안드로이드는 휴대전화를 비롯한 휴대용 장치를 위한 운영체제와 미들웨어, 사용자 인터페이스 그리고 표준 응용 프로그램(웹 브라우저, 이메일 클라이언트, 단문 메시지 서비스(SMS), 멀티미디어 메시지 서비스(MMS) 등)을 포함하고 있는 소프트웨어 스택이자 모바일 운영체제이다.
Android Architecture
리눅스 커널( != 리눅스 배포판)
- 안드로이드는 리눅스 커널 상에 만들어져 있음
- 하드웨어 구동하는 기능 수행
- 프로세스, 메모리, 전원, 네트워크, 디바이스 드라이버, 보안 등의 핵심적인 시스템 서비스를 지원함
- 표준 리눅스 유틸리티를 모두 제공하지는 않음
- 안드로이드 커널도 공개되어 있음
HAL(Hardware Abstraction Layer)
- 자바 API 프레임워크에서 하드웨어 기능을 이용하는 표준 인터페이스 제공
- 자바 API 프레임워크에서 하드웨어 기기( 카메라, 블루투스 등)를 이용하기 위한 코드가 실행되면 내부적으로 HAL의 라이브러리 모듈이 로딩되어 처리됨.
라이브러리
- 장비의 전반적인 속도를 결정하는 중요한 요소임
- 자바가 아니라 C/C++로 작성되어 있으며, 애플리케이션 프레임워크를 통해 사용할 수 있도록 구성되어 있음
- 안드로이드 라이브러리 종류
- 웹브라우저 및 웹렌더링 엔진 WebKit
- 미디어 응용 개발 OpenMax AL
- 임베디드용 c라이브러리 libc
- 오디오, 비디오 재생을 위한 미디어 지원
- 3차원 컴퓨터 그래픽스 OpenGL ES
- 벡터 폰트 출력을 위한 FreeType
- 데이터베이스 지원을 위한 SQLite
안드로이드 런타임 : 코어 라이브러리(자바 라이브러리의 대부분 기능) + Android Runtime
애플리케이션 프레임워크
- 안드로이드 API : 안드로이드에서 제공하는 애플리케이션도 애플리케이션 프레임워크의 API 기능을 기반으로 함
- 응용 프로그램들은 하위의 커널이나 시스템 라이브러리를 직접적으로 호출할 수 없으며 API를 통해서 기능을 요청해야 함
애플리케이션(응용프로그램)
- 모든 응용프로그램은 애플리케이션 프레임워크의 API를 사용
안드로이드 앱은 컴포넌트를 기반으로 함
컴포넌트 : 안드로이드 시스템에서 생성하고, 관리하는 클래스( 앱 내에서의 실행 단위 )
인스턴스화 할 수 있는 4개의 컴포넌트( 이걸 잘 익히면 된다 )
- 액티비티 : 사용자 인터페이스를 구성하는 기본 단위이며, 눈에 보이는 화면 하나가 액티비티이며, 여러 개의 뷰들로 구성, 응용 프로그램은 필요한 만큼의 액티비티를 가질 수 있으며 그 중 어떤 것을 먼저 띄울지를 지정
- 서비스 : UI가 없어 보이지 않으며 백그라운드에서 무한히 실행되는 컴포넌트, 액티비티와 연결해서 사용함
(ex> 미디어 플레이어는 비활성화된 상태라도 노래는 계속 재생되어야 한다)
- 방송수신자(Broadcast Receiver) : 시스템으로부터 전달되는 방송을 대기하고 신호 전달 시 수신하는 역할
(ex> 배터리가 떨어졌다, 사진을 찍었다, 네트워크 전송이 완료되었다 같은 신호 받음)
- 콘텐츠 제공자(Content Provider) : 다른 응용 프로그램을 위해 자의 데이터를 제공, 응용 프로그램 간에 데이터 공유
Manifests : XML 파일로 구성 컴포넌트, 앱에 대한 전반적인 정보 Java : 소스 파일들이 저장 generatedJava : Java 관련 라이브러리 (터치할일 거의 x) Res : 외부의 다양한 리소스들 저장하기 위한 폴더 Gradle scripts : Gradle이 빌드시에 필요한 스크립트(Java는 Marven, 안드로이드는 gradle)
트랩은 커널공간과 사용자공간을 나누어서 접근할 수 있는 권한설정에서 매우 중요한 역할을 한다.
-> CPU는 CPU나름 입출력장치는 입출력장치 나름대로 데이터를 출력하고 메모리 어느 곳에 데이터를 얹어놓는데 이곳이 버퍼이다. 양쪽이 분리되어 동작하고 서로 소통은 CPU를 통해 진행한다.
- 문제는 주컴퓨터 CPU가 부하가 걸린다(operator가 있을땐 나눌 수 있었는데 operator를 없애다 보니까 CPU가 과부하)
-> 해결 : 입출력장치와 CPU가 각자의 간섭없이 작업을 하도록 하고, 그동안 입출력장치가 컴퓨터 메모리상의 약속된 장소를 직접 접근하면서 입출력을 끝내도록 하고, 그 작업이 끝나면 CPU에 알리도록 해서 CPU가 다음 입출력 작업을 지시하도록 한다.
일괄처리시스템에서 모니터의 태동 : operator 자동화를 위해서는 메모리에 상주하는 프로그램이 필요하다
-> operator 대신 프로그램이 메모리에 올라가 있어야 되기 때문( ex> ISR, 적재기, JOB Sequencer, 제어카드 번역기)
상주모니터(Resident Monitor)
- 컴퓨터가 시동되는 시점부터 메모리에 탑재되어서 영구적으로 상주해야되는 것들
- 인터럽트 처리기 또는 입출력 관리자를 메모리에 영구적으로 상주시켜야 할 필요성 대두
- 작업 제어 명령어, 적재기, 작업 순서 제어기를 상주시켜 컴퓨터의 운영을 좀더 자동화 시킴
보호 이슈 >>
- 모니터가 메모리에 상주하는데 메모리에는 모니터도 있지만 채널을 통해서 버퍼에 들어오는 것이 프로그램이 탑재되어 들어올 수도 있다.
-> 다른 프로그램이 메모리 한 부분에 위치하게 되어서 CPU에 의해서 수행될 수도 있다. (ex> 사용자 프로그램들)
-> 이 프로그램을 수행하다가 모니터의 영역을 침범하는 경우가 생긴다 (즉, 덮어쓰는 경우가 생겨서 상주 모니터 보호의 필요성 대두된다)
특히 입출력할 때 자주 발생해서 이를 방지하기 위해 모든 사용자 프로그램은 입출력을 직접 하지 않고 반드시 모니터가 제공하는 입출력 함수를 호출해서 입출력하도록 했다 (-> 시스템 콜의 태동) ex> fork() 함수
(시스템 콜 : 커널 내의 함수를 응용 프로그램이 불러 쓰는 것)
-> 미리 작성된 테이블에 기록된 메모리 접근 허용치(사용자 프로그램이 접근할 수 있는 메모리 영역 허용치) 참조하여 각 연산 수행 시 메모리 접근 범위를 제한한다.
일괄처리시스템의 장점
- 초기 일괄처리 시스템에 비하여 효율성 개선됨(효율성 높이는데 큰역할)
- 하나의 작업이 CPU를 독점하므로 해당 작업으로 볼 때는 처리 속도가 가장 빠르다 (프로그램이 자원 독점)
- 사용자와의 대화가 필요하지 않은 CPU-bound 응용 프로그램 수행에 적합하다 (수치 계산, 대용량 데이터 처리 등)
단점
- 사용자와의 대화가 필요한 요구들이 많을때(ex> 편집기 ) 이것을 수행하기에는 부족하다
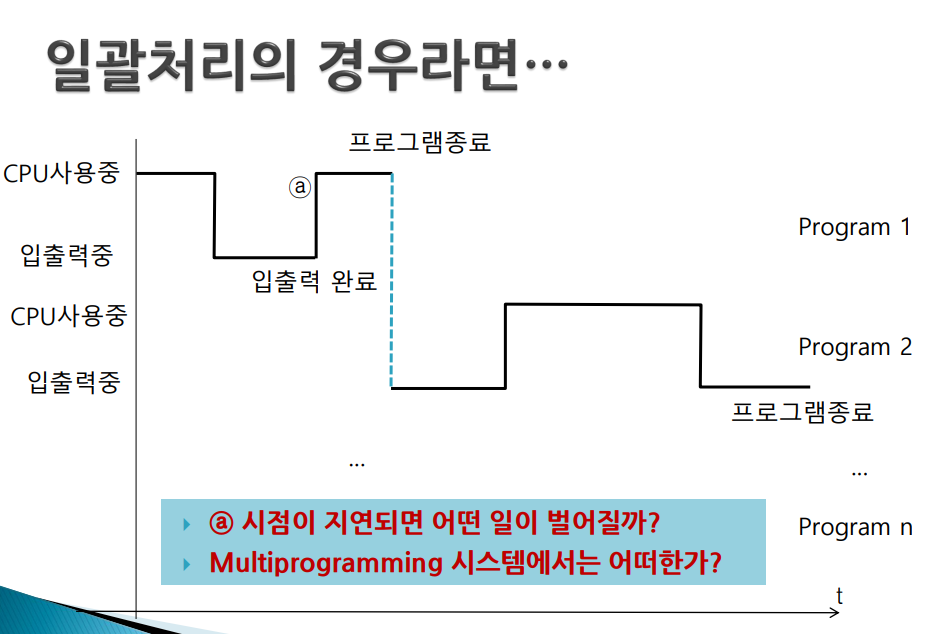
- 일괄 처리 시스템은 한 작업, 한 작업을 순차적으로 처리 -> 한 프로그램이 입출력을 위해 소모한 시간은 다음 프로그램에게는 기다리는 시간(즉, 전체 처리량 저하)
--> 그렇다면 여러 프로그램을 동시에 실행시키면??
다중 프로그래밍(Multiprogramming)
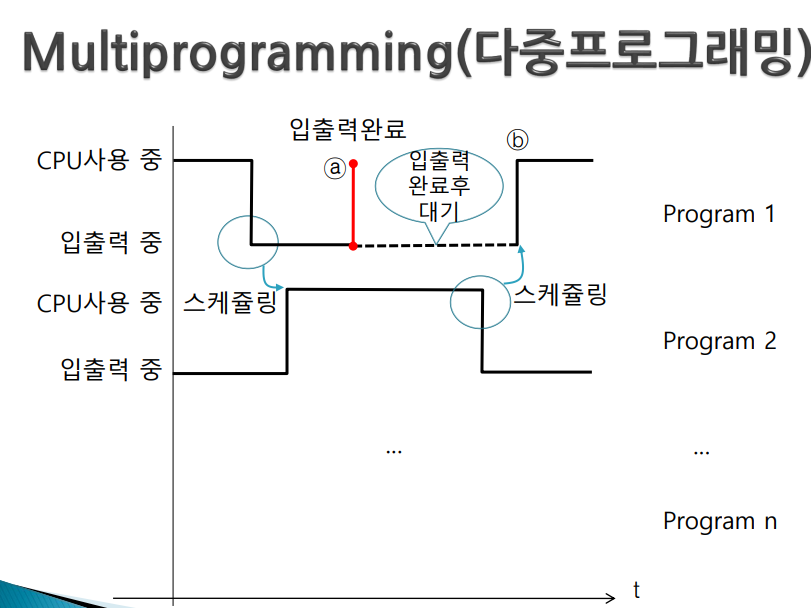
다중 프로그래밍은 일괄처리시스템과 달리 프로그램을 번갈아 수행한다
- 프로그램을 수행하다보면 어느 순간 입출력이 일어남(키보드 입력을 기다리거나 출력이 끝나기를 기다리는 상태에 도달)
-> 입력이 들어오기까지 마냥 기다리는 것이 아니라 입력이 들어오면 interrupt를 걸도록 해놓고 그 사이 다른 프로그램 선택해 수행 (이걸 모든 프로그램에 적용하면 번갈아가며 수행시킬 수 있게 된다)
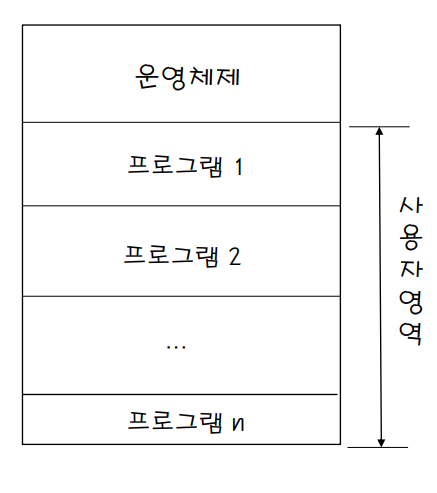
- 한 시점에 여러 프로그램을 사용자 영역에 탑재
-- 시스템에 들어오는 모든 작업은 일단 작업 풀(디스크 사용)에 적재됨
--작업풀 내의 작업은 운영체제의 정책에 따라 선택되어 메모리에 탑재
- 탑재된 작업 중 하나를 선택하여 실행한다
- 한 프로그램이 입출력을 하는 동안 다른 프로그램을 선정하여 CPU가 실행한다(이것이 스케쥴링, 어떤것 선정이 좋을지 정책 필요)
- 스케쥴링이 언제 일어나냐 -> 다중 프로그래밍인 경우 수행중이던 프로그램에서 입출력이 일어날 경우에만 스케쥴링이 일어난다.
(- 시분할 시스템에서도 스케쥴링 일어나는데 차이 구분하면??)
- 만약 program2에 문제가 있어 무한 loop 돈다(program1은 cpu 받기를 기다리고 있다) -> 스케쥴링은 입출력 변할때만 이루어지니까 program2가 무한루프를 돌면 입출력을 하는 순간은 오지 않는다. 즉, 입출력 요구하는 상황이 벌어지지 않는다 -> 스케쥴링도 일어나지 않는다 -> program1 영원히 대기
- 그래서 다중 프로그래밍인 경우 프로그램 간섭이 일어날 수 있다
1. 스케쥴링은 입출력이 일어났을때만 된다 2. 프로그램 간의 간섭이 일어날 수 있다
-> 대부분 프로그램의 실행 시간에서 CPU의 사용 시간은 극히 일부분이고 나머지는 입출력 시간이다.
-> N개의 프로그램이 실행된 시간이 각각 t1, t2, ... ,tn이라 할 때,
- 일괄처리 또는 uniprogramming : t1+t2+t3+... +tN
- 다중프로그래밍인 경우 대략 : max(t1,t2,,,,tN)
- 한 프로세스의 입출력 시에 다른 프로세스를 처리할 수 있게 되므로, CPU가 항상 일을 하고 있게 됨
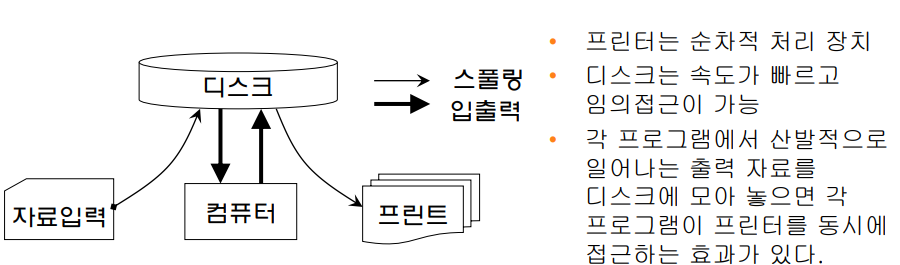
- 또한, 디스크를 이용한 Buffering과 Spooling으로 입출력과 CPU수행의 중복 정도를 높일 수 있게됨
- Input Spooling은 Job Scheduling에 사용
- Output Spooling은 산발적인 프린트 출력을 모아서 프로세스가 끝난 후에 출력
- 새롭게 대두되는 이슈
- Job Scheduling : 최적의 스케쥴링 방법
- 메모리 경영 - 여러 작업이 메모리 상에 존재, 한정된 메모리 공간에 n개의 프로그램 탑재해야 되기 때문에 어떤 것들을 탑재하느냐에 대한 알고리즘
파이썬은 map, filter와 같은 함수형 기능을 지원하며 다음과 같은 람다 표현식도 지원한다.
list(map(lambda x:x+10,[1,2,3]))
# [11,12,13]
리스트 컴프리헨션
리스트 컴프리헨션이란 기존 리스트를 기반으로 새로운 리스트를 만들어내는 구문으로, 파이썬 2.0부터 지원되었으며 파이썬의 대표적인 특징이다.
람다 표현식에 map이나 filter를 섞어서 사용하는 것에 비해 가독성이 훨씬 높다.
Ex> 홀수인 경우 2를 곱해 출력하라는 리스트 컴프리헨션
[n*2 for n in range(1,10+1) if n%2 == 1]
# [2, 6, 10, 14, 18]
만약에 리스트 컴프리헨션을 사용하지 않는다면 다음과 같이 작성해야 한다.
a=[]
for n in range(1,10+1):
if n%2 == 1:
a.append(n*2)
파이썬은 리스트만 가능한것이 아니라 딕셔너리도 가능하다.
a={}
for key,value in original.items():
a[key] = value
# 위의 코드를 아래와 같이 바꿀 수 있다
a={key:value for key,value in original.items()}
제너레이터
제너레이터는 루프의 반복 동작을 제어할 수 있는 루틴 형태를 말한다. 예를 들어 숫자 1억 개를 만들어내 계산하는 프로그램을 작성한다고 하였을때 이 경우 제너레이터가 없으면 메모리 어딘가에 만들어낸 숫자 1억 개를 보관하고 있어야 한다. 그러나 제너레이터를 이용하면, 단순히 제너레이터만 생성해두고 필요할 때 언제든 숫자를 만들어낼 수 있다.
기존의 함수는 return 구문을 맞닥뜨리면 값을 리턴하고 모든 함수의 동작을 종료한다. 그러나 yield는 제너레이터가 여기까지 실행 중이던 값을 내보낸다는 의미로, 중간값을 리턴한 다음 함수는 종료되지 않고 계속해서 맨 끝에 도달할 때까지 실행된다.
def get_natural_number():
n=0
while True:
n+=1
yield n
이 경우 함수의 리턴 값은 다음과 같이 제너레이터가 된다.
만약 다음 값을 생성하려면 next()로 추출하면 된다. 예를 들어 100개의 값을 생성하고 싶다면 다음과 같이 100번 동안 next()를 수행하면 된다.
g=get_natural_number()
for _ in range(0,100):
print(next(g))
range()
제너레이터의 방식을 활용하는 대표적인 함수로 range() 가 있다. 주로 for 문에서 쓰이는 range() 함수의 쓰임은 다음과 같다.
list(range(5))
# [0,1,2,3,4]
range()는 range 클래스를 리턴하며, for 문에서 사용할 경우 내부적으로는 제너레이터의 next()를 호출하듯 매번 다음 숫자를 생성해내게 된다.
enumerate()
enumerate()는 '열거한다'는 뜻의 함수로, 순서가 있는 자료형(list,set,tuple)을 인덱스를 포함한 enumerate 객체로 리턴한다.
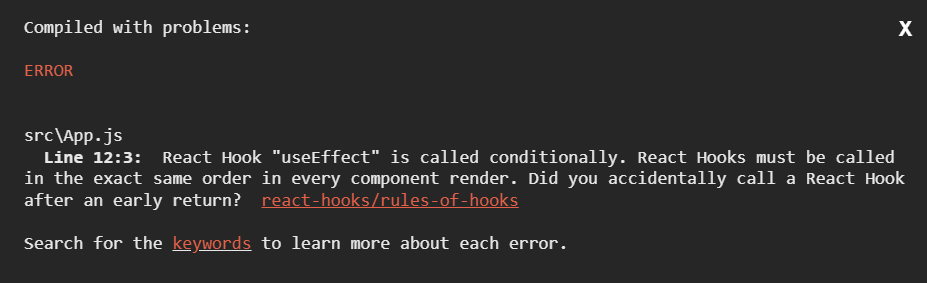
Don't call Hooks inside loops, conditions, or nested functions. Instead, always use Hooks at the top level of your React function, before any early returns.
즉, hook은 문서의 최상단에 어떠한 값이 return 되기 전에 정의 되어야 한다. hook을 사용하기 전에 조건문으로 return 하는 코드가 있으면 에러가 발생하게 된다.
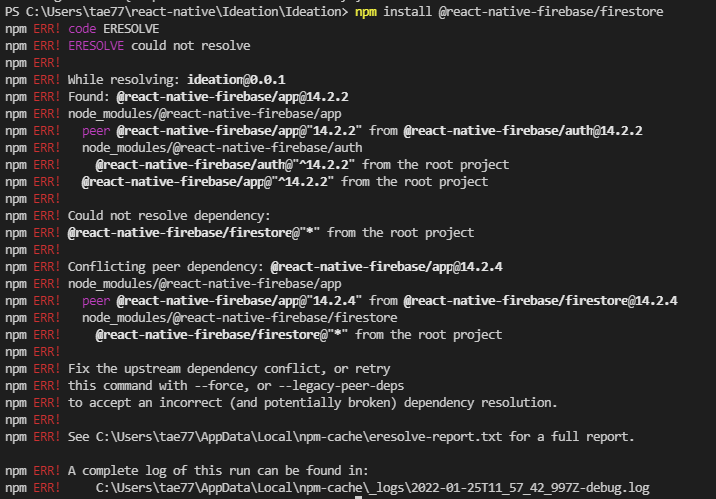
github 작업할 때 @react-native-firebase/auth는 node-module에 있었는데 @react-native-firebase/storage를 설치해서 사용하려고 하니까 설치가 안되는 오류였다.
오류메시지는 Conflicting peer dependecy 와 Could not resolve dependency 였는데 @react-native-firebase안에 이미 auth가 있고 storage가 뭔가 이미 설치된거랑 안맞아서 오류가 생기는 느낌..?(영어 그대로 해석해봤을때..)
요세푸스 문제(https://jobdong7757.tistory.com/113?category=916339)와 비슷했던것 같다. 근데 문제는 여기서 s 배열에 음수가 존재하면 오른쪽이 아닌 왼쪽으로 원을 둘러서 가야된다는 사실이다. 이 부분때문에 헷갈려서 헤매었다. 그리고 처음 시작점이 여기서는 0으로 지정되어있다. 그래서 한번 삭제를 하고 반복문을 돌려주어야 한다.
[나의 해결 방안]
n=int(input())
s=list(map(int,input().split()))
start=0
index=[x for x in range(1,n+1)]
answer=[]
temp = s.pop(start)
answer.append(index.pop(start))
while s:
if temp<0:
start = (start+temp)%len(s)
else:
start=(start+temp-1)%len(s)
temp = s.pop(start)
answer.append(index.pop(start))
for i in answer:
print(i,end=' ')
n과 s는 주어진 입력이고 start에는 다음 지점을 저장해주려고 하였다. index는 정답에 저장하기 위해서(정답은 0 index를 1로 바꿔서 출력해주어야하기 때문)에 사용하였다. temp에는 s배열의 값을 temp에 저장해주었다.
while문을 하기 전에 이 문제는 시작점이 0으로 정해져있기 때문에 start=0으로 초기화 하고 temp는 s의 start값의 index를 pop해서 저장해준다.
while문을 이제 시작할때 temp의 값이 음수일때가 문제인데 이 문제를 python의 나머지 기호(%)를 잘몰랐던 나의 무지였었다.
https://seokdev.site/204 이 사이트에서 다시 공부하고 왔다.. python에서는 c언어의 %와 달리 -1%10을 하면 9가 나오게 된다. 즉, A%B 가 있으면, A에다가 B를 계속 더하면서 처음으로 양수가 되었을 때 B로 나눠 나머지를 준다.
예를 들어 -1%10이면 -1+10=9, 9%10=9 이런식으로 나오는 것이다.
이 문제에서 temp가 음수이면 그냥 start에 temp를 더해서 s의 길이로 나누면 왼쪽으로 -temp만큼 가는것처럼 보이게 되는 것이다. 그래서 temp<0일 때를 처리해 줄 수 있다.
[다른 사람 풀이]
위의 풀이가 temp<0을 처리하기 제일 용이했었는데 그것 말고도 deque에 temp<0을 처리해줄 수 있는 방법도 있었다.
enumerate는 반복문 사용 시 몇 번째 반복문인지 확인이 필요할 때 사용할 수 있다. 이거는 index 번호와 collection의 원소를 tuple 형태로 반환한다.
예를 들어 이런식이다.
t = [1, 5, 7, 33, 39, 52]
for p in enumerate(t):
print(p)
(0, 1)
(1, 5)
(2, 7)
(3, 33)
(4, 39)
(5, 52)
그리고 deque의 rotate() 메서드.
deque.rotate(num)을 하면 deque를 num만큼 회전한다.(양수면 오른쪽, 음수면 왼쪽)
문제가 복잡하게 적혀 있는데 괄호로 표현해주어서 이해하기 쉬웠다. 처음에 생각한것은 쇠막대기와 레이저의 출발과 끝을 따로 배열로 저장해서 하나씩 볼려고 하였다. 물론 직관적으로 바로 풀었는데 O(n^2)이라서 문제 맞추면 더 좋은 풀이 생각해야지 했더니만 역시.. 시간초과가 뜨고 말았다.
[처음 풀이] 예시들은 제대로 출력되지만 더 빠른 방법이 정답일것 같았다.
s=input()
pipe=[]
raser=[]
stack=[]
answer=0
for i in range(len(s)):
if s[i]=='(':
stack.append(i)
elif s[i]==')':
if s[i-1]=='(':
stack.pop()
raser.append((i-1,i))
else:
pipe.append((stack.pop(),i))
for i in pipe:
count=0
for j in raser:
if i[0]<j[0] and i[1]>j[0]:
count+=1
answer+=count+1
print(answer)
괄호는 '(', ')' 두개밖에 없고 '('인 경우는 쇠파이프 1개가 새로 시작하거나, 레이저인 경우밖에 없고, ')'인 경우는 쇠파이프 1개가 끝나거나 레이저인 경우밖에 없으므로 결국 input받은걸 하나씩 분석해가면 O(n)안에 문제를 해결할 수 있다.
[나의 해결 방안]
'('인 경우에는 stack안에 집어넣고 ')'인 경우 앞에 것이 바로 '('이면 레이저이므로 stack에 넣은 '('를 빼내준다. 그리고 레이저로 자르면 되는데 이때는 stack의 크기만큼 나온다.
그리고 ')'를 만났는데 그 앞에게 ')'인 경우는 막대기 하나가 끝난경우로 보면 되므로 stack에서 하나 pop해주고 정답을 +1해준다.
s=input()
stack=[]
answer=0
# '('가 들어오는 경우 -> 쇠파이프 1개가 새로 시작하거나, 레이저인 경우
# ')'가 들어오는 경우 -> 쇠파이프 1개가 끝나거나, 레이저인 경우
for i in range(len(s)):
if s[i]=='(':
stack.append(i)
elif s[i]==')':
if s[i-1]=='(':
stack.pop()
answer+=len(stack)
elif s[i-1]==')':
stack.pop()
answer+=1
print(answer)