웹은 기본적으로 클라이언트가 요청하면 서버에서 데이터를 내려주는 식으로 동작한다. 여러 방식에 따라 어떤 언어와 프레임워크를 선택할지 다르다. 클라이언트(브라우저)가 서버에서 html, css, js 모든 것을 받아서 보여줄 수도 있고, html, css를 서버에서 받은 js를 이용하여 보여줄 수도 있다. 그리고 동적인 정보, 정적인 정보 어떤 정보를 받느냐에 따라서 달라질 수 있다.
간단한 웹 서비스를 개발하려면 동적인 것이 필요없을 수 있다. 그냥 html, css, js를 서버로부터 받아와서 보여주기만 하면 되고, 클라이언트가 클릭하거나 하는 동적인 활동이 필요없는 웹 화면일 수 있다. 하지만 웹 서비스에 동적인 리소스가 필요없을 수가 없다.
처음에는 WAS 하나로 모든 것을 해결해주었다. 서버에서 정적인 파일인든, 동적인 파일이든 애플리케이션 로직과 분리도 되어있지 않고 모든 것을 포함하는 것이다. 그치만 이렇게 하면 WAS가 너무 많은 역할을 담당하게 된다. 그래서 WAS를 나눈다.
웹 애플리케이션 서버(WAS)
WAS는 제일 큰 개념이라고 생각하면 된다.
WAS는 Web Server랑 서블릿 컨테이너 그리고 데이터베이스 연결 등등이 있지만, Web Server와 서블릿 컨테이너를 위주로 보겠다.
Web Server
웹 서버를 정적인 리소스를 이용하여 전달해주는 것이다. 웹 서버의 예시로는 Apache HTTP Server나 NginX같은 것이 있다.
서블릿 컨테이너
서블릿 컨테이너는 서블릿을 실행하기 위한 환경을 제공하고 서블릿의 생명주기를 관리한다. 그럼 서블릿이란 뭘까?
서블릿
이전에 동적인 동작을 처리하기 위해서 서블릿이 필요하다. 서블릿은 클라이언트의 요청을 담당하고 동적인 웹 콘텐츠를 생성하고 전송한다. 서블릿은 Java Servlet API에 정의되어 있는 인터페이스를 구현하여서 개발된다. 즉, WAS는 서블릿 컨테이너를 내장하고 있어서 서블릿을 실행할 수 있게 되는 것이다.
서블릿은 HTTP 요청을 받고 HTTP 응답을 JSON 형식으로 내려줄 수 있다. 서블리의 예시로는 톰캣이나 Jetty가 있다. 여기서 톰캣을 가지게 되는 서블릿 컨테이너의 이름이 Apache Tomcat이다.
Spring, Apache Tomcat
Spring Framework 자체적으로는 Apache Tomcat을 내장하고 있지 않아서 만약 Spring 애플리케이션을 실행하기 위해서는 별도로 Tomcat을 설치하고 설정해야 한다. 이 과정이 복잡하고 어렵기 때문에 Spring Boot를 프로젝트를 시작할 때 사용하게 된다.
Spring Boot 사용 이유
Spring Boot 프로젝트를 사용할 경우에는 내장 서블릿 컨테이너로 Tomcat, Jetty, Undertow 중 하나를 선택하여 사용할 수 있다. Spring Boot는 웹 애플리케이션을 실행하는 데 필요한 내장 서버를 자동으로 제공하므로 별도의 서버 설정이 필요하지 않다.
Spring Framework는 서블릿 컨테이너와 통합되어 웹 애플리케이션 개발을 지원하지만, Spring 자체적으로 Apache Tomcat을 내장하고 있는 것은 아니고, Apache Tomcat은 Spring 애플리케이션을 실행하기 위한 선택적인 서블릿 컨테이너 중 하나이고 Spring Boot에서 자체적으로 제공한다고 생각하면 된다.
of 메소드 : Java 9부터 추가된 List 인터페이스의 메소드. 주어진 요소들을 포함하는 불변리스트를 생성함. 리스트 생성하고 초기화할 때 사용하면 좋다. 그리고 null 요소도 허용하지 않는다. List.of로 만든 instance는 수정할 수 없다. (불변 리스트)
immutable List 불변 클래스란 무엇일까? -> String, BigDecimal, Wrapper 클래스는 불변이다. 이 의미는 특정 클래스의 인스턴스를 만든 순간부터 이 값을 바꿀 수 없게 된다는 것이다.
가변 리스트를 만들고 싶으면 ArrayList나 LinkedList, Vector를 만들어야 한다.
List<String> wordsArrayList = new ArrayList<String>(words);
List<String> wordsLinkedList = new LinkedList<String>(words);
List<String> wordsVector = new Vector<String>(words);
ArrayList와 LinkedList의 차이
ArrayList는 접근은 빠르지만 삽입 삭제가 느리다. 메모리가 연속적
LinkedList는 접근은 느리지만 삽입 삭제가 빠르다. 메모리가 따로따로. 서로 연결되는 메모리 주소를 기억하고 있다.
java에서의 LinkedList는 요소들이 양면으로 연결되어 있다. forward로 향하는 연결과 backward로 향하는 연결이 둘 다 존재한다. (doubly linked)
변경점이 적다면 ArrayList, 삽입과 제거가 빈번하다면 LinkedList를 사용하면 된다.
Array : 배열은 모든 요소들을 순서대로 저장하고 언제나 요소 하나를 제거하면 그 요소를 제거한 후 그 다음 요소를 왼쪽으로 밀어야 한다. 하지만, 배열의 특정한 위치에 있는 요소를 갖고 오는 건 쉽다.
LinkedList : 각자 요소들은 다음 요소들과 연결되어 있다. 삽입과 삭제가 더 쉽다. 하지만 특정 위치에 있는 요소를 갖고 오거나 찾는 것은 연결점들을 다 건너 다니면 무엇이 있는지 찾아야 한다.
Vector랑 ArrayList는 언제 구분해서 써야할까?
Vecotr 클래스는 자바1때부터 있었다. ArrayList는 자바1.2부터.(오래 전부터 있었다는 뜻)
그럼 Vector의 문제가 무엇이여서 ArrayList가 나타난 것일까?
vector는 모든 메서드들이 synchronize가 되어있는데, ArrayList는 Synchronize되어 있지 않다.
vector는 내부의 'add', 'remove', 'set'과 같은 변경 작업을 할 때 내부적으로 synchronized를 사용한다.
Synchronize 키워드는 어떤 차이를 만들까?
예를 들어서 한 클래스 안에 25개의 동기화된 메소드들이 있다고 하자.
만약 이 Vector 클래스의 인스턴스가 여러 스레드 사이에 공유된다면, 스레드 중 단 하나만이 이 25개의 메소드들을 실행할 수 있다.
즉, 이 동기화된 메소드들 안에서는 한순간에 오직 하나의 스레드만 코드를 실행시킬 수 있다.
이렇게 하는 이유는 프로그램이 안전하길 바라기 때문이다.
우리의 프로그램은 쓰레드 하나가 사용하든 15개의 쓰레드가 사용하든 행동방식이 바뀌면 안되고, Synchronized가 그 역할을 하려 하는 것이다.
Vector는 Thread-safe하다. 여러 쓰레드들 사이에서 데이터를 공유하는 상황에서 Vector를 사용할 수 있다.
그러나 ArrayList는 안전하지 않다. 그치만, 보안은 언제나 성능에 타격을 준다.(보안 상승, 성능 하락 / 보안 하락, 성능 향상)
왜냐하면 스레드 하나가 동기화된 메소드를 실행 중일때 그럼 다른 스레드들은 그 스레드가 동기화된 메소드의 실행을 완료할때까지 기다릴 수 있기 때문이다.
안전이 필요하지 않는 이상 ArrayList가 더 낫다.
동기화는 기초적인 안전 구현방식 중 하나이다.
그래서 만약 멀티 쓰레드 환경이 아닐 때 Vector 클래스를 사용하게 되면 성능이 떨어지게 된다.
이를 위해, ArrayList를 위해 Collections 클래스에서는 synchronizedList 메소드를 제공한다.
ArrayList클래스를 멀티스레드 환경에서 사용해야 한다면 CopyOnWriteArrayList 또는 Collections.synchronizedList를 사용해야 한다.
반복문
java Collection 인터페이스의 Iterator는 Collection 요소를 하나씩 반복적으로 접근할 수 있다.
List 안에는 primitive type를 포함할 수 없다. List 인터페이스는 제네릭 타입을 지원하기 때문에, List 내부에는 오직 객체만 포함시킬 수 있다. 그래서 사용하려면 primitive type을 객체로 래핑한 Wrapper 클래스를 사용하여 포함해야 한다.
AutoBoxing : primitive 타입의 값을 해당하는 wrapper 클래스의 객체로 바꾸는 과정을 의미한다.
java 컴파일러는 primitive type이 아래 두 가지 경우에 해당될 때 autoBoxing을 적용한다.
primitive type이 Wrapper 클래스의 타입의 파라미터를 받는 메서드를 통과할 때
primitive type이 Wrapper 클래스의 변수로 할당될 때
List를 만들려 할 때 일어나는 일은 다 AutoBoxing되어 Wrapper Class가 생성되는 것이다.
sort static solution Collections.sort는 static method이다. (즉, Collection을 따로 생성자를 통해 생성하지 않아도 사용할 수 있다. )
List는 Collection Interface를 연장한다. 즉, 이것은 Collection Interface에 있는 모든 것을 구현하고, 객체의 위치에 상관하는 메서드를 제공한다.
정리 : List interface의 구현
→ ArrayList : 배열을 기초적 데이터 구조로 사용. LinkedList에 비해서 삽입과 삭제가 느리다.
but, 특정 위치의 특정 요소에 접근하고 싶다면 매우 빨리 수행할 수 있다.
→ LinkedList : 특정 위치의 요소 찾는 것은 느리지만, 요소의 삽입과 제거는 훨씬 빠르다
→ Vector : 다중 스레드 시나리오에서는 성능 하락.
Set
용도 : 중복이 허용되지 않는 집합을 만들 때 사용한다. Unique things only : 중복이 허용되지 않는다!
List interface와 비교했을 때, Set interface는 위치 접근을 허용하지 않는다. Set은 그냥 랜덤위치에 저장한다. (갖고 있다는 사실이 중요)
Set은 기본적으로 변경을 허용하지 않는다. 따라서, 다음 코드는 되지 않는다.
Set<String> set = Set.of("Apple","Banana","Cat");
set.add("Apple"); // 오류남. -> 왜냐하면 변경을 허용하지 않기 때문
HashMap과 Hashtable의 차이 : 둘 다 해싱 기법을 사용했다는 점에서는 동일하다Hashtable(HashMap과 같지만, 모든 메서드가 동기화되어 있어 스레드가 안전)
Hashtable은 Vector와 비슷하다 → 동기화되어 있음. Hashtable의 모든 메소드는 동기화 되어 있다.
스레드가 HashMap에 비해 더 안전하고, HashMap과 동일하게 Hashtable도 분류되어 있지도 않고 순서가 있지도 않다.
Hashmap은 열쇠를 null 값과 저장할 수 있게 해준다. → Hashmap 안에는 key와 null값을 저장할 수 있다. (Hashtable에서는 할 수 없다.)LinkedHashMap(삽입 순서 기억)
LinkedHashset과 비슷하게 순서가 유지된다. 그냥 삽입 순서대로 들어간 것이기 때문에 HashMap에 비해서는 삽입과 제거가 느리다. 하지만 요소간에 연결이 되어있어 요소를 도는 이터레이션은 훨씬 빠르다.TreeMap(데이터를 정렬된 순서로 저장)
기반 데이터 구조는 Tree, 정렬된 순서로 저장된다.
트리가 존재할 때는, 데이터가 정렬되어 있기 때문에, 다른 인터페이스(NavigableMap)도 구현한다.
Hashtable
배열과 비슷하게 고정된 위치들과, LinkedList의 장점을 합친 것이다. 각각의 위치를 양동이라고 하면 양동이에 여러 가지를 저장할 수 있는 것이다. 양동이에 차곡차곡 여러 가지를 쌓을 수 있는 것이다. 그럼 어떤 양동이에 저장할지 결정하느냐? 이때 나오는 것이 해싱 함수를 사용한다. 만약 배열의 크기가 13이라고 생각해보자. (index는 그럼 0부터 12까지 있는 것이다.)
만약 15를 어디에 저장해야 할지 결정한다면 어느 양동이에 15를 저장해야 할지 어떻게 정할까? 여기에 13개의 양동이가 있으므로, 15를 13으로 나누고 나머지를 구해서 양동이에 요소를 넣는 것이다.
15는 그럼 인덱스 2의 양동이에 들어가게 되는 것이다.
즉, 해싱 함수는 어느 양동이에 요소가 들어갈지 정해주는데 사용된다.
2를 삽입한다면 2번 자리에 저장하고 싶을 것이니까 아까 저장한 15위에 2를 붙이면 된다.
34를 지우고 싶으면 8인덱스에 와서 요소를 지운다. (34나누기 13의 나머지는 8이니까!)
HashTable의 장점은 요소들을 쉽게 삽입할 수 있고, 검색과 제거 또한 훨씬 쉽게 할 수 있다.
HashTable은 매우 빠른 검색능력을 제공한다. 요소의 삽입은 때때로는 LinkedList보다 느릴 수 있지만, 배열에 비해서는 훨씬 빠르다. HashTable의 효율성은 언제나 해싱 함수의 효율성에 기반한다.(위에 예시로 든 건 그냥 설명을 위해서이지 해싱함수마다 다르다.)
Java에서는 해싱함수를 해시코드란 것을 이용하여 구현한다. 객체 클래스를 보면, hashcode()라는 메서드가 있다.
hashcode는 어느 양동이에 객체가 저장되는지를 결정하는데 사용된다. 위에서 얘기하였던 나머지를 이용해서 저장하는 것은 그냥 예시일 뿐이다. 해싱 함수들은 hashcode()를 이용해서 java에서 구현할 수 있다.
쿠버네티스는 컨테이너 애플리케이션을 분산 환경에서 운용 관리하기 위한 오케스트레이션 툴이다. (단어 하나씩 뜯어봤는데도,, 말이 어려워서 기억하기 위해..)
결과적으로는 온프레미스 환경에서 쿠버네티스를 사용할 것이지만, 일단 Azure를 사용해서 클라우드 환경에서 쿠버네티스를 사용해 보겠다!
컨테이너 이미지 빌드와 공개
전체적인 흐름
컨테이너 애플리케이션을 개발하고 운용할 때의 흐름을 알고, 순서대로 진행해 보겠다.
개발 환경 준비 Azure를 실행하기 위해서 IDE나 로그인 등을 해야함
컨테이너 이미지의 작성 및 공유 컨테이너를 동작시키려면 애플리케이션을 움직이기 위한 것들이 이미지로 있어야 한다. 필요한 것들로는 바이너리, OS, 네트워크 같은 설정들을 이야기 한다. 만약 도커일 경우에는 Dockerfile이라는 텍스트 파일에 구성을 기술하고, 이것을 빌드하면 빌드된 것을 실행 환경에서 이용 가능한 레포지토리로 공유한다. (마치 로컬에서, github에 커밋을 하고 다른 컴퓨터에서 pull해서 사용하는 느낌이였다.)
클러스터 작성 (실제 환경 작성) 실제로 컨테이너 애플리케이션을 작동시키는 서버를 구축해야 한다. 개발 환경이나 테스트 환경에서는 로컬 머신으로 작동시키지만, 서비스 공개할려면 클라우드 서비스를 사용하든지, 실제 서버 컴퓨터(온프레미스) 환경이 있어야 한다.
[ 1번의 진행과정 ]
쿠버네티스 클러스터
쿠버네티스 클러스터란, 쿠버네티스가 분산 환경에서 여러 대의 서버나 스토리지와 같은 컴퓨팅 리소스가 네트워크로 연결된 환경에서 각각 다른 역할을 가지면서 서로 협조해 가며 컨테이너 애플리케이션을 실행시키는 것을 의미한다.
쿠버네티스 클러스터를 만들려면 여러 대의 서버나 가상 머신에 쿠버네티스를 설치하고 네트워크 설정 등을 해야 한다.
클러스터를 쉽게 운용하기 위해서 먼저 Azure 컨테이너 서비스를 이용해보겠다!
먼저 Azure에 개인 계정을 만들어야 된다. (나는 건국대학교 학생 계정을 이용해서 1년 무료로 사용할 수 있다고 해서 학교 계정을 사용하였다)
Azure 포털 사이트에서도 cli 창을 띄울 수 있었는데, 리눅스 명령어도 익힐 겸 Azure CLI 명령을 설치해서 할 수 있었다. (사이트에서 MSI 인스톨러로 다운받았다.)
만약 Azure에 로그인을 하면 cmd창을 켜서 az login을 입력하면, redirect페이지가 나오고 로그인이 된다.
4. Azure의 서비스를 이용하기 위해 리소스 프로바이더도 할당한다.
Azure 리소스 프로바이더를 활성화해야 하는 이유 Azure에서 리소스 프로바이더를 활성화해야 하는 이유는 해당 리소스를 생성하고 관리, 조작하기 위해서이다. Azure의 각각의 서비스는 Azure Resource Manager(ARM)이라는 것에 의해서 관리되는데, 리소스 프로바이더는 이 ARM에서 각각의 서비스에 대한 API 엔드포인트를 제공한다.
그래서 Azure 리소스를 만들거나 관리하려면 해당 리소스 유형에 대한 프로바이더가 활성화되어 있어야 한다.
예를 들어서 Azure Virtual Machines를 만들려면 Microsoft.Compute 리소스 프로바이더가 필요하다. 이 프로바이더는 Virtual Machine과 관련된 API 엔드포인트를 제공해서, 가상 머신의 생성, 삭제, 업데이트 등의 작업을 수행할 수 있도록 한다.
여기서는 Microsoft.Network, Storage, Compute, ContainerService 모두 활성화시켰다.
kubectl 명령
쿠버네티스 클러스터를 조작하려면 GUI를 사용해도 되는데, 일반적으로는 명령으로 조작한다고 한다.
명령으로 조작하기 위해서는 kubectl을 사용한다. kubectl 명령은 쿠버네티스 클러스터의 상태를 확인하거나 구성을 변경하기 위한 것이다. 개발을 하는 클라이언트 머신에 설치하면 된다.
클라이언트인 도커 클라이언트에서 서버인 도커 데몬의 API에 접속해 컨테이너 및 컨테이너 이미지에 대한 다양한 작업을 수행할 수 있다.
도커 클라리언트에서 도커 데몬 API에 접속하려면 도커 명령어를 실행해야 한다.
[도커 엔진을 구성하는 세가지 요소]
1. 도커 클라이언트
- 도커 데몬의 사용자 인터페이스가 되는 구성 요소다. 사용자는 도커 클라이언트를 조작해서 도커 데몬과 통신한다.
2. 도커 데몬
- 도커 클라이언트의 요청에 따라 도커 객체를 관리하는 구성 요소. 도커 클라이언트와 도커 데몬은 각각 클라이언트와 서버 역할을 하며, 도커 클라이언트의 요청에 따라 통신이 시작되고 도커 데몬의 응답으로 통신이 종료된다.
3. 컨테이너 레지스트리
- 컨테이너 이미지를 저장하기 위한 구성 요소. 도커 데몬은 도커 클라이언트의 요청에 따라 컨테이너 레지스트리와 통신해서 컨테이너 이미지를 내려받고 업로드한다.
도커 객체
- 도커 데몬의 관리 대상( 네트워크, 볼륨, 컨테이너, 컨테이너 이미지 등)
컨테이너 런타임
컨테이너를 다루는 도구
도커 엔진은 컨테이너 런타임을 포함하는 개념
도커
컨테이너 런타임 중에서 제일 유명한 것
컨테이너
운영 체제에서 실행되는 프로세스인데 다른 프로세스와 격리되어 있다(외부 영향을 받지 않는 독립적인 환경에서 프로세스를 실행할 수 있다.)
컨테이너를 외부와 격리하기 위해 네임스페이스라는 구조를 사용한다.
파일 시스템의 격리
네임스페이스의 작동 방식을 구현하는 데 특히 중요한 것은 파일 시스템의 격리.
파일 시스템 → 운영 체제의 기능 중 하나, 파일 시스템에 의해 데이터를 ‘파일’ 단위로 읽고 쓸 수 있다
컨테이너는 컨테이너 전용 독립 파일 시스템을 사용한다.
네임스페이스에서 파일 시스템을 격리하는 방식은 컨테이너 내 프로세스가 yum 및 apt와 같은 패키지 관리 시스템에 설치된 패키지에 의존하는 경우 특히 유용하다.
리눅스 네임스페이스 : 프로세스를 실행할 때 시스템의 리소스를 분리해서 실행할 수 있도록 도와주는 기능
패키지 : 어떤 기능을 제공하는 프로그램을 한꺼번에 배포 형식으로 만든 것
패키지 관리 시스템 : 패키지의 설치나 종속성을 관리하는 시스템 (yum, apt, brew)
대부분의 경우 운영 체제의 파일 시스템에 다른 버전의 패키지가 공존하기는 어렵다.
컨테이너를 사용하면 다른 버전의 패키지가 공존할 수 있다.
컨테이너와 가상 서버의 차이
컨테이너와 가상 서버는 매우 비슷하다.
결정적인 차이
컨테이너는 본질적으로 프로세스와 동일
하드웨어 에뮬레이션 없이 리눅스 커널을 공유해서 프로세스를 실행
네임스페이스와 같은 방식으로 다른 컨테이너와 프로세스에서 격리됨
가상 서버는 하드웨어를 모방하는 소프트웨어
운영체제 위에 하드웨어를 에뮬레이션하고 그 위에 운영체제를 올리고 프로세스 실행.
가상 서버에 운영 체제를 설치해 다른 가상 서버나, 가상 서버를 실행하는 물리 서버와 격리함.
컨테이너는 다른 컨테이너와 프로세스와 운영체제(커널)을 공유함
가상서버는 다른 가상 서버나 물리 서버와 운영 체제를 공유하지 않음
컨테이너를 가상 서버와 비슷하다고 생각하는 것보다 특수한 프로세스라고 생각하는 편이 좋다.
컨테이너로 호스트 OS와 다른 OS를 사용한다는 말의 의미
컨테이너는 호스트 머신의 운영 체제를 이용하고 있지만, 어떤 컨테이너가 우분투에 포함되는 소프트웨어 세트를 갖추고 있다면 그 컨테이너 내에서 실행되는 프로세스를 마치 우분투에서 실행되는 것처럼 보이게 할 수 있다.
여러 운영 체제가 공존할 수 있다.
컨테이너가 있으면 가상 서버는 필요 없다?
컨테이너는 운영 체제를 공유하므로 운영 체제 버전의 차이와 호환성에 따라 제대로 작동하지 않을 수 있다.
반면 가상 서버는 각각 운영 체제를 설치하므로 운영 체제를 포함한 동일한 환경을 재현할 수 있다.
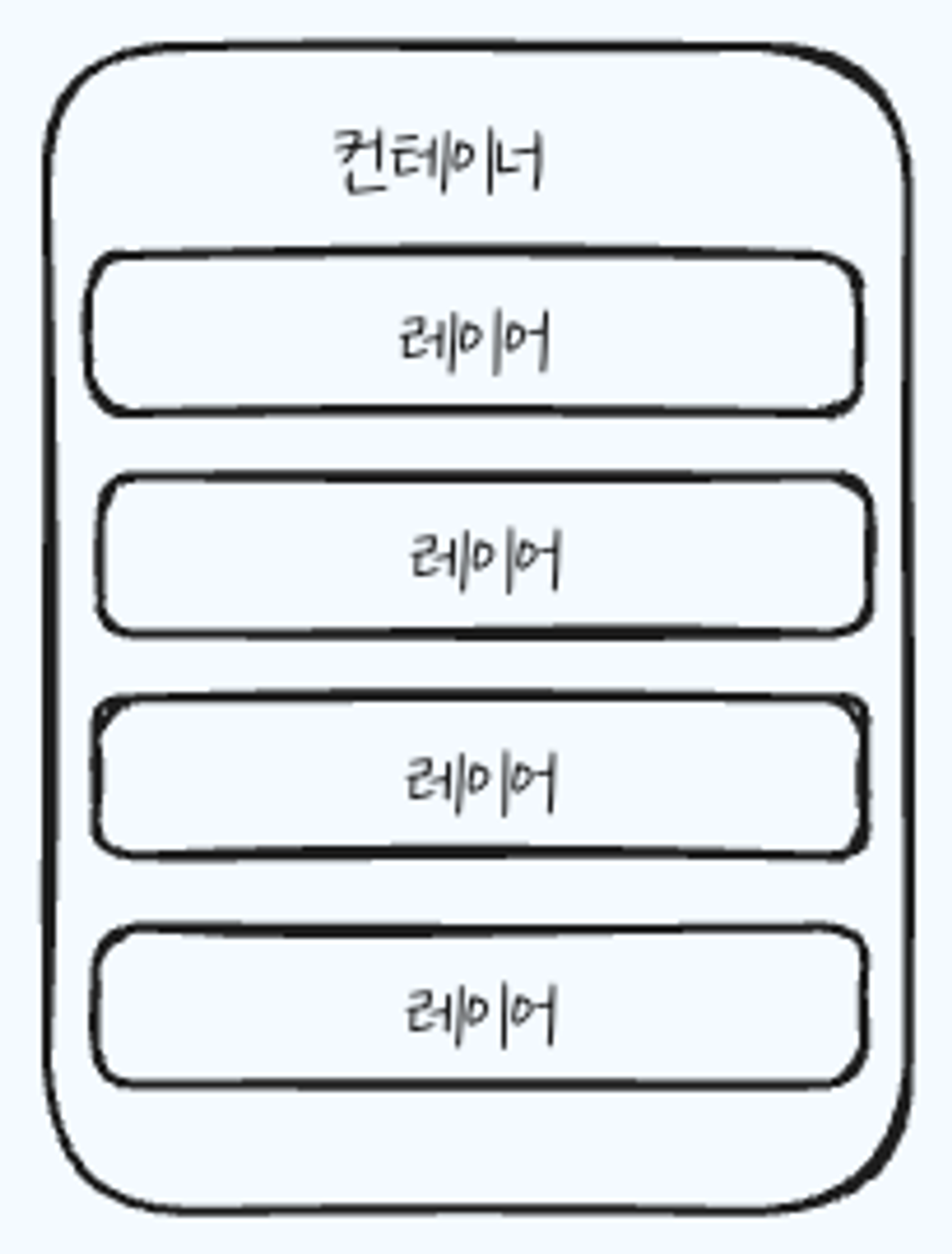
컨테이너 이미지
컨테이너를 실행하기 위한 템플릿 → 컨테이너는 컨테이너 이미지로 생성
클래스(컨테이너 이미지) - 객체(컨테이너)
컨테이너 이미지의 대부분은 컨테이너를 실행하는 데 필요한 파일 시스템
파일 시스템은 레이어라는 층이 겹쳐서 구성됨
도커의 차분 관리와도 관련이 있다.
컨테이너 이미지의 생성
컨테이너 이미지는 기본이 되는 컨테이너 이미지의 파일 시스템에 새로운 레이어가 겹쳐서 생성된다.
예를 들어, Ubuntu OS 컨테이너 이미지가 있고, 이 컨테이너에 웹 서버인 nginx 프로그램과 구성 파일이 포함된 레이어를 겹쳐서 Ubuntu OS에서 실행되는 nginx 서버의 이미지를 만들 수 있다.
컨테이너에서 셸을 기동한 후에 패키지 관리 시스템을 실행해서 수동으로 작성할 수 있다.
그러나 보통은 컨테이너 생성 절차를 설명하는 텍스트 파일인 도커 파일을 사용해서 자동으로 만든다.
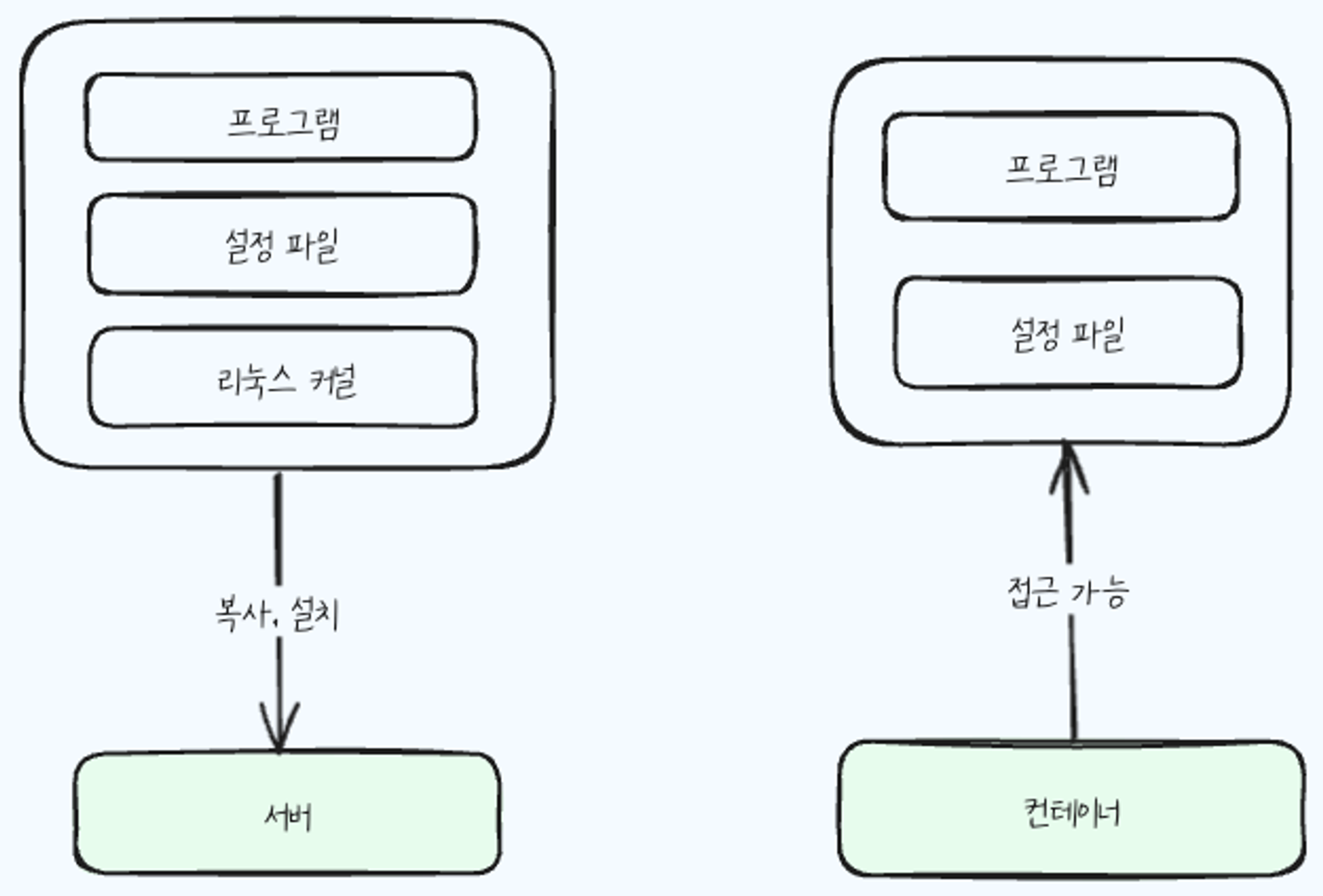
운영 체제 설치 디스크와 컨테이너 이미지로 운영 체제 사용하는 것의 차이
운영 체제 설치 디스크는 필요한 것을 복사해서 설치하는 것이지만, 컨테이너 이미지로 운영 체제를 사용하는 개념은 프로그램과 설정 파일을 컨테이너에서 접근해서 사용하는 것이다.
[컨테이너와 도커의 활용]
보통 우리가 애플리케이션을 개발하면, 로컬에서 앱을 만들고, OS, 네트워크 환경을 설정하고, 라이브러리나 미들웨어를 설치하여서 만든다. 근데 문제는 로컬에서는 잘 되던 프로그램이 실제 환경에 배포하면 정상적으로 움직이지 않는다. 이건 환경이랑 설정이 달라서 생기는 문제이다.
컨테이너를 사용하면 애플리케이션 실행에 필요한 모든 파일과 디렉토리를 통째로 컨테이너 이미지로 모을 수 있다.
그럼 우리가 앱을 개발해서 Dockerfile을 이용해서 컨테이너 이미지를 작성한다. 이 이미지는 OS 커널과 호환성이 있어서 컨테이너가 작동하는 환경이라면 이미지를 받아서 어디서든지 작동시킬 수 있다. 그럼 컨테이너를 작동시키는 곳에서는 어디서든 가능하게 되는 것이다.
컨테이너 이미지를 관리해주는 것은 레지스트리이다. 컨테이너 이미지는 레지스트리로 공유할 수 있다. 도커의 공식 레지스트리는 Docker Hub이다. 그럼 이제 우리가 Ubuntu같은 OS를 사용하고 싶으면 Ubuntu 베이스 이미지를 받아서 사용하면 된다.
(private 환경이라면 컨테이너 레지스트리는 도커 hub와 같은 시스템을 별도로 사용해야 한다)
추상 클래스는 공통되는 부분을 모아서 추상 클래스에 정의하고, 그 외의 부분을 자식 클래스에서 확장하여 사용하는 개념으로 보면 된다.
예를 들어서, 내가 조교를 하면서 교수님께 메일을 보내는 경우이다.
나는 항상 “교수님, 안녕하십니까?”를 메일 제일 처음에 붙이고, 제일 마지막에 “항상 좋은 강의 감사합니다.” 를 붙인다. 그리고 중간의 내용은 언제나 바뀔 수 있다. 중간의 내용은 추상 메서드로 만든다.
public abstract void 교수님께메일 {
public void 머릿말(){
System.out.println("교수님, 안녕하십니까?");
}
public abstract void 내용();
public void 맺음말(){
System.out.println("항상 좋은 강의 감사합니다.");
}
}
그럼 ‘교수님께 메일’ 이라는 abstract class를 만들고, ‘추가 수강 신청’과 “강의 질문” class는 abstract를 구현한 클래스이다.
public class 추가_수강_신청 extends 교수님께메일{
@Override
public void 내용() {
System.out.println("혹시 이번 강의 추가신청 가능할까요?");
}
}
public class 강의_질문 extends 교수님께메일{
@Override
public void 내용() {
System.out.println("혹시 이번 강의 질문드려도 될까요?");
}
}
그럼 이런 클래스를 활용하려면 객체를 만들어서 ‘머릿말’, ‘내용’, ‘맺음말’을 사용하면 된다.
추가_수강_신청 pm = new 추가_수강_신청();
pm.머릿말();
pm.내용();
pm.맺음말();
강의_질문 pm2 = new 강의_질문();
pm2.머릿말();
pm2.내용();
pm2.맺음말();
추상 클래스는 위의 예에서 보듯이, 필수적으로 구현해야 하는 기능을 공통적으로 묶고, 만약 그 안에 구현해야 되는 내용이 있고 내용이 조금 다르다면, 해당 내용을 추상 메서드로 선언하여 구현하면 된다.
인터페이스
그럼 인터페이스는 언제 사용할까? 대상이 만약 교수님이 아니라, 다른 모든 사람들에게 보낸다고 생각했을때, 그때도 머릿말, 내용, 맺음말은 필요하다. 그러나 해당 대상은 교수님이 아니라 형식만 interface로 선언해주고, 구현 내용은 다르게 해주는 것이다.
public class 친구에게 implements 메일형식{
@Override
public void 머릿말(){
System.out.println("ㅎㅇ");
}
@Override
public void 내용(){
System.out.println("낼 머함");
}
@Override
public void 맺음말(){
System.out.println("");
}
}
public class 교수님에게 implements 메일형식{
@Override
public void 머릿말(){
System.out.println("교수님 안녕하십니까?");
}
@Override
public void 내용(){
System.out.println("낼 미팅 날짜 잡아도 되겠습니까?");
}
@Override
public void 맺음말(){
System.out.println("감사합니다.");
}
}
메일은 동일한 목적을 가지는 머릿말, 내용, 맺음말이 동작이 준비되지만 저마다의 방식으로 가능하다.
또한, 동물 예시도 들고왔다.
public abstract class Animal {
public abstract void eat();
public void sleep() {
// 일반 메소드 동작 정의
}
}
그런 다음에 이 Animal 클래스를 확장하여 개, 고양이, 물고기 등으로 확장하면, 각 동물들이 먹는 기능을 이렇게 따로 정의할 수 있다.
public class Dog extends Animal {
public void eat() {
System.out.println("개밥");
}
}
public class Cat extends Animal {
public void eat() {
System.out.println("고양이밥");
}
}
public class Fish extends Animal {
public void eat() {
System.out.println("물고기밥");
}
}
기본적인 구현은 Animal 에서, 고유의 동작은 Dog, Cat, Fish 에서 정의된다.
이번에는 같은 동물인데 인터페이스를 활용할 수 있다. 간단히 소리를 내는 하나의 추상 메소드만 정의하였다.
public interface Audible {
void makeSound();
}
그런 다음에 각 동물에 대해 소리를 내는 기능을 추가한 뒤 makeSound() 메소드를 정의하였다.
public class Dog extends Animal implements Audible {
...
public void makeSound() {
System.out.println("멍");
}
}
public class Cat extends Animal implements Audible {
...
public void makeSound() {
System.out.println("냐옹");
}
}
그러면 강아지와 개는 소리를 내는 기능이 더해졌고 각 클래스 내에서 어떤 소리를 내는지 정의하였습니다.
그런데 물고기는 소리를 따로 내지 않는다. 별도의 인터페이스를 만들어서 활용해 보겠다.
public interface SilentAnimal {
}
그리고 Fish 클래스에 이를 구현하도록 해볼게요.
public class Fish extends Animal implements SilentAnimal{
public void eat() {
System.out.println("사료");
}
}
Animal[] animals = new Animal[3];
animals[0] = new Dog();
animals[1] = new Cat();
animals[2] = new Fish();
for (Animal animal : animals) {
if (animal instanceof Audible) {
((Audible) animal).makeSound();// 개, 고양이
} else if (animal instanceof SilentAnimal){
System.out.println("소리를 내지 않는 동물");// 물고기
}
}
[정리]
추상클래스는 다중 상속이 안되지만, 인터페이스는 다중 상속이 가능하다.
추상 클래스는 객체로 생성될 수 없는 클래스로 자식 클래스에서 확장될 수 있도록 만들어진 클래스이다.
추상 클래스는 일반 메서드와 추상 메서드 모두 가질 수 있어서 기본적인 구현을 추상 클래스에서 하고, 하위 클래스에서는 고유의 동작을 확장하기 위해 사용한다.
인터페이스는 클래스는 반드시 메소드들의 동작을 정의해야 하며, 해당 클래스는 동일한 사용 방법과 동작을 보장할 수 있다.
import sys
input = sys.stdin.readline
def shortcut(start):
graph[start] = 0
for i in range(n): # 노드 개수만큼 반복
for j in range(m):
current_node = edges[j][0]
next_node = edges[j][1]
cost = edges[j][2]
if graph[current_node] != int(1e9) and graph[next_node] > graph[current_node] + cost:
graph[next_node] = graph[current_node] + cost
if i == n - 1:
return True
return False
n, m = map(int, input().split())
graph = [int(1e9)] * (n + 1)
edges = []
for _ in range(m):
x, y, z = map(int, input().split())
edges.append((x, y, z))
if shortcut(1):
print(-1)
else:
for i in range(2, n + 1):
if graph[i] == int(1e9):
print(-1)
else:
print(graph[i])
성능 요약
메모리: 32276 KB, 시간: 968 ms
분류
그래프 이론, 벨만–포드
문제 설명
N개의 도시가 있다. 그리고 한 도시에서 출발하여 다른 도시에 도착하는 버스가 M개 있다. 각 버스는 A, B, C로 나타낼 수 있는데, A는 시작도시, B는 도착도시, C는 버스를 타고 이동하는데 걸리는 시간이다. 시간 C가 양수가 아닌 경우가 있다. C = 0인 경우는 순간 이동을 하는 경우, C < 0인 경우는 타임머신으로 시간을 되돌아가는 경우이다.
1번 도시에서 출발해서 나머지 도시로 가는 가장 빠른 시간을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 도시의 개수 N (1 ≤ N ≤ 500), 버스 노선의 개수 M (1 ≤ M ≤ 6,000)이 주어진다. 둘째 줄부터 M개의 줄에는 버스 노선의 정보 A, B, C (1 ≤ A, B ≤ N, -10,000 ≤ C ≤ 10,000)가 주어진다.
출력
만약 1번 도시에서 출발해 어떤 도시로 가는 과정에서 시간을 무한히 오래 전으로 되돌릴 수 있다면 첫째 줄에 -1을 출력한다. 그렇지 않다면 N-1개 줄에 걸쳐 각 줄에 1번 도시에서 출발해 2번 도시, 3번 도시, ..., N번 도시로 가는 가장 빠른 시간을 순서대로 출력한다. 만약 해당 도시로 가는 경로가 없다면 대신 -1을 출력한다.
내가 푼 풀이
먼저 벨만-포드 알고리즘의 시간 복잡도는 O(VE)이다. 해당 문제에서 V는 500, E는 6000까지 될 수 있으니까 O(30000)은 연산이 1초를 넘지 않아서 사용해도 된다고 판단하였다.
먼저 n,m,edge들을 입력받고, 다익스트라와 비슷하게 그래프를 초기화 해준다.
n, m = map(int, input().split())
graph = [int(1e9)] * (n + 1)
edges = []
for _ in range(m):
x, y, z = map(int, input().split())
edges.append((x, y, z))
나는 shortcut이라는 함수를 만들어서 벨만 포드 알고리즘을 진행하였다.
def shortcut(start):
graph[start] = 0
for i in range(n): # 노드 개수만큼 반복
for j in range(m):
current_node = edges[j][0]
next_node = edges[j][1]
cost = edges[j][2]
if graph[current_node] != int(1e9) and graph[next_node] > graph[current_node] + cost:
graph[next_node] = graph[current_node] + cost
if i == n - 1:
return True
return False
해당 문제에서는 1번 도시만 확인하면 되니까 나중에 start에 1을 넣어서 확인하면 된다.
먼저 시작점은 0으로 초기화해준다.
그리고 노드 개수만큼, edge 개수만큼 이중 for문을 수행해야 한다.
간선을 모두 확인하는데, edges[j]안에 edges의 정보를 current_node, next_node, cost로 다시 받는다.
만약에 현재 노드를 거쳐서 다음 노드로 가는 것이 기존에 시작노드에서 다음노드로 가는 값(graph[next_node])보다 작다면, graph[next_node]를 업데이트 해주면 된다.
여기까지가 벨만-포드의 핵심이다.
이 문제에서는, 해당 반복을 끝냈는데, 가중치가 음수가 되어있는 결과를 확인해야 한다. 왜냐하면 음수가 되었다면, 해당 루트를 계속 반복하면 시간은 거꾸로 간다.(그래서 타임머신 문제이다.)
따라서 노드 개수만큼 반복할 때, 마지막 업데이트를 하는데 또 바뀌어 있다는 뜻은 모든 노드와 간선에 따라서 다 업데이트 했는데 또 바뀌는 것은 해당 가중치가 음수라는 의미이다. 그래서 이 때는 출력을 -1만 하면 된다.
서버를 도커를 사용해서 배포해야 한다, 도커를 사용하면 신세계를 경험할 수 있다. 이러한 말만 많이 듣고, 정작 배포할 때는 배포파일을 명령어로 EC2로 이동시켜서 실행해 본 경험 밖에 없어서 도커에 대한 개념을 알고 배포까지 해보려고 한다.
먼저, 이 글은 도커에 대한 개념을 공부한 내용이다.
도커의 정의
도커란 개발자가 컨테이너화된 애플리케이션을 빠르게 빌드, 테스트 및 배포할 수 있게 해주는 가상화 도구 라고 한다.
이 말만 들어서는 정의 안에 너무 모르는 말들이 많았다. 가상화, 컨테이너에 대한 용어부터 알고 가겠다.
가상화
가상화란 하나의 물리적 서버 호스트에서 여러 개의 서버 운영 체제를 게스트로 실행할 수 있게 해주는 아키텍쳐이다.
내 물리적 서버는 현재 윈도우를 사용하고 있는데, 우분투나 다른 운영체제를 사용해야 할 경우가 생긴다. 그 때 가상화라는 것을 사용하는 것이다.
가상화가 필요한 이유는 서버의 성능을 나누어서 사용하기 위해 필요하다. 하나의 서버를 나누어서 성능을 분산시키고, 분산된 서버들은 각기 다른 서비스를 수행한다. 즉, 내가 여러 서비스를 실행하고 싶을 때, 컴퓨터를 여러 대 사는게 아니라 하나의 서버에서 서버를 여러 개 쓰는 효과를 누리게 된다.
가상화를 통해서 사용자가 많은 서비스에는 많은 자원을 할당해주고, 적은 서비스에는 적게 할당해 줄 수 있다.
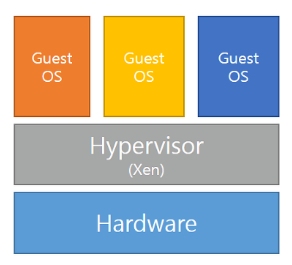
이런 가상화를 구현해주는 기술은 Hypervisor라는 가상화 기술을 사용한다. Hypervisor는 여러 개의 운영체제를 하나의 Host OS에 생성해서 사용할 수 있게 해주는 소프트웨어이다. 여러 개의 운영체제는 하나 하나가 가상머신 이라는 단위로 구별이 된다.
그럼 Hypervisor는 os들에게 자원도 나누어주고, os들이 요청하는 커널 번역해서 하드웨어에게 전달도 해준다. Hypervisor에 의해 생성되고 관리되는 운영체제는 guest 운영체제라고해서, 각 guest 운영체제는 완전히 독립된 공간과 시스템 자원을 할당받아서 사용하게 된다.
그럼 위에서 얘기했던 도커를 사용하는 이유랑 같은거 같다. 그럼 가상화의 어떠한 단점 때문에 도커가 나오게 된 것일까?
가상화를 사용하는 툴은 Virtual Box나 VMWare 같은 것들이 있다. 근데 이러한 가상화 툴의 단점은 Hypervisor를 반드시 거쳐야 하므로 일반 호스트에 비해서 성능 손실이 발생한다. 그리고 가상머신에 guest 운영체제를 사용하기 위한 라이브러리, 커널 등을 전부 포함해서 배포할 때 크기도 커진다.
즉, 가상머신을 완벽한 운영체제를 생성할 수 있는 장점이 있긴 하지만, 성능이 떨어지고 용량 문제도 생기는 것이다.
이를 해결하기 위해 나온 것이 컨테이너의 개념이다.
컨테이너
컨테이너란 가상화된 공간을 생성하기 위해서 리눅스 자체 기능을 사용해서 프로세스 단위의 격리환경을 만든다. 여기서 격리 환경을 컨테이너라고 하게 된다.
컨테이너의 사전적 의미는 어떤 물체를 격리하는 공간으로 이걸 소프트웨어에서 사용할 때는 파일 시스템+격리된 자원 + 네트워크를 사용할 수 있는 독립된 공간이라는 의미로 가져온다.
우리가 아는 컨테이너는 스프링에서 자주보던 서플릿 컨테이너나 IoC 컨테이너, Bean 컨테이너 같은 것들이다. 이런 컨테이너들은 컨테이너에 담긴 것들의 라이프 사이클을 관리해준다. 어떤 것들을 생성하고, 운영하고, 제거까지 컨테이너가 관리해주는 것이다.
그럼 도커에서의 컨테이너란 이미지의 목적에 따라서 생성되는 프로세스 단위의 격리환경으로 프로세스의 생명 주기를 관리하는 환경을 제공해준다.
컨테이너 안에는 애플리케이션을 구동하는데 필요한 라이브러리와 실행 파일만 존재해서 이미지로 만들게 되면, 이미지 용량도 매우 적다. 여기서 이미지란 컨테이너를 만드는 데 필요한 모든 지시사항과 dependency를 포함하는 템플릿으로 ‘컨테이너를 만들어주는 틀’이라고 생각하면 된다.
이 컨테이너를 다루는 기술 중 하나가 도커가 되는 것이다. (도커 이외에도, Red Hat Openshit, ECS, 이런 것들이 있다고 한다..)
Q> 그럼 컨테이너를 왜 써야 하는가? A> 이미지의 실행, 배포가 빨라지고 Host와의 격리를 통해서 독립된 개발을 할 수 있다.
여기서 도커는 컨테이너 기술에 여러 기능을 추가한 오픈소스 프로젝트인 것이다.
도커
그럼 컨테이너를 도커는 어떻게 관리하는 것일까? 도커는 Docke Engine을 통해서 컨테이너를 관리할 수 있다. 도커 엔진은 유저가 컨테이너를 쉽게 사용할 수 있게 하는 주체로 컨테이너의 라이프 사이클을 관리해주고 이미지, 볼륨, 네트워크 까지 관리해준다.
그래서 최근 자바 프로젝트는 SpringBoot + Docker + EC2 조합으로 환경을 구성한다고 한다. 그럼 도커 시스템을 구축하고 배포하는 방법을 보겠다.
도커를 통해서 배포하기
먼저 도커를 설치해야 한다. 나는 도커 데스크톱까지 설치해주었다.
그리고 테스트할 SpringBoot 프로젝트를 만들었다. 해당 프로젝트에 Dockerfile을 만들어서 설정을 해주면 된다. 제일 간단한 설정만 따와서 해보았다.
FROM amazoncorretto:11
COPY build/libs/*.jar dockerpr-0.0.1-SNAPSHOT.jar
ENTRYPOINT ["java", "-jar", "dockerpr-0.0.1-SNAPSHOT.jar"]
해당 설정을 해준 뒤, Docker Image를 만들어야 한다. Intellij에서 터미널에서 제일 루트 위치에서 실행시켜주면 된다.
docker build -t jakeheon/dockerpr
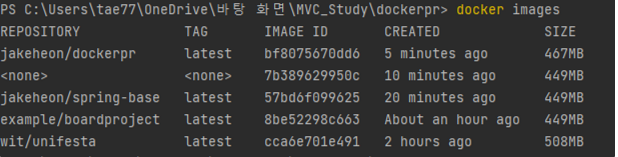
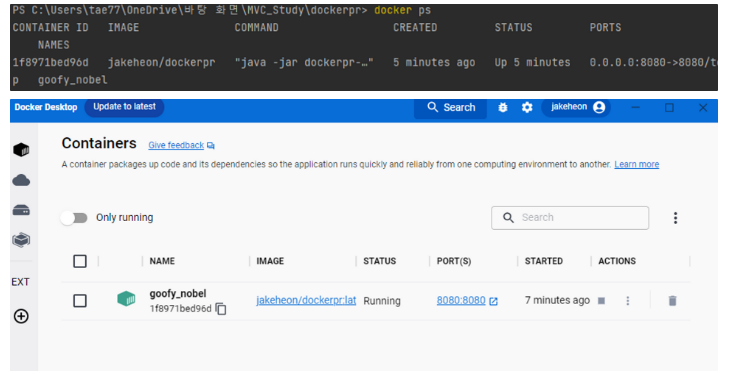
그리고 docker images로 도커 이미지가 생성되었는지 확인하면 된다. (잘 안되어서 몇 번 하다보니까 이미지가 잔뜩 생겼다.. 오류는 docker에 로그인을 하지 않았거나(docker login) 파일 위치가 잘못되었거나 하는 경우였다)
그리고 Container를 실행해준다. Host Port와 Container Port를 연결할려고 port를 2개 입력하였다.
우리는 컴퓨터의 한 측면의 개선이 전체 성능을 개선 크기에 비례하여 증가시킬 것으로 기대하지만, 실제로는 그렇지 않다.
만약에 어떤 프로그램이 실행되는데 100초 정도 걸린다고 가정하자. 곱하기 하는게 80초 정도 걸린다. (나머지는 따른거)그래서 곱하기가 많이 차지하니까 곱하기에서 성능을 향상 시키려고 하였다. 만약 4배정도 빠르게 실행하고 싶으면 곱하기 성능이 얼마정도 빨라져야 될까??-> 그럼 변수로 두고 생각해보자. Tmultiply(Tm이라고 하겠다)는 80초이고, Tother(To)는 20초이다. 그리고 Tnew는 4배정도 빨라져야 되기 때문에 100/4 = 25s가 된다. - Tm = 80s- To = 20s- Tnew = 25sTnew = To + Tm/speedUp25 = 20 + 80/x -> x = 80/5 = 16. 즉, speed up이 16배 정도 되어야 전체는 4배정도 빨라질 수 있다.
그럼 5배정도 빠르게는 할 수 있을까? 80/speedup + 20 = 20이 되어야 하는데 그렇게 될려면 speedup이 무한대가 되어야한다. 실제로 불가능하다는 이야기이다.