https://www.acmicpc.net/problem/7432
7432번: 디스크 트리
갑자기 맥북이 상근이의 손에서 떨어졌고, 화면이 켜지지 않았다. AS센터에 문의해보니 수리비가 97만원이 나왔고, 상근이는 큰 혼란에 빠졌다. 돈도 중요하지만, 상근이는 그 속에 들어있는 파
www.acmicpc.net
[풀이]
2가지 개념 : Trie와 DFS에 대한 개념에 대한 이해가 필요하다.
Trie 개념 : (link 첨부)
먼저 Node를 class로 만든다. Node는 key, data, children(자식)을 필드변수로 가지고 있다.
Trie는 insert와 search함수를 가진다.
insert함수는 parameter로 path를 받는다. 이는 나중에 입력받은 값을 list형태로 넣어주기 위함이다.
(예 : ['WINNT', 'SYSTEM32', 'CONFIG'] -> 이걸 path로 넣어준다)
여기서 path의 하나하나를 children에 넣어준다. 예를 들어 WINNT는 처음 넣는 것이니까 curr_node.children에 없으므로 curr_node.children['WINNT']에는 Node('WINNT')가 들어가게 된다. 그리고 현재 노드를 WINNT인 노드로 바꾸어 준다.
위의 방법을 Trie의 원리로 구현한 것이다.
남은 것은 dfs를 이용해서 하나씩 출력만 하면 된다.
사전 순으로 출력을 해야 하므로 sorted(trie.head.children)을 해준다. 이는 제일 첫번째 level 0의 children들이다.
dfe에서는 node.key를 level만큼 띄워서 출력해주고, node의 children을 재귀문을 통하여 출력해준다.
import sys
input = sys.stdin.readline
class Node:
def __init__(self, key, data=None):
self.key = key
self.data = data
self.children = {}
class Trie:
def __init__(self):
self.head = Node(None)
def insert(self, path):
curr_node = self.head
for file in path:
if file not in curr_node.children:
curr_node.children[file] = Node(file)
curr_node = curr_node.children[file]
def dfs_node(node, depth):
print(' '*depth, node.key, sep='')
for child in sorted(node.children):
dfs_node(node.children[child], depth+1)
path_list = []
n = int(input())
trie = Trie()
for _ in range(n):
trie.insert(input().rstrip().split('\\'))
# print(trie.head.children['WINNT'].children)
for node in sorted(trie.head.children):
dfs_node(trie.head.children[node], 0)'알고리즘 > 알고리즘 문제' 카테고리의 다른 글
| [백준 - 1062] [파이썬] 가르침 (0) | 2023.01.08 |
|---|---|
| [17609] [파이썬] 회문 (0) | 2023.01.08 |
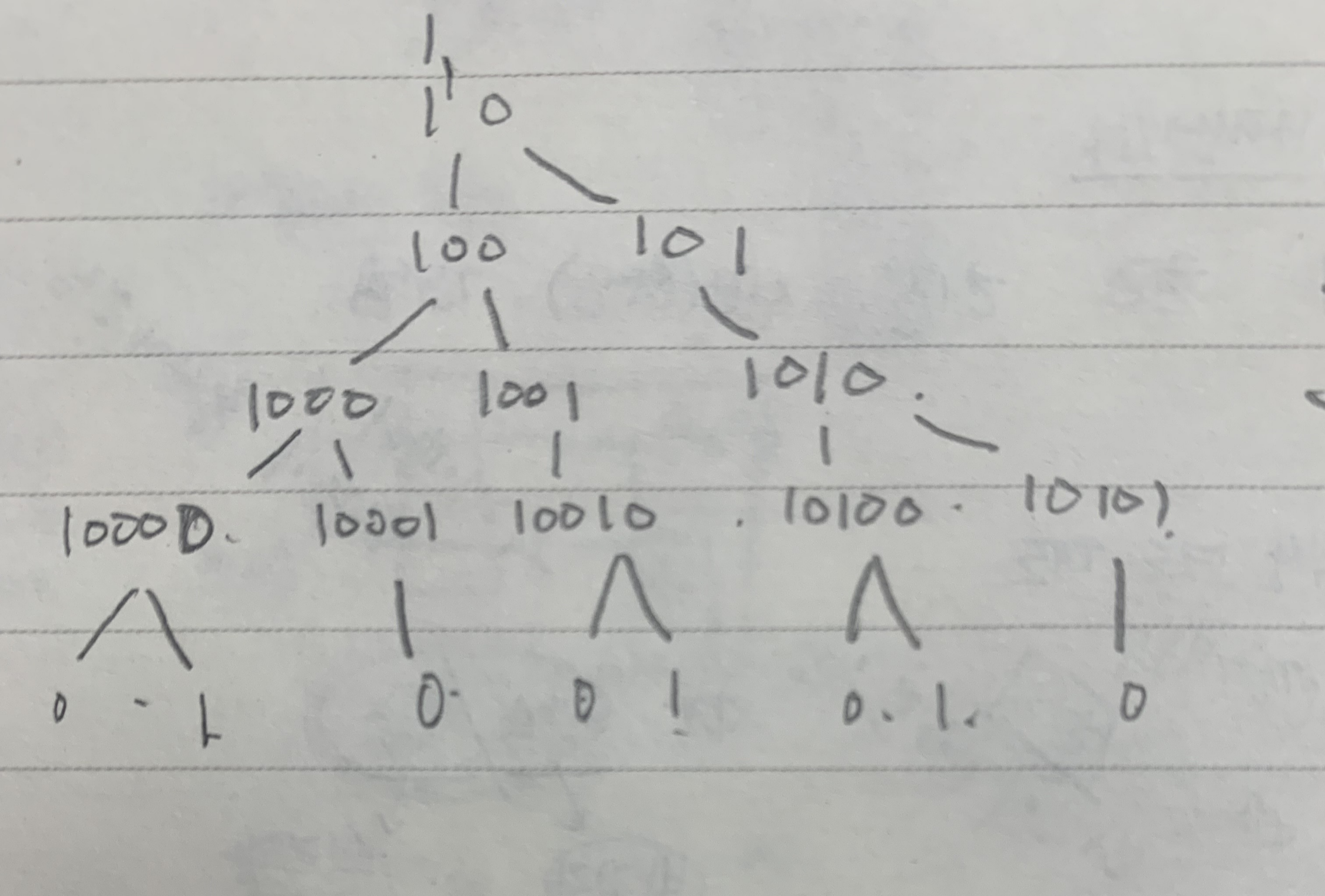
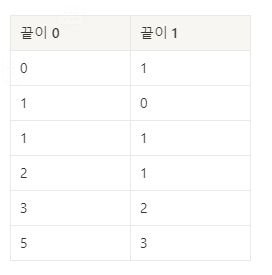
| [파이썬] [백준 - 2193번] 이친수(DP) (0) | 2022.07.11 |
| [백준] 13413 파이썬 (0) | 2022.06.21 |
| [파이썬] [2346 - 풍선 터트리기] (0) | 2022.01.08 |