UNIX는 입출력 devie의 종류와 상관없이 I/O 사용할 수 있게 System Call 함수 4개를 제공해준다.
이때, 파일이 입출력의 대상이 된다. (Linux에서는 socket도 I/O device 중 하나로 생각하면 된다.)
입출력 장치의 종류와 상관없이 일관된 방법으로 I/O 수행할 수 있도록 UNIX에서는 system call 함수를 제공하고 있다.
먼저 알아두어야 할 용어들을 보자. peripheral device란 컴퓨터의 주변장치(입출력 장치)들을 의미한다. 보통은 모니터, 키보드 등을 의미한다. device driver란 device 제어를 위해 필요한 소프트웨어, hardware access 하기 위한 device driver를 의미한다.
UNIX에서는 Open, Close, Read, Write, (ioctl) 4개의 함수만 있으면 I/O device를 쓸 수 있다. 이런 함수를 사용하기 위해서 모든 device를 file로 다룬다. 모든 device는 file로 표현이 된다. (일반적인 file은 아니므로 special file로 표현한다.)
모든 device들은 /dev 디렉토리 안에 저장되고, 주변장치 hardware resource를 나타내는 special file이다. 여기에는 커널 이미지도 존재한다.
그렇다면 UNIX files은 어떻게 다루어 질까?
파일들은 일련의 byte들의 집합으로 다루어진다. file들도 확장자가 있는것을 볼 수 있는데, 이는 사용자가 구분하기 위한 것이다. 모든 I/O device들은 file들로 존재한다. 그리고 OS의 kernel도 file로 존재한다.
그래서 UNIX시스템에서 파일을 통해 I/O 수행하는 법만 알면 device들도 다룰 수가 있게 되는 것이다.
먼저 file과 open한 file을 구분해야 된다. open 된 파일에 대한 정보가 별도로 관리가 된다.
file이 열리면 open한 파일에 뭘 기대하냐면 file을 읽어 들이던지 쓰던지 해야 한다. 이를 위해 file offset이라는 정보가 유지가 된다.
file offset은 open된 파일에서만 의미가 있다. file offset은 read나 write를 시작할 position지점을 의미한다. file이 open 되면 초기화되어 file offset은 시작 지점인 0이 된다.
임의의 지점에 쓰고 싶으면 lseek 함수를 사용해서 offset 옮겨야 한다.
read() 함수
#include <unistd.h>
ssize_t read(int fildes, void* buf, size_t nbyte);
read함수는 3개의 parameter가 필요하다.
read함수의 return type은 ssize_t. 즉, 숫자 값이 return이 된다.
-1은 error가 발생하면 return 하게 된다.
1. int fildes -> 첫 번째 파라미터
첫번째 파라미터 file descriptor는 file read를 하려면 먼저 open() 함수 써서 open 해야 된다. 그러면 지정된 경로명을 준다. OS가 해당 경로의 파일을 찾아서 open 해주고 open 된 파일에 access 할 수 있는 return값을 준다. 이 return값은 integer타입이다. 이 return값은 filedescriptor라 하는 값에 해당한다. filedescriptor를 통해 kernel이 특정 파일에 접근할 수 있게 된다.
2. void* buf -> 두 번째 파라미터
user가 제공하는 buf는 void*인데 실제로는 파일에다 I/O 하는 단위가 byte단위이다. char type의 배열을 만들어 놓는다.
char buff [array크기]는 file에서 읽어 들인 것을 저장하는 공간이고 file로부터 읽어 들일 데이터 저장할 곳이 된다.
3. size_t nbyte -> 세 번째 파라미터
형식은 unsigned integer이다. 요청하는 byte 수를 의미한다. 이 파일로부터 몇 byte를 fildes로부터 읽어 들일건지 결정한다. 지정한 바이트 수 만큼 첫번째 파라미터로 부터 읽어들여서 2번째 파라미터에 쓴다.
2번째와 3번째 parameter는 연관관계가 있다. 예를 들어, buffer의 크기를 10짜리를 하나 마련했다. 그러면 buf가 가질 수 있는 데이터 크기는 10byte가 최대이다. 그런데 nbyte를 10byte보다 크게 설정하면 읽어들일 수 없다. 그래서 보통 buf의 크기와 nbyte는 같다.
주의해야 할 점은 2번째 parameter는 포인터를 넘기니까 실제 메모리를 할당하고 넘겨야 한다. char* buf 선언만 해 놓고 넘기면 메모리가 없어서 에러가 생긴다. (읽은 값을 저장할 메모리가 없다.)
성공적으로 읽었으면 return 값 ssize_t 값이 return 된다. 실제로 읽어 들인 byte 수가 return 이 된다.
이때, 1byte라도 읽었으면 성공이다. 에러 값은 errno에 설정을 해준다.
read operation을 regular file에서 실행하면 적은 byte가 return 될 수도 있다. 10byte 요청했는데 마지막이 4byte만 남은 경우 4byte만 읽어도 성공한 것이다. (error가 아니다) 10을 요청했는데 4만 반환이 될 수도 있다. read함수는 endoffile 캐릭터 만날 때까지 읽을 수 있는 것이다.
그다음에 또 read함수 호출하면? -> 한byte도 못 읽게 된 경우는 0을 리턴한다.
따라서 0을 리턴한다. -> 읽을거리가 없다는 것을 의미한다.
그래서 반복되는 것을 읽는 종료 조건은 return이 0이 아닐 때까지로 정한다.
File descriptor : open 되어 있는 file을 나타내는 지시자이다.
시스템에서 정의하고 있는 constant 값 : process가 시작이 되면 따로 open하지 않아도 file descriptor가 3가지가 open이 되어 정의가 되어있다. 이 3가지는 open을 하지 않아도 read, write 할 수 있다. 커널이 3개의 파일 device를 표준 입출력 장치에 추가한다.
1. STDIN_FILENO : 키보드에 해당한다. 표준 입력장치에 해당하는 File descriptor constant 값(#define 0)
2. STDOUT_FILENO : 표준 출력장치에 해당하는 모니터이다. (#define 1)
3. STDERR_FILENO : 화면과 똑같은 장치인데 우선순위가 높은 에러 메시지를 출력할 때 사용한다. 표준 에러 장치에 해당한다. (#define 2)(close 해서는 안된다.)
Readline.c
한 줄을 입력받기 위한 함수이다. 임의의 파일로부터 한줄씩 입력받을 수 있고 read함수와 비슷한 방식으로 parameter 양식을 비슷하게 가져간다.
#include <errno.h>
#include <unistd.h>
int readline(int fd, char *buf, int nbytes) {
int numread = 0;
int returnval;
while (numread < nbytes - 1) {
returnval = read(fd, buf + numread, 1);
if ((returnval == -1) && (errno == EINTR))
continue;
if ( (returnval == 0) && (numread == 0) )
return 0;
if (returnval == 0)
break;
if (returnval == -1)
return -1;
numread++;
if (buf[numread-1] == '\n') {
buf[numread] = '\0';
return numread;
}
}
errno = EINVAL;
return -1;
while문을 계속 돌면서 한줄 입력받는다. 한줄을 어떻게 구분할 거냐? -> \n 만날 때까지 하나의 char씩 읽어 들인다.
한 줄을 읽어 들이는 과정의 오류 handling 하는 것이 if문을 통해 구현되어있다.
int numread -> 지금까지 읽어 들인 char 수를 의미 -> 마지막에 return 해줌. -> 실제 read함수와 동일함
int returnval; -> 리턴 값을 저장하기 위한 변수 read함수의 return값을 검사하기 위함
반복의 종료 조건 : while문에서 numread값이 nbyte-1보다 작을 때까지 읽어 들이겠다.
여기서 nbyte와 numread가 같을 때 종료하는 것이 아니라 -1을 하는 이유는 맨 마지막에 null이 들어가기 때문에 null character자리가 필요하기 때문이다.
returnval = read(fd, buf+numread,1); -> 하나씩 읽어들이겠다.
buf+numread의 의미 : array의 index는 0부터 시작하는데 numread에 mapping이 된다. numread++로 하나씩 증가시켜서 읽겠다는 의미이다.
if문들은 에러 핸들링을 위한 조건들이다.
1. returnval ==-1 && errno ==EINTR :
EINTR은 interrupt case를 의미한다. read함수가 -1을 리턴했는데 read함수는 정상적인데 중간에 외부요인을 받아서 return을 못했다는 의미이다(실제 에러 상황이 아님) 그래서 continue로 다시 수행한다. systemcall 함수에서 interrupt를 고려한 코드가 되는 것이다.
2. returnval ==0 && numread==0 :
한 바이트도 읽지 못했다는 것을 의미한다. fileposition이 EOF이기 떄문에. 더 읽을것이 없다. numread=0 인것은 아직 한바이트도 읽지 않았는데 파일 끝을 만난 것이다. -> input file이 빈 파일이 온경우에 해당한다.
3. returnval==0 :
계속해서 읽었는데 읽다가 다음에 읽은 것이 EOF를 만난 것이다. input file이 한 줄에 new line character가 없는 경우이다. 하나씩 잘 읽다가 그다음이 EOF을 만난 경우이다. 한 줄을 다 입력받지 못한 상태. break를 해서 while문을 빠져나가서 errno를 설정하고 -1을 리턴한다.
4. returnval == -1 :
그 외의 다른 에러들 read함수가 내부에서 error가 나서 읽지 못한 경우에 해당한다.
정상적으로 읽었으면 한 바이트 읽고 \n 만나면 numread 자리에 \0(null character)를 집어넣는다. \0을 넣어서 한 줄을 string으로 만들어서 numread를 리턴하겠다. numread값에는 null은 빼고 리턴이 된다. String으로 구성해야 되기 때문에 null character가 필요하기 때문에 while문에서 nbytes - 1을 해준 것이다.
readline함수를 실제로 사용
char mybuf [100]; // 선언하고 시작해야 함.
bytesread = readline(STDIN_FILENO, mybuf, sizeof(mybuf)); // 98개까지 입력을 받겠다.
Read함수라는 것은 3개의 parameter를 필요로 한다.
#include <stdio.h>
#include <unistd.h>
#define BUFSIZE 80
int readline(int fd, char *buf, int nbytes);
int main(void) {
char buf[BUFSIZE];
int num;
while ( (num = readline(STDIN_FILENO, buf, BUFSIZE)) > 0) {
fprintf(stderr,"Number of bytes read: %d\n",num);
fprintf(stderr,"Line:!%.*s!\n",num,buf);
}
if (num < 0) {
fprintf(stderr,"readline returned %d\n",num);
return 1;
}
return 0;
}
fprintf는 젤 앞에 parameter를 추가해서 file에 출력하겠다 라는 의미이다.
c라이브러리에서는 filepointer라는 것을 이용한다.
%.*s는 % s랑 똑같음. 입력받은 내용 계속 출력해주는 것이다.
Write() 함수
#include <unistd.h>
ssize_t write(int fildes, const void* buf, size_t nbyte)
buf 안의 내용을 nbyte만큼 fildes에 쓰겠다는 의미이다.(Read 함수와 반대)
file에 쓰인 byte 수가 return이 된다.
더 적은 byte 수만큼도 쓸 수 있다. 즉, 실제로 쓰이는 것은 n보다 작을 수 있다.
그래서 다 쓰였는지 확인할 필요가 있다. 요청한 byte 수보다 작으면 반복해서 쓰는 작업을 수행해야 할 것이다.
File Offset
: 오픈된 파일에 대해서 수행할 수 있는 것. 파일을 오픈하게 되면 Offset이 초기화 되게 된다. 다음에 수행할 위치를 File Offset이라고 한다. 오픈된 파일은 0byte로 초기화시킨다. 실제 읽은 byte 수만큼 이동하게 된다. 현재 file offset 값은 이동하게 된다. I/O 작업을 수행한 만큼 fileoffset이 이동된다. close 하면 file offset 정보 없어지게 된다.
read, write 사용할 때 read함수에서 읽어들인 byte수를 return 받아서 이 크기만큼 wrtie를 해야지 error가 나지 않는다. 또 interrupt도 고려해서 write함수를 사용한다.
copyfile()
#include <errno.h>
#include <unistd.h>
#define BLKSIZE 1024
int copyfile(int fromfd, int tofd) {
char *bp;
char buf[BLKSIZE];
int bytesread;
int byteswritten = 0;
int totalbytes = 0;
for ( ; ; ) {
while (((bytesread = read(fromfd, buf, BLKSIZE)) == -1) &&
(errno == EINTR)) ; /* handle interruption by signal */
if (bytesread <= 0) /* real error or end-of-file on fromfd */
break;
bp = buf;
while (bytesread > 0) {
while(((byteswritten = write(tofd, bp, bytesread)) == -1 ) &&
(errno == EINTR)) ; /* handle interruption by signal */
if (byteswritten < 0) /* real error on tofd */
break;
totalbytes += byteswritten;
bytesread -= byteswritten;
bp += byteswritten;
}
if (byteswritten == -1) /* real error on tofd */
break;
}
return totalbytes;
}
cp 명령어를 read,write 함수로 구현한 것이다.
fromfd를 읽어서 tofd로 copyfile을 한다. 둘 다 open을 먼저 하고 넘겨주면 된다. 소스파일 read, 타깃 파일에 write.
char buf [BLKSIZE] : 여기 읽어서 저장
bytesread : read함수의 return값
byteswritten : write함수의 return 값 저장
totlabytes : 소스파일의 크기가 같아진다. // copyfile의 return값
write 할 때 요청하는 블록 크기만큼 안 쓰이고 일부만 되는 경우 계속 write함수 호출해서 buffer다 될 때까지 write함수 반복한다. 소스파일의 내용을 다 타깃 파일로 쓰면 for문 빠져나온다.
interrupt에 대한 것도 고려해 주었다.
for문 진입, read 해서 블록을 읽는다. read에서 읽은 값이 <=0 : 에러 상황 or endoffile 만났을 때
bp는 buffer내부를 가리키는 포인터이다. 처음 bp값은 buffer와 동일하다. bp를 buff안에서 계속 이동시킨다. bp 포인터값을 이동시킴. 더 써야될 내용 있는지도 확인. 쓴 바이트 수만큼은 뺀다. 1024에서 1000만큼 썼으면 빼서 bytesread에 저장. bp는 다음에 시작할 데이터 값 위치를 저장해줌.
bp로 실제 써야될 부분으로 옮겨준다.
r_read(), r_write()
#include <errno.h>
#include <unistd.h>
ssize_t r_read(int fd, void *buf, size_t size) {
ssize_t retval;
while (retval = read(fd, buf, size), retval == -1 && errno == EINTR) ;
return retval;
}
interrupt로 인해 중단되었을 경우 다시 read하는 것으로 짜여짐.
#include <errno.h>
#include <unistd.h>
ssize_t r_write(int fd, void *buf, size_t size) {
char *bufp;
size_t bytestowrite;
ssize_t byteswritten;
size_t totalbytes;
for (bufp = buf, bytestowrite = size, totalbytes = 0;
bytestowrite > 0;
bufp += byteswritten, bytestowrite -= byteswritten) {
byteswritten = write(fd, bufp, bytestowrite);
if ((byteswritten == -1) && (errno != EINTR))
return -1;
if (byteswritten == -1)
byteswritten = 0;
totalbytes += byteswritten;
}
return totalbytes;
}
요청한 바이트 수만큼 write한다. 쓰여질때까지 계속해서 반복한다.
readwrite()
#include <limits.h>
#include "restart.h"
#define BLKSIZE PIPE_BUF
int readwrite(int fromfd, int tofd) {
char buf[BLKSIZE];
int bytesread;
if ((bytesread = r_read(fromfd, buf, BLKSIZE)) == -1)
return -1;
if (bytesread == 0)
return 0;
if (r_write(tofd, buf, bytesread) == -1)
return -1;
return bytesread;
}
한 블럭을 읽어서 타겟타일로 써주는 함수. copfile은 전체를 쓴다는것에 차이가 있음.
buf의 크기를 PIPE_BUF로 정의해서 사용했음. write함수도 targetfile로 쓰게되었으면 중간에 방해받는 경우 없도록 도와준다.
copyfile()
#include <unistd.h>
#include "restart.h"
#define BLKSIZE 1024
int copyfile(int fromfd, int tofd) {
char buf[BLKSIZE];
int bytesread, byteswritten;
int totalbytes = 0;
for ( ; ; ) {
if ((bytesread = r_read(fromfd, buf, BLKSIZE)) <= 0)
break;
if ((byteswritten = r_write(tofd, buf, bytesread)) == -1)
break;
totalbytes += byteswritten;
}
return totalbytes;
}
file copy하는것을 더 간단하게 만듬.
readblock()
#include <errno.h>
#include <unistd.h>
ssize_t readblock(int fd, void *buf, size_t size) {
char *bufp;
size_t bytestoread;
ssize_t bytesread;
size_t totalbytes;
for (bufp = buf, bytestoread = size, totalbytes = 0;
bytestoread > 0;
bufp += bytesread, bytestoread -= bytesread) {
bytesread = read(fd, bufp, bytestoread);
if ((bytesread == 0) && (totalbytes == 0))
return 0;
if (bytesread == 0) {
errno = EINVAL;
return -1;
}
if ((bytesread) == -1 && (errno != EINTR))
return -1;
if (bytesread == -1)
bytesread = 0;
totalbytes += bytesread;
}
return totalbytes;
}
r_read()함수를 개선했음. r_read()는 interrupt만 고려, 요청한 바이트수만큼 읽을때까지 반복해서 수행한다. 요청한 바이트수만큼 읽지못하면 error가 발생함. end-of-file 처음에 만나면 0반환.
for문을 돌면서 size만큼 for문을 돌면서 읽도록 한다. 다 읽으면 totlabytes를 리턴한다.
Open() 함수
open 함수는 2가지 버젼이 있다.
#include <fcntl.h>
#include <sys/stat.h>
int open(const char* path, int flag);
int open(const char* path, int flag, mode_t mode);
기존에 만들어 놓은 파일 오픈하는 방법과 새로 파일을 생성해서 오픈하는 방법이 있다.
오픈하려고 하는 파일 char 배열으로 주고, flag변수는 오픈할 때 어떤 모드로 오픈할지 알려준다. flag argument는 OR(|)을 사용하여 access모드와 부가적인 option을 지정할 수 있다.
2번째 버젼은 mode라는 파라미터가 하나 더 붙는다. mode_t는 permission 정보. 처음에 파일 만들때 access permission 이 무조건 필요하다.
어떤 사용자가 access할 권한은 3가지 (읽기,쓰기,실행권한)이다. 3가지 권한을 3가지 종류의 사용자(owner, 동일 그룹 사용자, 그 외 다른 사용자)에게 부여한다. 세 종류의 사용자.
open함수가 성공적으로 open하면 filedescriptor가 return된다. filedescriptor는 open된 파일을 가리키는 지시자. 만약 에러가 발생하면 -1을 리턴하고 errocode가 설정이 된다.
Flag
access mode는 셋중하나로 설정해야 한다.
O_RDONLY : read only
O_WRONLY : write only
O_RDWR : read and write
Additional flags : OR operation을 통해서 조합해서 사용할 수 있다.
O_APPEND : file offset값의 시작점을 가리킨다. file을 open되었을때 file안에 내용이 쓰여져 있으면, write함수 호출할 때 이 flag로 open하면 endoffile로 이동해서 write를 시작하도록 한다. (원래는 offset은 그냥 0으로 설정되어있음) write랑 같이 사용한다.
ex> O_WRONLY | O_APPEND 이렇게 사용
O_TRUNC : write관련 모드인데, 내용이 있는 file을 오픈할때 내용을 다 제거하고 open한다. 파일을 삭제한게 아니고 파일안에 새로운 데이터를 채우고 싶을때 기존의 내용은 지우고 사용할 수 있게 해준다.
O_CREAT : 새로 파일을 생성해서 open하고자 할때. 해당 경로로 주어진 파일이 존재하지 않는 경우 생성해서 오픈해 준다. 새로 파일을 만드는 것이기 때문에 open모드의 2번째 함수를 적용해서 파일이 없는 경우 새로 만들고 access permission권한이 적용된 파일이 생성되서 오픈된다.
이 모드 사용할 때 생각해야 될 것이 temp.txt 파일이 이미 존재한다면 어떻게 될까??
이때는 creat 모드가 무시가 된다. 새로 생성이 안되고 그냥 오픈이 된다. temp.txt 라는 파일을 새로 만들어서 사용하려고했는데 이미 존재한다면 이 위에다 새로운 내용을 write해서 덮어쓰면 기존 내용 지워질 수 있어서 위험성이 있다. 기존 내용이 없어질 수가 있으니까 O_CREAT모드와 O_EXCL모드를 같이 사용해준다.
O_EXCL : create모드를 썼는데 temp.txt가 존재하면 O_EXCL이 error을 낸다. (같은 파일이 이미 존재합니다!) -> O_CREAT와 같이 조합해서 쓰도록 하자.
Question> 파일 오픈하는 요구사항이 주어지고 어떻게 오픈해야 할까 생각해보기.
CASE>존재하는 파일에 덮어쓰는것을 피하고 싶다. --> O_CREAT | O_EXCL 를 사용하여 오픈함수가 에러를 내게끔한다.
O_APPEND의 활용
char buffer[BSIZE];
write(fd,buffer,BSIZE);
1>O_APPEND 없을경우 : 기존 FileOffset지점부터 쓰인다.
2>O_APPEND 있을경우 : offset이 먼저 이동하고 buffer의 내용을 쓰게 된다.
Permission mask : 새로 파일을 만들경우 무조건 줘야한다.(Open함수 2번째 방법의 3번째 파라미터)
permission은 ls -l 했을때 젤 왼쪽에 permission정보랑 같다.
O_CREAT 쓸때 세번째 파라미터로 mode_t 모드 타입으로 지정하고 mode_t 모드는 숫자로 할 수 있다. permission 어떻게 표현되는지 살펴봐야 한다. 권한 하나가 bit하나를 나타낸다. user group others 이렇게 3개 사용자이면 9개의 bit가 필요하다. 사용자별로 묶어서 3bit씩 access 권한을 표시한다(읽기, 쓰기, 실행) 각 사용자에 대해서 3bit로 표현되는 권한의 가지수는 8개가 나온다. 한 사용자를 숫자로 표현한다. ex> 644, 755 숫자말고도 POSIX symbolic name으로 주어진다.
예를 들어, info.dat를 만들어서 오픈하고 싶다. 오픈할 때 이미 존재하면 덮어쓰고 싶다. 그리고 새로운 파일은 user에게는 read,write되고 나머지 사용자는 read만 하게 하고 싶다.
--> O_CREAT 모드만 적용하고 O_EXCL모드는 사용 안하고 644 권한을 주면 된다.
open("info.dat",O_RDWR|O_CREAT,fdmode));
mode_t fdmode = 644;
644권한이라는 것은 owner는 110, group은 100, others는 100 권한이므로 owner는 read,write permissions을 가지고, group과 others는 only read만 할 수 있다.
int fd;
mode_t fdmode = (S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH);
if((fd=open("info.dat",O_RDWR|O_CREAT,fdmode))==-1)
perror("faild to open info.dat");
숫자말고 POSIX symbolic names를 사용하려면 sys/stat.h 헤더파일을 include를 하여 사용하자.
copyfilemain.c
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include "restart.h"
#define READ_FLAGS O_RDONLY
#define WRITE_FLAGS (O_WRONLY | O_CREAT | O_EXCL)
#define WRITE_PERMS (S_IRUSR | S_IWUSR)
int main(int argc, char *argv[]) {
int bytes;
int fromfd, tofd;
if (argc != 3) {
fprintf(stderr, "Usage: %s from_file to_file\n", argv[0]);
return 1;
}
if ((fromfd = open(argv[1], READ_FLAGS)) == -1) {
perror("Failed to open input file");
return 1;
}
if ((tofd = open(argv[2], WRITE_FLAGS, WRITE_PERMS)) == -1) {
perror("Failed to create output file");
return 1;
}
bytes = copyfile(fromfd, tofd);
printf("%d bytes copied from %s to %s\n", bytes, argv[1], argv[2]);
return 0; /* the return closes the files */
}
입력 : copfilemain temp.c target.c
앞에서 봤던 copyfile함수도 이용 -> open을 어떻게 했느냐
copyfilemain temp.c target.c --> argument 3개 필요 --> 잘들어왔는지 check
argv[1] ==> 읽기 전용으로 열겠다
argv[2] ==> 쓰기 전용 새로 만들고 덮어쓰기 x
Closing함수 : close() -> 오픈된 파일에 대한 정보를 반환한다.
#include<unistd.h>
int close(int filedes);
copyfilemain.c는 copy를 하기 위해 2개의 파일을 open해서 사용한다. 다하고 난 다음에 close를 해야한다. 다른 task를 진행하는데 close를 하지않고 계속 실행하면 open하는데 사용된 메모리가 계속 남아있는채로 진행되기 때문에 메모리를 불필요하게 나둔채로 진행하면 낭비가 된다. 불필요하게 사용되는 메모리가 많아진다.
r_close()
#include <errno.h>
#include <unistd.h>
int r_close(int fd) {
int retval;
while (retval = close(fd), retval == -1 && errno == EINTR) ;
return retval;
}
retval에 return 값 받아서 close한다. EINTR이고 -1이면 외부 interrupt에 의한 종료이기 때문에 다시 close하겠다.
lseek 함수
: file을 오픈하고 난 다음에 file offset을 임의의 위치로 옮기기 위해 사용한다.
순차적으로 I/O 가 이동하는 것인데 몇 byte떨어진 지점을 읽고 싶다고 하여 이동시켜야할 필요가 생길 때 사용한다.
#include<sys/types.h>
#include<unistd.h>
off_t lseek(int filedes, off_t offset, int start_flag);
첫번째 파라미터 : int filedes : 해당 open된 파일
두번째 파라미터 : fileoffset 몇 byte를 옮길 것인지. -> 부호가 나타내는 것은 fileoffset의 이동방향
세번째 파라미터 : start_flag -> 2번째 파라미터의 값만큼 이동시키는데 기준점을 나타낸다. constant로 3개 지정되어있다. 현재 fileoffset위치에서 옮기는데 SEEK_CUR이면 file offset로부터 2번째 파라미터 값만큼 옮기겠다.
SEEK_SET : file beginning
SEEK_CUR : File Offset
SEEK_END : File end
ex> lseek(fd, 10, SEEK_CUR) : fd를 현재 fileoffset위치로부터 오른쪽으로 10만큼 이동하겠다.
SEEK_END에서 부터 10만큼 이동하게 할 수도 있다 -> 파일 확장 expanding file is possible
return 값은 최종적으로 이동된 file offset값이 된다.
File representation
file open 하게 되면 open 된 파일에 대한 정보가 어떻게 관리하는지 (File descriptors , File pointers)
open함수를 호출했을때 리턴값 : File descriptors
open함수를 사용하지 않고 File pointers 사용 -> c라이브러리에서 제공하는 파일 포인터가 리턴됨
File pointer안에 File descriptor가 있다고 생각하면 된다.
ex> FILE* fp
사용이 유사하나 차이점이 있다.
file descriptor 중에서도 표준 입출력 장치 file descriptor는 constant값으로 open된 파일의 I/O 작업을 수행하는것이다.
File descriptors : 3종류의 table의 역할을 이해해야한다.
File이 open 되었을때 내부적으로 사용하는 table
process마다 가지고 있는 table : File descriptor table
1. File descriptor table : process가 오픈한 파일에 대한 정보 가지고 있음. 처음 3개의 entry는 kernel에 의해 자동으로 채워진다. STDIN, STDOUT, STDERR. 커널이 알아서 오픈해준다. filedescriptor값은 결국에 정수값이다. 결국 file descriptor의 index값을 의미한다. STDIN은 0번, STDOUT은 1번, STDERR은 2번으로 인덱스 값을 의미하게 된다. entry의 값은 다음 system file table entry를 가리키는 포인터가 되는 것이다. 그 다음에 오픈 함수를 호출한 것이다(앞에 3개, 2번까지의 것은 process 생기면 추가되어있음) 이 프로세스의 file descriptor의 index가 filedescriptor다.
2. system file table도 오픈할 때마다 추가된다. 이 entry를 file descriptor table이 가리킨다. 대표적으로 fileoffset값이 저장되는데 처음에 0으로 초기화 된다. 그리고 open된 파일에 대한 정보, access 정보가 저장된다. file descriptor table 여러개가 system file table을 가리킬 수 있다(fork()의 경우 가능) ---> count 정보도 들어가있다. count의 의미는 몇개의 file descriptor file이 나를 가리키냐에 해당한다.
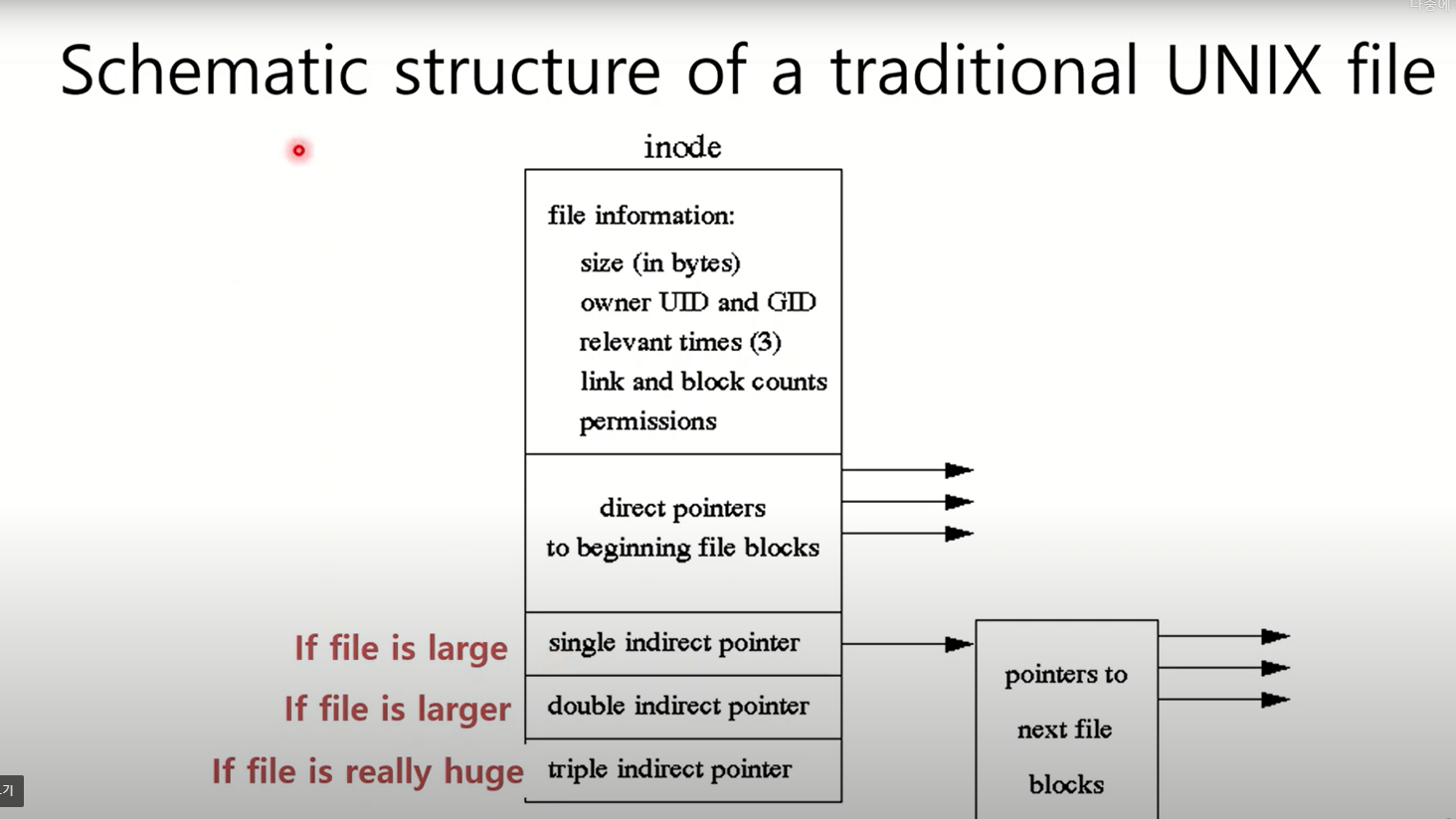
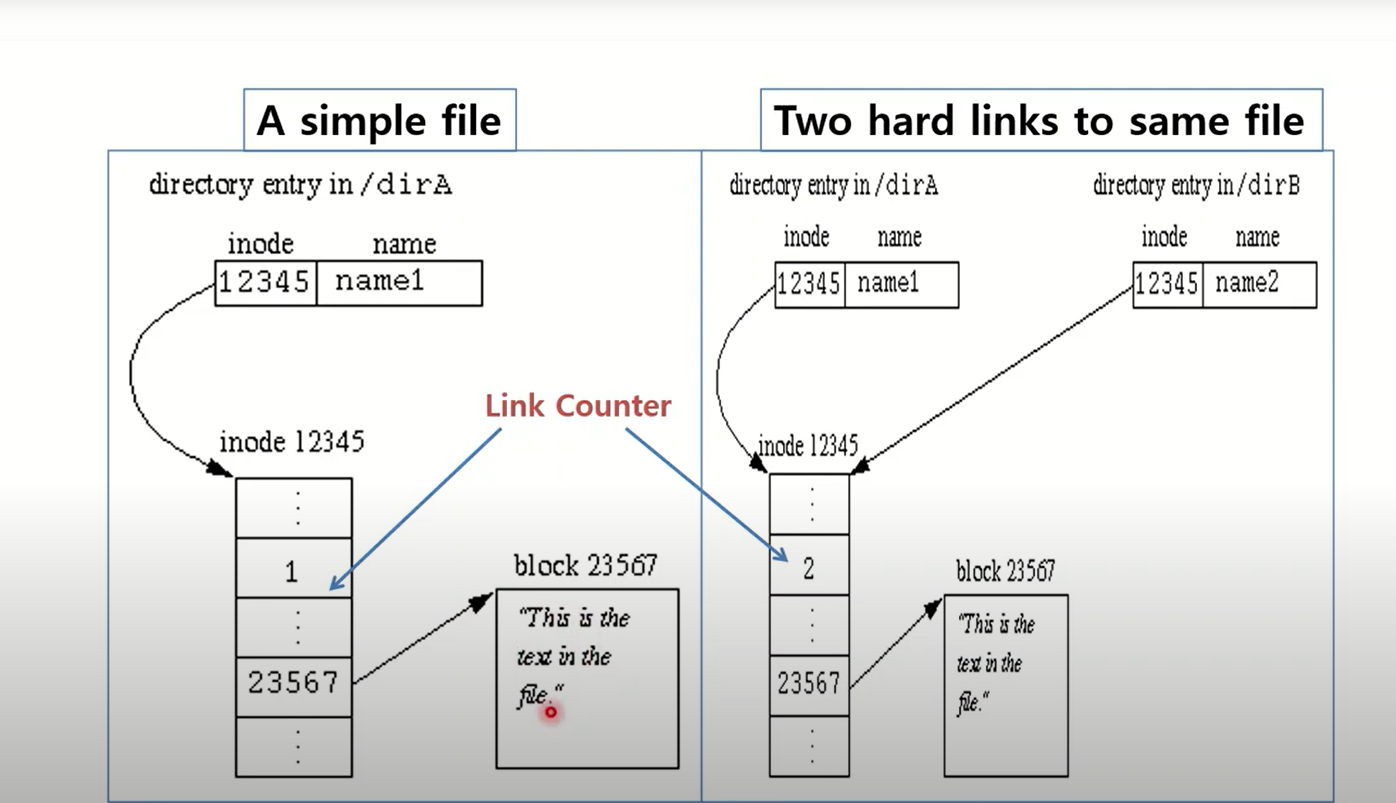
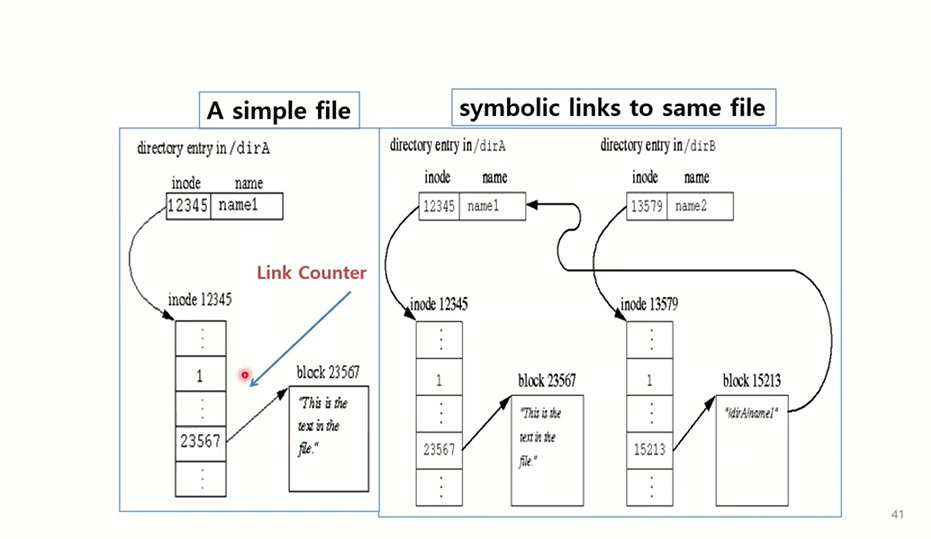
3. In-memory inode table : 오픈된 실제의 파일이 있을텐데 , 그 파일에 대한 정보는 별도의 공간에 유지가 되고 있다. 그 파일에 대한 위치. open된 파일이 아니라 원래 파일에 대한 정보를 담고 있는 inode로 갈 수 있는 정보가 여기에 유지된다. inode안에 파일 관련 meta info를 저장하고 count값도 저장된다.
파일을 open하게 되면 3개의 table에 하나씩 추가되게 된다. inode로부터 실제 파일의 내용도 찾아갈 수있다. open된 파일에 대한 정보와 원래 파일에 대한 정보는 다르다. inode안에 실제 파일의 컨텐츠들을 가질수있는 pointer도 저장되어있다. 별다른 블럭에 존재한다. 실제 컨텐츠는 하드디스크에 있다. 예를 들어, write함수로 "abc"를 쓰겠다고 할때 descriptor table entry -> system file table -> in-memory inode table에 실제 파일로 가서 쓰게 된다. 쓴만큼 fileoffset은 자동으로 업데이트된다. in-momery inode에도 count값이 있다. 여러 개의 systme file table이 가리킬 수 있기 때문이다. 예를 들어 또다른 process가 같은 파일 open하면 system file table 여러 개가 in-memory inode table 동일한 entry를 가리킬수있다. in-memory inode에는 실제 active file로 찾아갈 수 있는 정보 포함되어 있다.
Qusetion>
1> 프로세스가 close(myfd) 호출해서 닫으면 어떤일이 생길까? --> file descriptor table에서 해당 index 삭제한다. 그리고 systemfile table에서 count값을 하나 감소시킨다. (바로 entry가 삭제되는 것이 아니다) count값이 0이되면 system file table의 해당 entry를 삭제한다. in-memory inode의 count값도 감소시킨다. inmomery도 count값이 0이되면 삭제되는 것이다. close를 호출하면 filedescriptor는 바로 삭제되지만 나머지는 count가 감소하게된다.
2> 두개의 process가 같은 파일을 오픈해서 write함수로 쓰게 되면?
- p에서는 "abc"를 my.dat에 쓰고 p`은 "123"을 my.dat에 쓴다. 각각 별도의 file offset을 가지게 된다. 기존 abc의 내용이 사라지고 123을 덮어쓴다(하나의 시나리오이고 꼭 이렇게 되는건 아니다. 확실한건 3byte만 쓰여진다.) 앞서 쓴 내용을 뒤에 쓴 process가 덮어쓰게 된다. 어쨌든 3byte만 쓰여진다. 어떤 프로세스가 나중에 쓰여지냐에 따라 달라짐. 왜냐하면 separate file offset을 가지기 때문이다.
3> 만약에 file offset값이 inode table에 있다면?
in memory inode table에 file offset에 있다면 두 개의 process가 하나의 file offset을 공유하게 되어서 덮어쓰는 것이 되지 않는다. 2개의 process가 서로 이어져서 쓰여진다.
언제 다른 process의 file descriptor table이 system file table 같은entry를 가리킬까?
- 1번째 파일이 open하고, p가 fork해서 자식프로세스를 만들면 동일한 system file table entry를 가리킨다.
File pointers : FILE structure를 가리키는 것
FILE* myfp;
if((myfp = fopen("/home/ann/my.dat","w"))==NULL)
perror("failed to open /home/ann/my.dat");
else
fprintf(myfp,"This is a test");
FILE structure는 buffer를 가지고 있다. FILE structure는 buffer공간이 있고 buffer이외에 file descriptor를 가지고 있다. 이 FILE structure에 대한 포인터가 File pointers 가 된다. 버퍼 공간을 가지고 있다는 것이 핵심이다.
fopen 의 리턴값으로 FILE*를 리턴받는다. fprintf는 파일에 출력하고 싶을때 사용한다. file 포인터로 쓰게되면 버퍼를 가지고 있으므로 fp가 가리키는 파일에다가 쓰게되면 직접 쓰여지는것이 아니고 buffer에 계속 쓰여지게 된다. buffer가 가득차게되면 실제 쓰여지게 된다.
그렇다면 buffer를 중간까지 채우고 쓰고 싶으면 어떤 방법을 써야될까?
-> 조금만 채워졌더라도 쓰여지게 할 수 있는 함수는 fflush함수를 사용하여 강제로 buffer를 비워주면 된다.
buffer가 가득차게 되면 file descriptor를 통해서 쓰이게 된다.
terminal 파일에다 내용을 쓰면 line buffered된다. 즉, 줄바꿈되면 buffer가 한줄 내용이 출력이된다. 라인단위로 buffer된다. standard output은 라인단위, standard error장치는 버퍼링 과정없이 바로 출력이 된다. standard erro가 standard output보다 우선순위가 높다 -> 빨리 출력이 된다.
C라이브러리 함수를 통해서 오픈하면. fopen으로 open하고 file pointer리턴값이 저장된다. 2개의 parameter가 필요하다. 파일의 경로명과 access 모드. 성공적으로 open이 되면 entry가 하나 추가 되고 system file table에도 entry가 추가. my.dat가 최초로 open된것이면 inode table에도 추가. my.dat로 찾아갈 수 있다.
entry의 index가 file descriptor다. file structure가 생성된다. myfp를 통해서 my.dat에 access할 수 있다. file descriptor도 file pointer안에 포함이 된다.
fopen에 에러가 발생하면 null값이 반환된다. file pointer에 쓰겠다. fully buffered가 된다. buffer에 일단 쓰여진다. 다른 작업 수행하고 정상적으로 종료되면, fp가 가리키는 buffer가 비워진다.
Inhertance of file descriptors
부모와 자식 process 간에 file descriptor 관계. my.dat라는 파일안에 "ab"가 들어있다고 가정.
부모와 자식이 같은 파일로부터 1byte읽었을때
1. open하고 fork : 부모의 filedescriptor값을 그대로 받는다. 동일한 system file , 동일한것 가리키게됨.
-> 부모가 read한것과 자식이 읽은 것과 같음. 부모가 "a"을 읽고 fileoffset은 1로 update. 자식은 그럼 여기서 읽으니까 b를 출력.
2. fork하고 open : 부모 프로세스부터 실행한다고 가정하면, open my.dat오픈하고 entry하나 추가 되고, sft에도 추가되고, inode에도 추가되고 my.dat에 a캐릭터를 읽어서 출력한다. 자식프로세스도 fork함수 다음에 별도로 오픈하겠다 sft에 별도의 entry가 추가된다.
-> 부모와 공유하지 않게 된다. in-memory inode table은 같은 것을 가리키게 된다. 자식도 처음값인 a를 읽게 된다.
1번 케이스. openfork.c
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
int main(void) {
char c = '!';
int myfd;
if ((myfd = open("my.dat", O_RDONLY)) == -1) {
perror("Failed to open file");
return 1;
}
if (fork() == -1) {
perror("Failed to fork");
return 1;
}
read(myfd, &c, 1);
printf("Process %ld got %c\n", (long)getpid(), c);
return 0;
}
2번 케이스 forkopen.c
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
int main(void) {
char c = '!';
int myfd;
if (fork() == -1) {
perror("Failed to fork");
return 1;
}
if ((myfd = open("my.dat", O_RDONLY)) == -1) {
perror("Failed to open file");
return 1;
}
read(myfd, &c, 1);
printf("Process %ld got %c\n", (long)getpid(), c);
return 0;
}
Line buffering example : terminal file 쓸경우 -> line buffering된다는 예제
terminal buffer인 경우 fully buffered 되지 않고 line buffered된다.
fp가 stdout인 경우, 줄바꿈 캐릭터 나올때까지 출력이 된다.
fileiofork.c
#include <stdio.h>
#include <unistd.h>
int main(void) {
printf("This is my output.");
fork();
return 0;
}
This is my output 2번 출력 -> 부모 프로세스로부터 한번, 자식프로세스로부터 한번. (부모 buffer fflush, 자식 buffer fflush된다.)
fileioforkline.c
#include <stdio.h>
#include <unistd.h>
int main(void) {
printf("This is my output.\n");
fork();
return 0;
}
This is my output 한번 출력
new line character만나서 출력되고 buffer비워지고, fork하면 자식프로세스는 buffer가 비어있는채로 받아서 return되어도 buffer안에 비울게 없어서 그냥 종료된다. fork되기전에 fflush가 되어버렸기 때문.
STDIN과 STDERR의 차이
bufferout.c
#include <stdio.h>
int main(void) {
fprintf(stdout, "a");
fprintf(stderr, "a has been written\n");
fprintf(stdout, "b");
fprintf(stderr, "b has been written\n");
fprintf(stdout, "\n");
return 0;
}
--> a (buffer), 화면에는 출력된 것이 아님.(buffer에 존재)
--> stderr로 되면 a has been written이 화면에 먼저 출력된다. (우선 순위 높다)
--> b(buffer)에 출력이 된다. (buffer에 존재)
--> b has been written이 화면에 먼저 출력된다.
--> stdout으로 \n -> 한 라인이 쓰여졌으므로 ab가 마지막으로 출력이 된다.
bufferinout.c
#include <stdio.h>
int main(void) {
int i;
fprintf(stdout, "a");
scanf("%d", &i);
fprintf(stderr, "a has been written\n");
fprintf(stdout, "b");
fprintf(stderr, "b has been written\n");
fprintf(stdout, "\n");
return 0;
}
a라는 것이 먼저 출력되고 scanf로 입력 받고, a has been written, b has been written, b 차례로 출력된다.
버퍼안에 먼저 a가 들어간다. scanf의 동작자체가 input받기전에 버퍼를 비우는 작업부터 한다. 그래서 a가 먼저 출력된다. 입력을 하고 난 다음에는 위와 동일하다.
Filters and redirection
Filtering은 input이 있을때 정제가 되어서 특정조건에 맞는것만 output으로 내보내는 작업을 한다. 보통은 standard output으로 출력하는데 중간에 transformation과정을 거친다.
filter 명령어들 : head, tail, more, sort, grep, awk....
head와 tail은 파일의 내용을 출력해주는 명령. head는 처음, tail은 파일의 내용을 끝에. more명령어는 처음에 한페이지씩 출력. sort명령은 sorting해주는 명령어 string들을 알파벳 순서대로 sort. grep은 키워드를 가지고 있는 파일을 검색해줌. cat은 가장 간단한 명령의 filter. input으로 파일의 내용이 들어오고 파일 내용 그대로 출력. 사실상 0 transformation. 하나도 filtering 안하는 filter.
Redirection : 방향을 바꾼다. terminal 상에서 redirection사용해서 바꿀 수 있다.
dup2()는 fildes2의 file descripotr table가 open되어 있으면 닫고, fildes의 entry를 fildes2로 복사한다.
#include<unistd.h>
int dup2(int fildes,int fildes2);
output redirection > : > 왼쪽의 명령어의 결과의 출력결과를 바꾼다. > 오른쪽에 지정한 파일로 왼쪽 명령어의 결과가 출력되는 곳이 바뀐다.
예를 들어 ls는 그냥 출력. ls > temp.txt 하면 화면에 안나오고 temp.txt로 출력방향이 바뀌게 된 것이다.
input redirection < : 키보드로부터 입력 받아서 하는데, < 오른쪽에 파일 지정해서 왼쪽의 명령어로 넘겨준다. standardinput말고 다른 파일로 input 받을 수 있다.
예를 들어 sort <temp.txt 하면 키보드로 받은것 말고 temp.txt.를 sort해준다.
내부를 들여다 보자. filedescriptor table을 사용한다.
output redirection. ls를 수행한 결과를 temp.txt로 보내는 예시. fdt는 화면에 출력하기 위해 standard output인 1번을 통해 내용을 출력하는데 output redirection을 사용하면 temp.txt를 오픈한다. 그래서 fdt에 entry하나 추가된다. fdt에서 entry값이 temp.txt로 가는 entry가 복사가 된다. 그다음에 이 process STDOUT_FILENO(1) write함수를 써서 쓰게 되면 1번 index가 수정이 되어서 temp.txt로 간다. fdt 안의 entry안의 내용이 redirection하면 수정이 된다.
input redirection도 동일.
filedescriptor를 복사해주는 systmecall함수도 있다. -> 자주 사용은 x.
int dup2(int fildes, int fildes2); --> 이 함수의 역할은 fildes안에 entry값을 복사해주는 역할을 하는 역할을 한다.
소스파일 descriptor와 target파일 descriptor 지정가능. 가장 낮은 파일 값에 close를 먼저 하고 entry fildes를 fildes2로 복사해준다. 화면으로 출력되는 것을 my.file로 redirection되서 옮겨준다. dup2함수로 바꿔줌.
redirect.c
#include <fcntl.h>
#include <stdio.h>
#include <sys/stat.h>
#include <unistd.h>
#include "restart.h"
#define CREATE_FLAGS (O_WRONLY | O_CREAT | O_APPEND)
#define CREATE_MODE (S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH)
int main(void) {
int fd;
fd = open("my.file", CREATE_FLAGS, CREATE_MODE);
if (fd == -1) {
perror("Failed to open my.file");
return 1;
}
if (dup2(fd, STDOUT_FILENO) == -1) {
perror("Failed to redirect standard output");
return 1;
}
if (r_close(fd) == -1) {
perror("Failed to close the file");
return 1;
}
if (write(STDOUT_FILENO, "OK", 2) == -1) {
perror("Failed in writing to file");
return 1;
}
return 0;
}
my.file을 open하고 accessmode를 주었다, 권한정보는 define되어 있다.
dup2를 호출해서 fd를 STDOUT_FILENO를 1의 entry로 복사를 하겠다. 1이 가리키는 파일은 stdout인데 1은 이제 3과 똑같은 my.file을 가리키게 된 것이다.
fd를 close하면 fdt의 entry는 삭제된다. 마지막 3번째 entry가 삭제된다. fd를 close해도 sft는 count만 줄어듬. (2->1)
my.file은 계속 open된 상태. STDOUT에 "ok"를 wrtie 한다. my.file에 append되어서 출력이 된다. (STDOUT_FILENO에는 아까 복사된 fd의 entry값이 있기 때문이다)