일까?
- 효율성(efficiency)과 편의성(convenience)을 갖춘 알고리즘(ex> 스케쥴링 알고리즘)
- 효율성 : 하드웨어를 얼마만큼 쉬지않고 사용하게 했는지에 관한 지표(프로세스 여러개 돌리는 경우)
- 편의성 : 사용자가 얼마만큼 불편함없이 사용할 수 있는지에 관한 지표(프로세스 하나만 돌리는 경우)
- 편의성을 높이려면 프로그램 하나가 하드웨어를 독점해서 사용하면 제일 극대화되는데 이렇게 되면 효율성이 매우 떨어진다는 점.
- 효율성을 높이려면 동시에 여러개를 실행시키면 되는데 이렇게 되면 편의성이 떨어진다.
- 따라서 효율성과 편의성 최적점 유지를 위해 운영체제가 필요하다
- 일관성 : 다양한 입출력 장치의 운영 및 제어의 일관성. 디바이스 드라이브를 표준에 맞도록 개발할것을 요구. 운영체제는 이를 토대로 장치 운영.
- 운영체제의 목적 : 편의성(사용자 관점) + 효율성(자원 활용) + 일관성(다양한 입출력 장치의 운영 및 제어)

초기 시스템
- 프로그램을 기계어로 작성 : 한줄 한줄을 카드 천공기에 펀칭해서 기록 (예를 들어 100줄-> 100장 필요)
- 자기테이프나 카드천공기로 카드에 기록
- 이렇게 기록해서 프로그래머가 Sign Up Sheet 원하는 시간을 예약해서 시간이 되면 카드덱에 자신이 펀치카드 묶음을 적재하고 컴퓨터가 읽게함
- 콘솔을 이용해서 프로그램 수행/디버깅. 라이브러리도 카드덱 형태
- 자기 시간이 되면 자기 혼자 컴퓨터 독점 -> Sign Up Sheet에 비는 시간 생기니까 효율성이 떨어진다
- Tape나 Punch-Card로 프로그램 적재하니까 준비 시간 과다
- 편의성은 좋은데 효율성이 떨어짐 -> 하드웨어가 비쌀 시기라 효율성 높이는데 주력했음
초기 일괄처리 시스템
- 아이디어 : 주컴퓨터(계속 작업)와 위성 컴퓨터(프로그램 적재, 결과물 출력) 분리
- but> operation에 대한 의존도가 높아서 다음 단계인 일괄처리 시스템으로 발전
- 운영자(operator)를 고용하여 사용자의 직업을 전문적으로 대행
- 사용자들이 요구하는 비슷한 작업들을 함께 묶어서 배치(batch)로 처리
- 배치가 적당한 규모가 되면 카드리더기에 적재하여 자기 테이프로 저장함
- 그러면 위성컴퓨터에서 떼어서 주컴퓨터로 탑재시켜줌(오프라인) -> 주컴퓨터는 자기테이프를 읽어서 그 안의 프로그램을 수행시킴
- 그러는동안 operator하는 위성 컴퓨터 이용해서 다음 배치를 자기테이프에 기록하는 작업을 한다.
- 입력은 이렇게 진행하고 출력도 마찬가지이다.
- 배치는 별도의 오프라인 카드리더나 테이프에 수록되고, 처리 결과도 별도의 오프라인 테이프를 통해 프린터로 출력됨
-> 주컴퓨터는 operator가 자기테이프를 걸어주기만 하면 쉬지않고 작업할 수 있다. (초기 시스템의 효율성 크게 개선)
-> but> 배치는 operator가 하기때문에 operator는 사람이기 때문에 완벽하지 않다.

일괄처리시스템

- 초기 일괄처리 시스템에서 operator를 자동화시키는데 목적을 둠.
- 이를 위해 고안된 것이 1. 채널 2. 버퍼 3. 인터럽트
- operator의 작업을 없애려면 카드리더기나 카드덱(또는 프린터) 입출력장치가 주컴퓨터와 직접적으로 인터페이스 되어야 하지 않겠냐?
채널 : operator가 프로그램과 데이터를 자기 테이프에 넣어서 주컴퓨터에게 수동으로 장착시키는 작업을 자동화 한것이 채널이다.
- 입출력장치가 CPU에 간섭없이 독립적으로 메모리의 특정부분에 직접 자료를 전송하도록 해주는 회로
- 이를 위해 명령어, 레지스터, 제어회로, 제어장치 로 이루어져 있다
- 채널에 의해서 CPU와 입출력장치가 병렬적 수행이 가능하게 되었다
=> CPU 간섭없이 입출력장치가 버퍼로가는 메모리 상의 일정 부분을 접근하도록 해주었다.
- but> CPU와 채널간의 전혀 간섭이 없을 수는 없다. CPU도 버퍼접근하고 채널도 버퍼접근하기 때문
(CPU와 함께 메모리를 공유)
즉, 메모리를 사이에 두고 CPU와 입출력장치가 서로 경쟁을 벌일 수 있다 (-> 사이클스틸링이라는 것으로 해결)
- CPU로부터 명령을 받아 CPU와 독립적으로 입출력 실행(단, 메모리 사이클 경쟁 제어 필요 -> DMA)
- DMA : 주변장치들이 메모리에 직접 접근하여 읽거나 쓸 수 있도록 하는 기능(CPU의 개입없이)
--> CPU가 해야할 주변장치와의 데이터 전송을 대신 해줘서 CPU 효율을 늘릴 수 있다
버퍼 : 채널이 입출력을 위해서 사용하는 메모리 상의 약속된 장소이자 CPU가 입출력 정보를 접근하는 장소이다.
- 버퍼가 있기 때문에 채널과 CPU가 서로 어긋나지 않고 자료를 공유하면서도 서로 간섭없이 각자의 역할을 수행
(CPU와 채널 입출력의 병렬 수행을 위하여 데이터 버퍼를 사용)
- 연산하는 동안 읽거나, 쓰는 것이 가능하게 되어 입출력 대기시간을 없앰
인터럽트 : 채널의 입출력과 CPU의 작업이 전혀 상관없이 작동하지는 않는다
- 채널을 통한 입출력은 CPU의 명령을 받아 실행해야 한다
- CPU는 입출력 명령이 끝날때까지 자신의 작업을 하더라도 입출력이 끝났는지는 통보받을 수 있어야 자료공유가 원할해진다 -> 이를 위해 인터럽트가 필요하다.
- 그럼 CPU는 인터럽트를 받으면 어떤 작업을 수행해야 할까? -> 해당 인터럽트에 대한 조치를 취하는데 입출력장치의 종류에 따라 매우 다양하다. -> 조치 또한 프로그램으로 만들어져서 메모리 특정부분에 탑재 되어야 했다 (ISR)
- 인터럽트는 사용자 프로그램이 아니라 하드웨어에 의하여 자동으로 메모리 특정 부분에 있는 함수(ISR, Interrupt Service Routine)를 호출하는 개념이다.
- 입출력의 완료와 예외동작 처리( ex> 파일종료, 테이프 끝, 패리티 오류 등)도 ISR로 프로그래밍 되어 있다.
- 채널을 통한 입출력 버퍼링을 CPU와는 독립적으로 수행토록 하는 핵심 수단
- cf> 트랩 : 인터럽트와 유사한데 부동소수점 연산 언더플로우, 오버플로우, 소프트웨어 인터럽트(소프트웨어적 오류)
트랩은 커널공간과 사용자공간을 나누어서 접근할 수 있는 권한설정에서 매우 중요한 역할을 한다.
-> CPU는 CPU나름 입출력장치는 입출력장치 나름대로 데이터를 출력하고 메모리 어느 곳에 데이터를 얹어놓는데 이곳이 버퍼이다. 양쪽이 분리되어 동작하고 서로 소통은 CPU를 통해 진행한다.
- 문제는 주컴퓨터 CPU가 부하가 걸린다(operator가 있을땐 나눌 수 있었는데 operator를 없애다 보니까 CPU가 과부하)
-> 해결 : 입출력장치와 CPU가 각자의 간섭없이 작업을 하도록 하고, 그동안 입출력장치가 컴퓨터 메모리상의 약속된 장소를 직접 접근하면서 입출력을 끝내도록 하고, 그 작업이 끝나면 CPU에 알리도록 해서 CPU가 다음 입출력 작업을 지시하도록 한다.
일괄처리시스템에서 모니터의 태동 : operator 자동화를 위해서는 메모리에 상주하는 프로그램이 필요하다
-> operator 대신 프로그램이 메모리에 올라가 있어야 되기 때문( ex> ISR, 적재기, JOB Sequencer, 제어카드 번역기)
상주모니터(Resident Monitor)
- 컴퓨터가 시동되는 시점부터 메모리에 탑재되어서 영구적으로 상주해야되는 것들
- 인터럽트 처리기 또는 입출력 관리자를 메모리에 영구적으로 상주시켜야 할 필요성 대두
- 작업 제어 명령어, 적재기, 작업 순서 제어기를 상주시켜 컴퓨터의 운영을 좀더 자동화 시킴
보호 이슈 >>
- 모니터가 메모리에 상주하는데 메모리에는 모니터도 있지만 채널을 통해서 버퍼에 들어오는 것이 프로그램이 탑재되어 들어올 수도 있다.
-> 다른 프로그램이 메모리 한 부분에 위치하게 되어서 CPU에 의해서 수행될 수도 있다. (ex> 사용자 프로그램들)
-> 이 프로그램을 수행하다가 모니터의 영역을 침범하는 경우가 생긴다 (즉, 덮어쓰는 경우가 생겨서 상주 모니터 보호의 필요성 대두된다)
특히 입출력할 때 자주 발생해서 이를 방지하기 위해 모든 사용자 프로그램은 입출력을 직접 하지 않고 반드시 모니터가 제공하는 입출력 함수를 호출해서 입출력하도록 했다 (-> 시스템 콜의 태동) ex> fork() 함수
(시스템 콜 : 커널 내의 함수를 응용 프로그램이 불러 쓰는 것)
-> 미리 작성된 테이블에 기록된 메모리 접근 허용치(사용자 프로그램이 접근할 수 있는 메모리 영역 허용치) 참조하여 각 연산 수행 시 메모리 접근 범위를 제한한다.
일괄처리시스템의 장점
- 초기 일괄처리 시스템에 비하여 효율성 개선됨(효율성 높이는데 큰역할)
- 하나의 작업이 CPU를 독점하므로 해당 작업으로 볼 때는 처리 속도가 가장 빠르다 (프로그램이 자원 독점)
- 사용자와의 대화가 필요하지 않은 CPU-bound 응용 프로그램 수행에 적합하다 (수치 계산, 대용량 데이터 처리 등)
단점
- 사용자와의 대화가 필요한 요구들이 많을때(ex> 편집기 ) 이것을 수행하기에는 부족하다
- 일괄 처리 시스템은 한 작업, 한 작업을 순차적으로 처리 -> 한 프로그램이 입출력을 위해 소모한 시간은 다음 프로그램에게는 기다리는 시간(즉, 전체 처리량 저하)
--> 그렇다면 여러 프로그램을 동시에 실행시키면??
다중 프로그래밍(Multiprogramming)
다중 프로그래밍은 일괄처리시스템과 달리 프로그램을 번갈아 수행한다
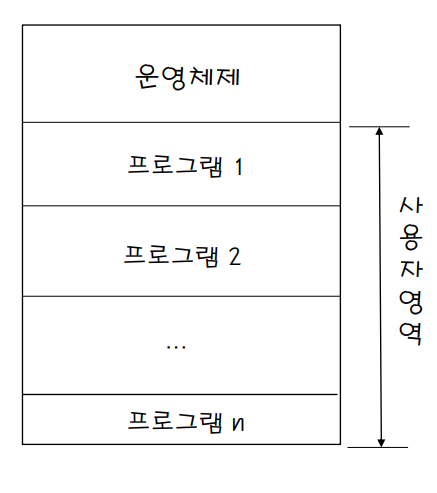
- 프로그램을 수행하다보면 어느 순간 입출력이 일어남(키보드 입력을 기다리거나 출력이 끝나기를 기다리는 상태에 도달)
-> 입력이 들어오기까지 마냥 기다리는 것이 아니라 입력이 들어오면 interrupt를 걸도록 해놓고 그 사이 다른 프로그램 선택해 수행
(이걸 모든 프로그램에 적용하면 번갈아가며 수행시킬 수 있게 된다)
- 한 시점에 여러 프로그램을 사용자 영역에 탑재
-- 시스템에 들어오는 모든 작업은 일단 작업 풀(디스크 사용)에 적재됨
--작업풀 내의 작업은 운영체제의 정책에 따라 선택되어 메모리에 탑재
- 탑재된 작업 중 하나를 선택하여 실행한다
- 한 프로그램이 입출력을 하는 동안 다른 프로그램을 선정하여 CPU가 실행한다(이것이 스케쥴링, 어떤것 선정이 좋을지 정책 필요)
- 스케쥴링이 언제 일어나냐 -> 다중 프로그래밍인 경우 수행중이던 프로그램에서 입출력이 일어날 경우에만 스케쥴링이 일어난다.
(- 시분할 시스템에서도 스케쥴링 일어나는데 차이 구분하면??)
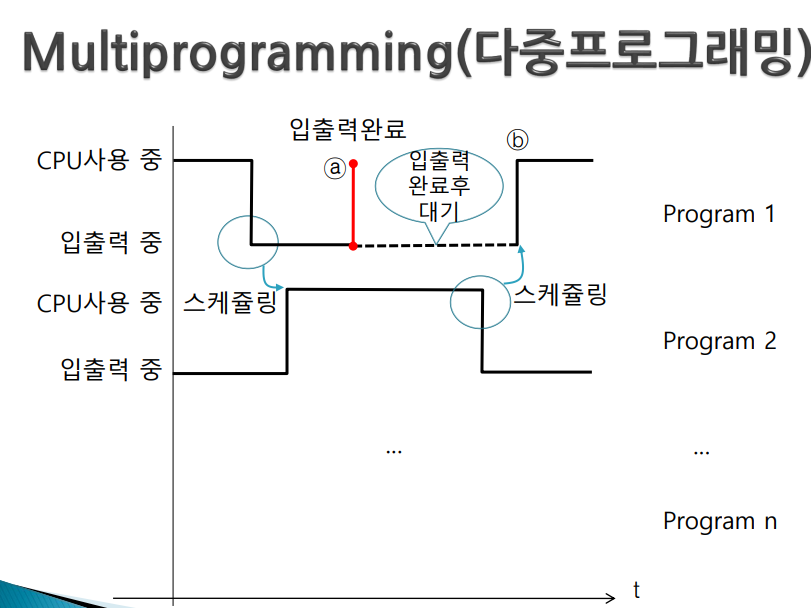
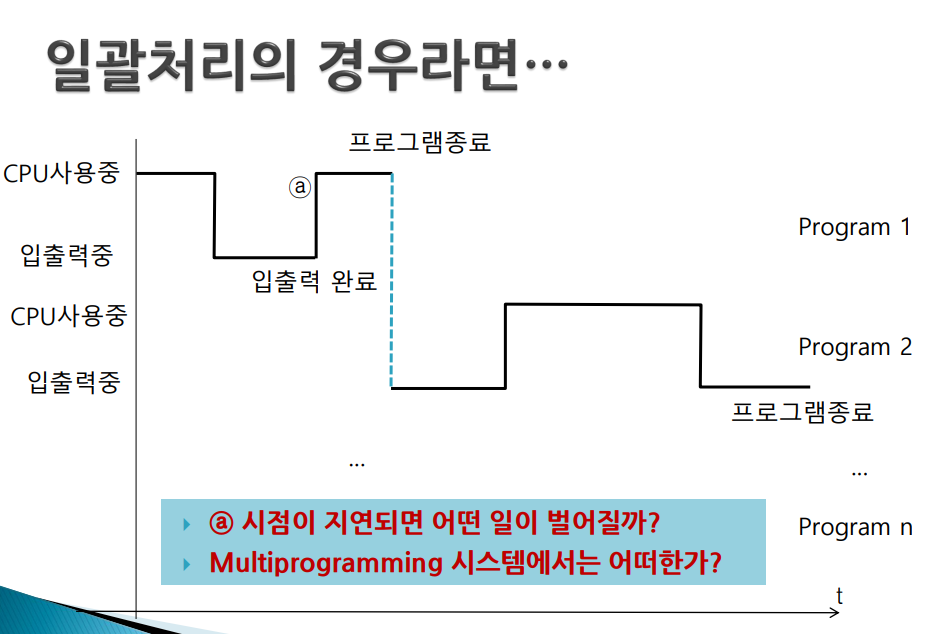
- 만약 program2에 문제가 있어 무한 loop 돈다(program1은 cpu 받기를 기다리고 있다) -> 스케쥴링은 입출력 변할때만 이루어지니까 program2가 무한루프를 돌면 입출력을 하는 순간은 오지 않는다. 즉, 입출력 요구하는 상황이 벌어지지 않는다 -> 스케쥴링도 일어나지 않는다 -> program1 영원히 대기
- 그래서 다중 프로그래밍인 경우 프로그램 간섭이 일어날 수 있다
1. 스케쥴링은 입출력이 일어났을때만 된다 2. 프로그램 간의 간섭이 일어날 수 있다
-> 대부분 프로그램의 실행 시간에서 CPU의 사용 시간은 극히 일부분이고 나머지는 입출력 시간이다.
-> N개의 프로그램이 실행된 시간이 각각 t1, t2, ... ,tn이라 할 때,
- 일괄처리 또는 uniprogramming : t1+t2+t3+... +tN
- 다중프로그래밍인 경우 대략 : max(t1,t2,,,,tN)
- 한 프로세스의 입출력 시에 다른 프로세스를 처리할 수 있게 되므로, CPU가 항상 일을 하고 있게 됨
- 또한, 디스크를 이용한 Buffering과 Spooling으로 입출력과 CPU수행의 중복 정도를 높일 수 있게됨
- Input Spooling은 Job Scheduling에 사용
- Output Spooling은 산발적인 프린트 출력을 모아서 프로세스가 끝난 후에 출력
- 새롭게 대두되는 이슈
- Job Scheduling : 최적의 스케쥴링 방법
- 메모리 경영 - 여러 작업이 메모리 상에 존재, 한정된 메모리 공간에 n개의 프로그램 탑재해야 되기 때문에 어떤 것들을 탑재하느냐에 대한 알고리즘
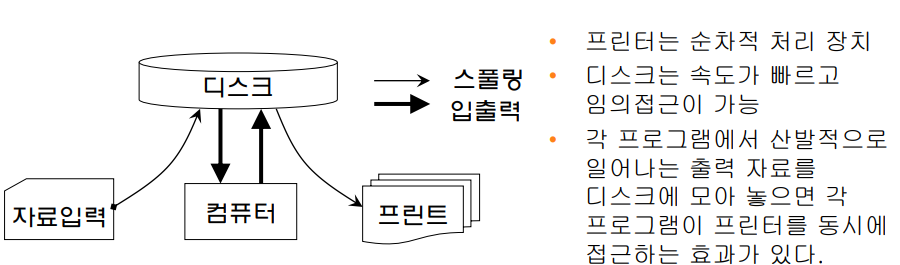
- Buffering과 SPOOLing (Simultaneous Peripherial Operations On-Line)
- Buffering은 메모리 버퍼를 이용하여 I/O와 CPU의 속도 차를 해소하여 독립된 동작을 허용
- Spooling은 하나의 순차적 처리 장치(예: 프린터)를 여러 프로세스(프로그램)가 디스크를 활용하여 동시에 공유할 수 있도록 하는 기능 제공 (디스크 활용이 포인트)
- 왜? : 디스크는 속도가 빨라서 랜덤하게 접근이 가능하기 때문에 각 프로그램이 프린터를 동시에 접근하는 효과.
각 프로세스는 프린터에 출력한 줄 아는데 알고보면 디스크에다 출력을 해놓은 것. 디스크는 속도가 빠르니까 여러 출력들을 빠르게 저장해 놓을 수 있다.
- 하나의 순차적 처리장치(프린터)를 여러 프로세스가 디스크를 활용하여 동시 공유 기능 제공
- 스풀링을 사용한다면 각 프로그램의 수행이 끝나기 전까지는 잠시 각 프로그램마다 디스크 상의 영역을 마련하는 것
--> 그곳에 저장
- 그런 후 프로그램이 종료되면 해당 영역의 출력 내용을 프린터를 통하여 출력 -> 프로그램 단위별로 묶어서 순차적으로 출력
'CS > 운영체제' 카테고리의 다른 글
| [3] 컴퓨터 구조와 OS 연계 (0) | 2022.03.14 |
|---|---|
| [2] 시분할 시스템, 실시간 시스템 (0) | 2022.03.09 |
| 프로세스의 연산 (0) | 2020.11.03 |
| 프로세스 제어블록(Process Control Block) (0) | 2020.10.29 |
| 프로세스의 개요 (0) | 2020.10.29 |