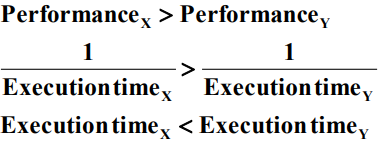우리는 컴퓨터의 한 측면의 개선이 전체 성능을 개선 크기에 비례하여 증가시킬 것으로 기대하지만, 실제로는 그렇지 않다.
만약에 어떤 프로그램이 실행되는데 100초 정도 걸린다고 가정하자. 곱하기 하는게 80초 정도 걸린다. (나머지는 따른거)그래서 곱하기가 많이 차지하니까 곱하기에서 성능을 향상 시키려고 하였다. 만약 4배정도 빠르게 실행하고 싶으면 곱하기 성능이 얼마정도 빨라져야 될까??-> 그럼 변수로 두고 생각해보자. Tmultiply(Tm이라고 하겠다)는 80초이고, Tother(To)는 20초이다. 그리고 Tnew는 4배정도 빨라져야 되기 때문에 100/4 = 25s가 된다. - Tm = 80s- To = 20s- Tnew = 25sTnew = To + Tm/speedUp25 = 20 + 80/x -> x = 80/5 = 16. 즉, speed up이 16배 정도 되어야 전체는 4배정도 빨라질 수 있다.
그럼 5배정도 빠르게는 할 수 있을까? 80/speedup + 20 = 20이 되어야 하는데 그렇게 될려면 speedup이 무한대가 되어야한다. 실제로 불가능하다는 이야기이다.
대부분의 프로그램, 흔히 우리가 Application Software라고 불리는 것들은 high level language로 작성되어 있다.
이건 우리가 보는 거의 젤 테두리 느낌이다.
만약 high level language로 프로그램이 짜여져 있으면 System Software인 Compiler(컴파일러)가 기계가 이해할 수 있는 machine code로 바꾸어준다. machine code는 도저히 이제 구분하기가 어려운 10101010001.. 로만 구성된 이진 코드이다.
그리고 System Software에는 OS도 포함된다. Operating System, OS는 우리가 사용하는 user Program과 하드웨어 사이에서 인터페이스 역할을 한다. 기본적인 input output도 처리해 주고, 메모리도 할당해주고, 프로그램 task들을 스케쥴링하고 리소스 할당도 다 OS가 해주는 역할이다.
하드웨어는 Processor, memory, I/O controller를 갖는다.
위에 얘기했던 HLL(High Level Language)랑 Binary Machine Language는 이제 program code의 레벨로 나눌 수 있다.
기계가 이해할 수 있는 건 Binary Machine Language이다. 우리가 그나마 잘 이해한다는 C나 java로 코드를 짜도 기계는 이해할 수 없는 애들이다.
먼저, 어셈블리 언어를 알아야 한다. 어셈블리 언어는 그래도 이진코드보다는 조금 직관적이다. 이런 어셈블리 언어로 구성된 것은 one to one으로 machine code와 매칭된다. 어셈블리 언어는 명령어를 텍스트로 나타낸 것이다. 텍스트 하나하나가 기계어로 매치되어 바뀐다. 이걸 바꿔주는게 어셈블러로 보면 된다.
어셈블리 언어보다 이제 우리에게 더 직관적인게 HLL이다. High Level Language는 여러 장점이 있다.
먼저, 개발자가 사용하는 자연어와 비슷하다. 그래서 생산성도 올라가고, 프로그램 관리도 쉬워진다. 또, 프로그램이 컴퓨터와 독립적으로 되는 것이라 효과적이다. 이러한 HLL을 어셈블리언어로 바꿔주는게 컴파일러다.